Journal of South China University of Technology(Natural Science Edition) ›› 2024, Vol. 52 ›› Issue (10): 41-50.doi: 10.12141/j.issn.1000-565X.230673
• Computer Science & Technology • Previous Articles Next Articles
Semantic-Visual Consistency Constraint Network for Zero-Shot Image Semantic Segmentation
CHEN Qiong( ), FENG Yuan, LI Zhiqun, YANG Yong
), FENG Yuan, LI Zhiqun, YANG Yong
- School of Computer Science and Engineering,South China University of Technology,Guangzhou 510006,Guangdong,China
-
Received:2023-10-29Online:2024-10-25Published:2023-12-27 -
About author:陈琼(1966—),女,博士,副教授,主要从事机器学习、不平衡分类、图像分类与分割、深度强化学习研究。E-mail: csqchen@scut.edu.cn -
Supported by:the National Natural Science Foundation of China(62176095)
CLC Number:
Cite this article
CHEN Qiong, FENG Yuan, LI Zhiqun, et al. Semantic-Visual Consistency Constraint Network for Zero-Shot Image Semantic Segmentation[J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(10): 41-50.
share this article

Fig.1
Schematic diagram of semantic feature distribution and visual feature distribution"
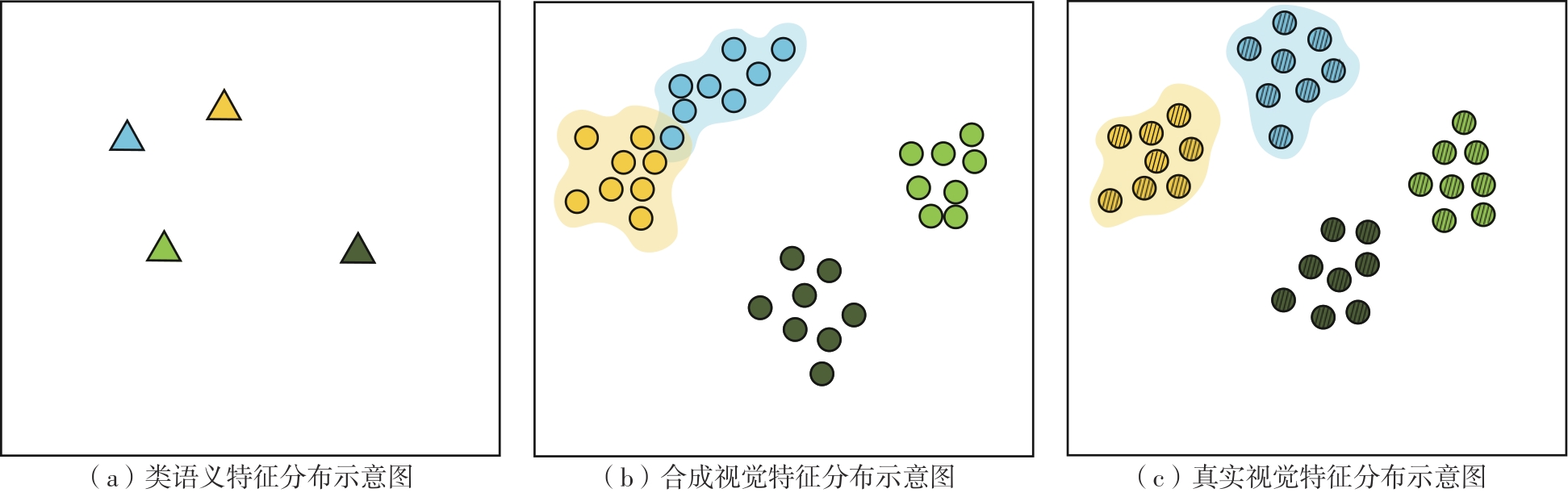
Fig.2
Schematic diagram of semantic-visual consistency constraint network"
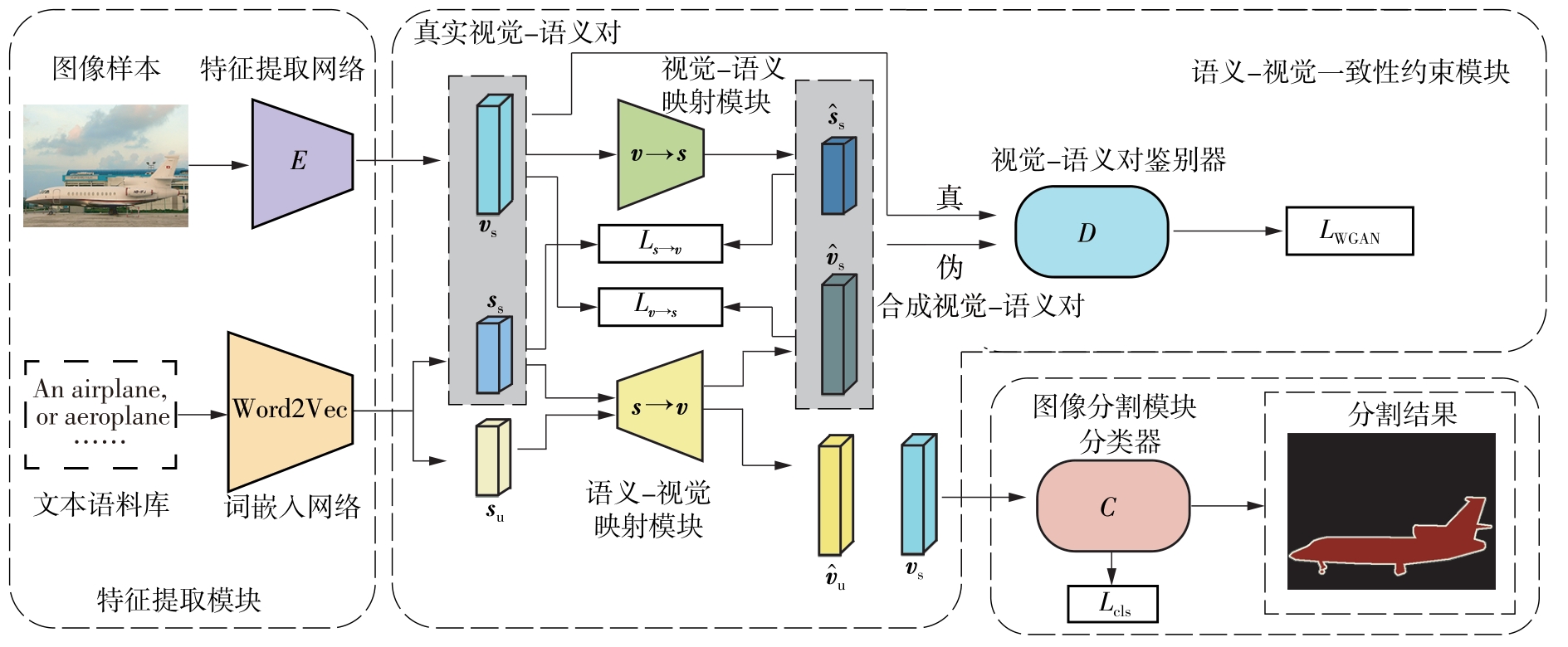
Table 1
Partition details of experimental datasets"
| 数据集 | 类别数 | 样本数 | |
|---|---|---|---|
| 训练集 | 验证集 | ||
| PASCAL-VOC | 20 | 1 464 | 1 449 |
| PASCAL-Context | 59 | 4 998 | 5 105 |
Table 2
Comparison of zero-shot segmentation performance on PASCAL-VOC dataset"
| K | 模型 | RHIoU | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | Baseline | 92.1 | 79.8 | 68.1 | 11.3 | 10.5 | 3.2 | 89.7 | 73.4 | 44.1 | 6.1 |
| SPNet | 70.8 | 31.2 | 67.3 | 43.5 | |||||||
| ZS3Net | 93.4 | 81.8 | 71.3 | 56.7 | 57.8 | 32.1 | 92.6 | 79.5 | 67.6 | 44.2 | |
| SVCCNet | 94.2 | 94.2 | 72.0 | 56.8 | 58.1 | 34.6 | 93.1 | 80.3 | 68.3 | 46.7 | |
| 4 | Baseline | 89.9 | 72.6 | 64.3 | 10.3 | 10.1 | 2.9 | 86.3 | 62.1 | 38.9 | 5.5 |
| SPNet | 67.1 | 21.8 | 58.6 | 32.9 | |||||||
| ZS3Net | 92.0 | 78.3 | 66.4 | 43.1 | 45.7 | 25.0 | 89.8 | 72.1 | 58.2 | 36.3 | |
