Journal of South China University of Technology(Natural Science Edition) ›› 2024, Vol. 52 ›› Issue (10): 31-40.doi: 10.12141/j.issn.1000-565X.230503
Special Issue: 2024年计算机科学与技术
• Computer Science & Technology • Previous Articles Next Articles
Multi-Task Assisted Driving Policy Learning Method for Autonomous Driving
LUO Yutao( ), XUE Zhicheng
), XUE Zhicheng
- School of Mechanical and Automotive Engineering/ Guangdong Provincial Key Laboratory of Automotive Engineering,South China University of Technology,Guangzhou 510640,Guangdong,China
-
Received:2023-08-01Online:2024-10-25Published:2024-01-31 -
Supported by:the Special Fund for High-Quality Development of the Manufacturing Industry of the Ministry of Industry and Information Technology(R-ZH-023-QT-001-20221009-001)
CLC Number:
Cite this article
LUO Yutao, XUE Zhicheng. Multi-Task Assisted Driving Policy Learning Method for Autonomous Driving[J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(10): 31-40.
share this article
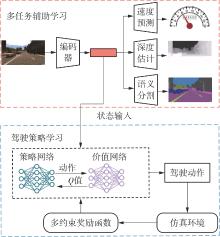
Fig.1
Overall architecture of MA-DPL algorithm"
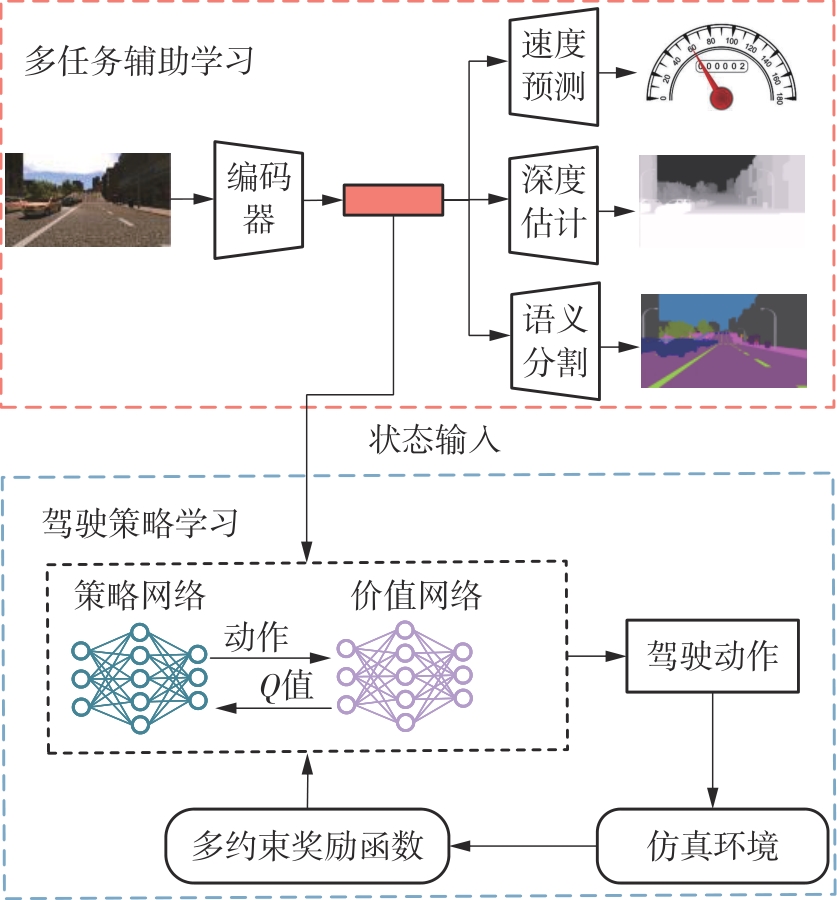
Fig.2
Network structure of encoder"
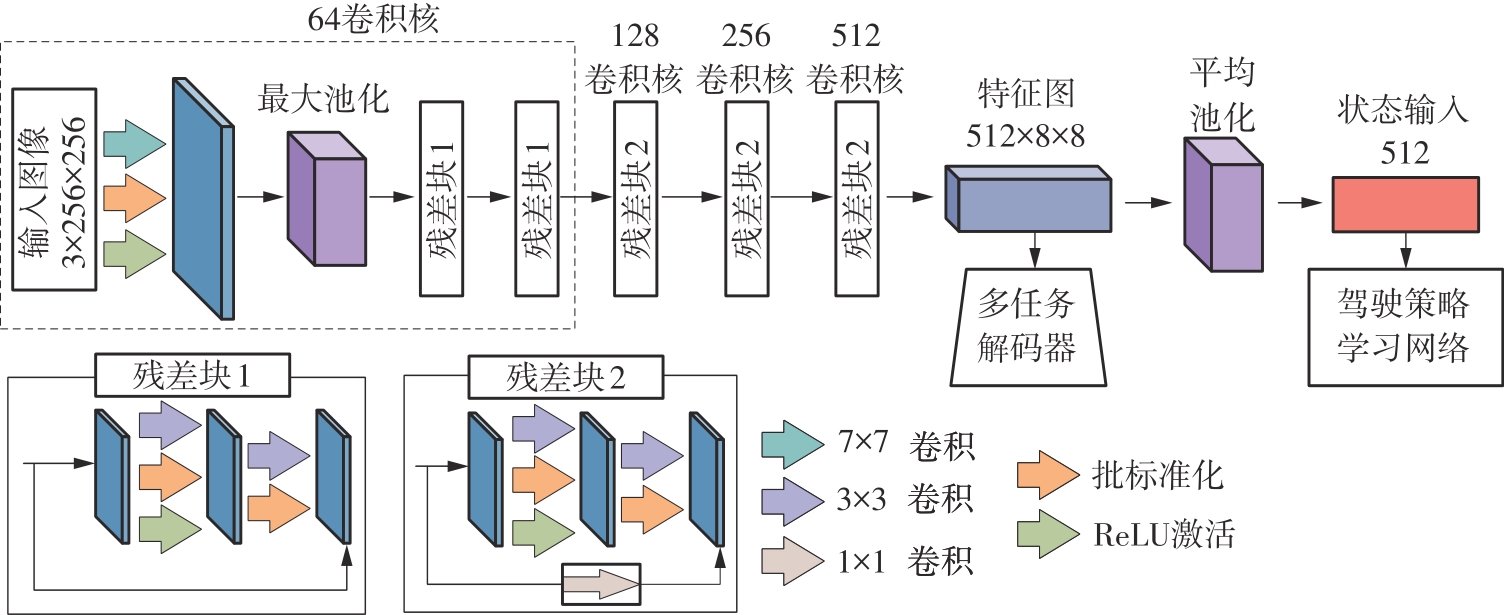
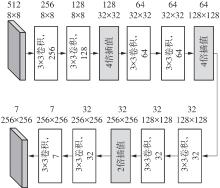
Fig.3
Network structure of semantic segmentation decoder"