| SVCCNet | 92.3 | 78.1 | 68.6 | 47.2 | 50.1 | 25.9 | 90.3 | 72.9 | 60.3 | 37.6 | |
| 6 | Baseline | 79.5 | 45.1 | 39.8 | 8.3 | 8.4 | 2.7 | 71.1 | 38.4 | 33.4 | 5.1 |
| SPNet | 48.2 | 20.1 | 41.3 | 28.4 | |||||||
| ZS3Net | 85.5 | 52.1 | 47.3 | 63.5 | 55.8 | 23.1 | 84.2 | 54.6 | 40.7 | 31.0 | |
| SVCCNet | 86.8 | 54.2 | 49.4 | 66.2 | 59.1 | 24.2 | 85.2 | 55.6 | 42.2 | 32.5 | |
| 8 | Baseline | 75.8 | 41.3 | 35.7 | 6.9 | 5.7 | 2.0 | 68.3 | 34.7 | 24.3 | 3.8 |
| SPNet | 30.2 | 19.9 | 26.9 | 24.0 | |||||||
| ZS3Net | 81.6 | 31.6 | 29.2 | 68.7 | 62.3 | 22.9 | 80.3 | 43.3 | 26.8 | 25.7 | |
| SVCCNet | 82.0 | 32.5 | 29.8 | 68.4 | 61.2 | 23.5 | 80.7 | 43.5 | 27.3 | 26.3 |
Table 3
Comparison of zero-shot segmentation performance on PASCAL-Context dataset"
| K | 模型 | RHIoU | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | Baseline | 70.2 | 47.7 | 35.8 | 9.5 | 10.2 | 2.7 | 66.2 | 43.9 | 33.1 | 5.0 |
| SPNet | 38.2 | 16.7 | 37.5 | 23.2 | |||||||
| ZS3Net | 71.6 | 52.4 | 41.6 | 49.3 | 46.2 | 21.6 | 71.2 | 52.2 | 41.0 | 28.4 | |
| SVCCNet | 73.0 | 52.7 | 42.6 | 54.8 | 52.3 | 23.1 | 72.6 | 54.2 | 42.6 | 29.9 | |
| 4 | Baseline | 66.2 | 37.9 | 33.4 | 9.0 | 84.0 | 2.5 | 62.8 | 34.6 | 30.7 | 4.7 |
| SPNet | 36.3 | 18.1 | 35.1 | 24.2 | |||||||
| ZS3Net | 68.4 | 46.1 | 37.2 | 58.4 | 53.3 | 24.9 | 67.8 | 46.6 | 36.4 | 29.8 | |
| SVCCNet | 70.5 | 46.9 | 39.1 | 60.2 | 54.8 | 25.9 | 68.5 | 47.7 | 37.9 | 31.2 | |
| 6 | Baseline | 60.8 | 36.7 | 31.9 | 8.8 | 8.0 | 2.1 | 55.9 | 33.5 | 28.8 | 3.9 |
| SPNet | 31.9 | 19.9 | 30.7 | 24.5 | |||||||
| ZS3Net | 63.3 | 38.0 | 32.1 | 63.6 | 55.8 | 20.7 | 63.3 | 39.8 | 30.9 | 25.2 | |
| SVCCNet | 64.2 | 40.3 | 33.8 | 64.8 | 56.9 | 21.5 | 63.8 | 39.7 | 31.3 | 26.3 | |
| 8 | Baseline | 54.1 | 24.7 | 22.0 | 7.3 | 6.8 | 1.7 | 49.1 | 20.9 | 19.2 | 3.2 |
| SPNet | 25.6 | 14.3 | 20.5 | 18.3 | |||||||
| ZS3Net | 51.4 | 23.9 | 20.9 | 68.2 | 59.9 | 16.0 | 53.1 | 28.7 | 20.3 | 18.1 | |
| SVCCNet | 52.3 | 25.2 | 21.8 | 68.9 | 59.6 | 16.5 | 54.3 | 29.8 | 21.6 | 18.8 |
Table 4
Ablation results on PASCAL-VOC dataset"
| K | Ls→v | Lv→s | LWGAN | RHIoU | ||
|---|---|---|---|---|---|---|
| 2 | 68.1 | 3.2 | 6.1 | |||
| √ | 69.2 | 31.3 | 43.1 | |||
| √ | √ | 71.5 | 32.8 | 45.0 | ||
| √ | √ | √ | 72.0 | 34.6 | 46.7 | |
| 4 | 64.3 | 2.9 | 5.5 | |||
| √ | 65.7 | 23.1 | 34.2 | |||
| √ | √ | 67.4 | 24.6 | 36.0 | ||
| √ | √ | √ | 68.6 | 25.9 | 37.6 | |
| 6 | 39.8 | 39.8 | 5.1 | |||
| √ | 45.8 | 45.8 | 29.4 | |||
| √ | √ | 47.3 | 47.3 | 30.9 | ||
| √ | √ | √ | 49.4 | 49.4 | 32.5 | |
| 8 | 35.7 | 2.0 | 3.8 | |||
| √ | 24.5 | 20.8 | 22.5 | |||
| √ | √ | 27.1 | 22.6 | 24.6 | ||
| √ | √ | √ | 29.8 | 23.5 | 26.3 |
Table 5
Ablation results on PASCAL-Context dataset"
| K | Ls→v | Lv→s | LWGAN | RHIoU | ||
|---|---|---|---|---|---|---|
| 2 | 35.8 | 2.7 | 5.0 | |||
| √ | 39.2 | 21.2 | 27.5 | |||
| √ | √ | 41.6 | 22.4 | 29.1 | ||
| √ | √ | √ | 42.6 | 23.1 | 29.9 | |
| 4 | 33.4 | 2.5 | 4.7 | |||
| √ | 36.2 | 22.6 | 27.8 | |||
| √ | √ | 37.5 | 24.7 | 29.8 | ||
| √ | √ | √ | 39.1 | 25.9 | 31.2 | |
| 6 | 31.9 | 2.1 | 3.9 | |||
| √ | 32.3 | 20.7 | 25.2 | |||
| √ | √ | 32.9 | 21.1 | 25.7 | ||
| √ | √ | √ | 33.8 | 21.5 | 26.3 | |
| 8 | 22.0 | 1.7 | 3.2 | |||
| √ | 20.4 | 15.6 | 17.7 | |||
| √ | √ | 21.2 | 16.1 | 18.3 | ||
| √ | √ | √ | 21.8 | 16.5 | 18.8 |

Fig. 3
Comparison of segmentation results between two models"


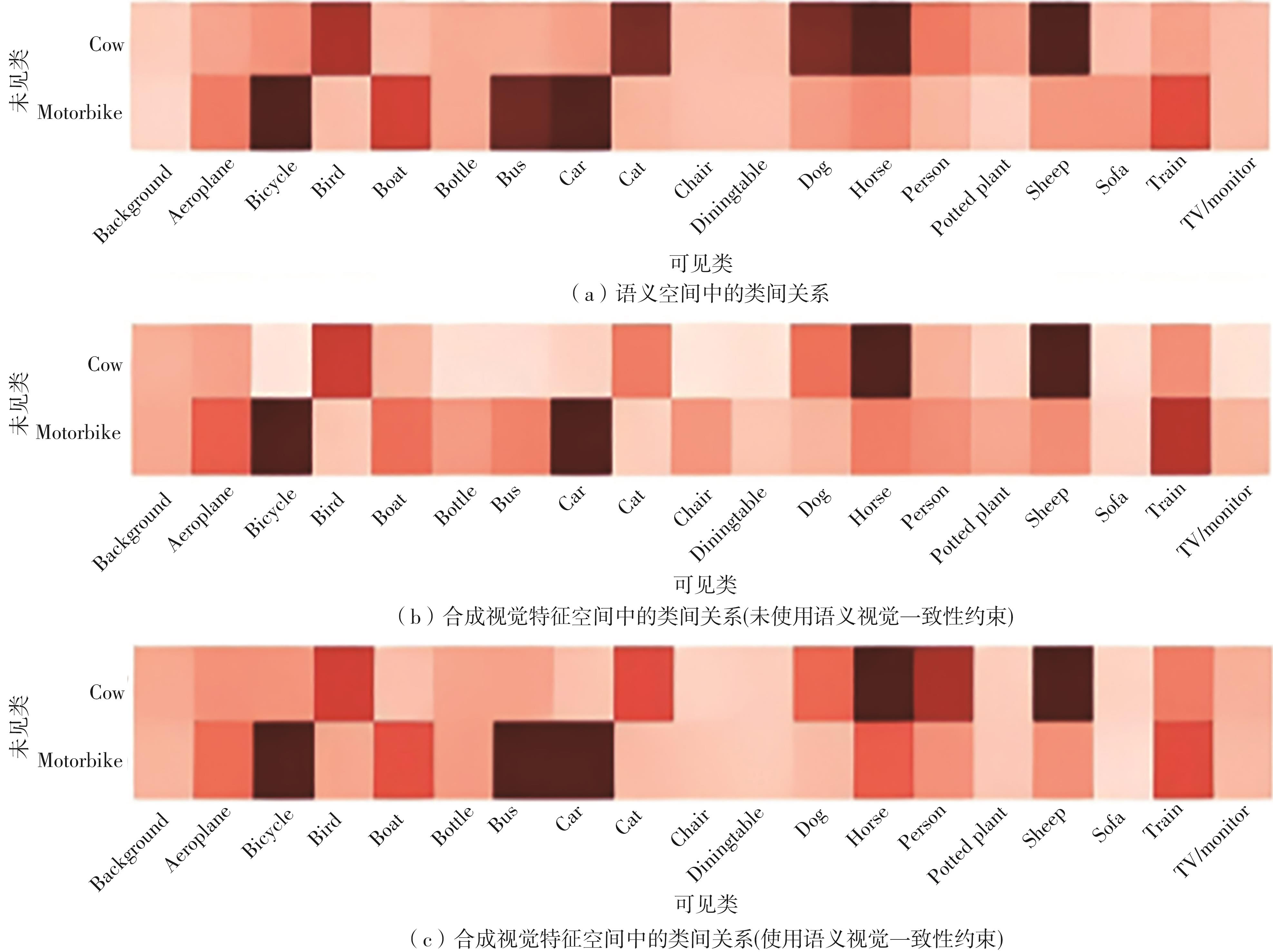
Fig.4
Illustration of inter-class relationships"
| 1 | RONNEBERGER O, FISCHER P, BROX T .U-Net:convolutional networks for biomedical image segmentation[C]∥ Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention.Munich:Springer,2015:234-241. |
| 2 | ZHAO H S, SHI J P, QI X J,et al .Pyramid scene parsing network[C]∥ Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu:IEEE,2017:2881-2890. |
| 3 | BUCHER M, VU T H, CORD M,et al .Zero-shot semantic segmentation[C]∥ Proceedings of the 32nd International Conference on Neural Information Processing Systems.Vancouver:Curran Associates Inc.,2019:468-479. |
| 4 | XIAN Y Q, CHOUDHURY S, HE Y,et al .Semantic projection network for zero-and few-label semantic segmentation[C]∥ Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach:IEEE,2019:8256-8265. |
| 5 | MIKOLOV T, SUTSKEVER I, CHEN K,et al .Distributed representations of words and phrases and their compositionality[C]∥ Proceedings of the 26th International Conference on Neural Information Processing Systems.Red Hook:Curran Associates Inc.,2013:3111-3119. |
| 6 | LV F M, LIU H Y, WANG Y C,et al .Learning unbiased zero-shot semantic segmentation networks via transductive transfer[J].IEEE Signal Processing Letters,2020,27:1640-1644. |
| 7 | YANG S, SHI Y M, WANG Y W,et al .Attribute driven zero-shot classification and segmentation[C]∥ Proceedings of 2018 IEEE International Conference on Multimedia & Expo Workshops.San Diego:IEEE,2018:8551489/1-6. |
| 8 | KATO N, YAMASAKI T, AIZAWA K .Zero-shot semantic segmentation via variational mapping[C]∥ Proceedings of 2019 IEEE/CVF International Conference on Computer Vision Workshops.Seoul:IEEE,2019:1363-1370. |
| 9 | GU Z X, ZHOU S Y, NIU L,et al .Context-aware feature generation for zero-shot semantic segmentation[C]∥ Proceedings of the 28th ACM International Conference on Multimedia.Seattle:ACM,2020:1921-1929. |
| 10 | BAEK D,OH Y,HAM B .Exploiting a joint embedding space for generalized zero-shot semantic segmentation[C]∥ Proceedings of 2021 IEEE/CVF International Conference on Computer Vision.Montreal:IEEE,2021:9536-9545. |
| 11 | DING J, XUE N, XIA G S,et al .Decoupling zero-shot semantic segmentation[C]∥ Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition.New Orleans:IEEE,2022:11583-11592. |
| 12 | LI B Y, WEINBERGER K Q, BELONGIE S,et al .Language-driven semantic segmentation[EB/OL].(2022-01-10)[2023-07-17].. |
| 13 | RADFORD A, KIM J W, HALLACY C,et al .Learning transferable visual models from natural language supervision[C]∥ Proceedings of the 38th International Conference on Machine Learning.Vienna:ML Research Press,2021:8748-8763. |
| 14 | XIE G S, ZHANG Z, LIU G S,et al .Generalized zero-shot learning with multiple graph adaptive generative networks[J].IEEE Transactions on Neural Networks and Learning Systems,2022,33(7):2903-2915. |
| 15 | CHEN L C, ZHU Y K, PAPANDREOU G,et al .Encoder-decoder with atrous separable convolution for semantic image segmentation[C]∥ Proceedings of the 15th European Conference on Computer Vision.Munich:Springer,2018:833-851. |
| 16 | BAU D, ZHU J Y, WULFF J,et al .Seeing what a GAN cannot generate[C]∥ Proceedings of 2019 IEEE/CVF International Conference on Computer Vision.Seoul:IEEE,2019:4501-4510. |
| 17 | EVERINGHAM M, ESLAMI S M A, VAN GOOL L,et al .The PASCAL visual object classes challenge:a retrospective[J].International Journal of Computer Vision,2015,111:98-136. |
| 18 | MOTTAGHI R, CHEN X J, LIU X B,et al .The role of context for object detection and semantic segmentation in the wild[C]∥ Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:891-898. |
| 19 | CACHEUX Y L, BORGNE H L, CRUCIANU M .Modeling inter and intra-class relations in the triplet loss for zero-shot learning[C]∥ Proceedings of 2019 IEEE/CVF International Conference on Computer Vision.Long Beach:IEEE,2019:10332-10341. |
| 20 | FU Y, HOSPEDALES T M, XIANG T,et al .Transductive multi-view embedding for zero-shot recognition and annotation[C]∥ Proceedings of the 13th European Conference on Computer Vision.Zurich:Springer,2014:584-599. |
| [1] | DU Qiliang, WANG Yimin, TIAN Lianfang. Attention Module Based on Feature Similarity and Feature Normalization [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(7): 62-71. |
| [2] | HU Xizhi, CUI Bofei, WANG Qin, et al. Visual SLAM Algorithm Based on Memory Parking Scene [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(6): 1-11. |
| [3] | LIU Hao, YUAN Hui, CHEN Chen, GAO Wei. Point Cloud Geometry Coding Framework Based on Sampling [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(6): 148-156. |
| [4] | YANG Chunling, LIANG Ziwen. Feature-Domain Proximal High-Dimensional Gradient Descent Network for Image Compressed Sensing [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(3): 119-130. |
| [5] | ZHENG Juanyi, DONG Jiahao, ZHANG Qingjue, et al. Reconfigurable Intelligence Surface Channel Estimation Algorithm Based on RDN [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(3): 102-111. |
| [6] | ZHOU Lang, FAN Kun, QU Hua, et al. Forest Fire Recognition by Improved EfficientNet-E Model Based on ECA Attention Mechanism [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(2): 42-49. |
| [7] |
LIU Weipeng, LI Xu, REN Ziwen, et al.
Algorithm for Registration of Multiscale Residual Deformable Lung CT Images #br# [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(10): 135-145. |
| [8] | HU Guanghua, TU Qianxi. Surface Defect Detection Method for Industrial Products Based on Photometric Stereo and Dual Stream Feature Fusion Network [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(10): 112-123. |
| [9] | LI Fang, GUO Weisen, ZHANG Ping, et al.. Prediction Technique for Remaining Useful Life of Bearing Based on Spatial-Temporal Dual Cell State [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(9): 69-81. |
| [10] | SU Jindian, YU Shanshan, HONG Xiaobin. A Self-Supervised Pre-Training Method for Chinese Spelling Correction [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(9): 90-98. |
| [11] | LI Jiachun, LI Bowen, LIN Weiwei. AdfNet: An Adaptive Deep Forgery Detection Network Based on Diverse Features [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(9): 82-89. |
| [12] | GUO Enqiang, FU Xinsha. Dropped Object Detection Method Based on Feature Similarity Learning [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(6): 30-41. |
| [13] | ZHAO Jiandong, JIAO Lanxin, ZHAO Zhimin, et al. A Car-Following Model Driven by Combination of Theory and Data Considering Effects of Lane Change of Side Cars [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(6): 10-19. |
| [14] | YE Feng, CHEN Biao, LAI Yizong. Contrastive Knowledge Distillation Method Based on Feature Space Embedding [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(5): 13-23. |
| [15] | ZHAO Rongchao, WU Baili, CHEN Zhuyun, et al. Graph Neural Network for Fault Diagnosis with Multi-Scale Time-Spatial Information Fusion Mechanism [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(12): 42-52. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||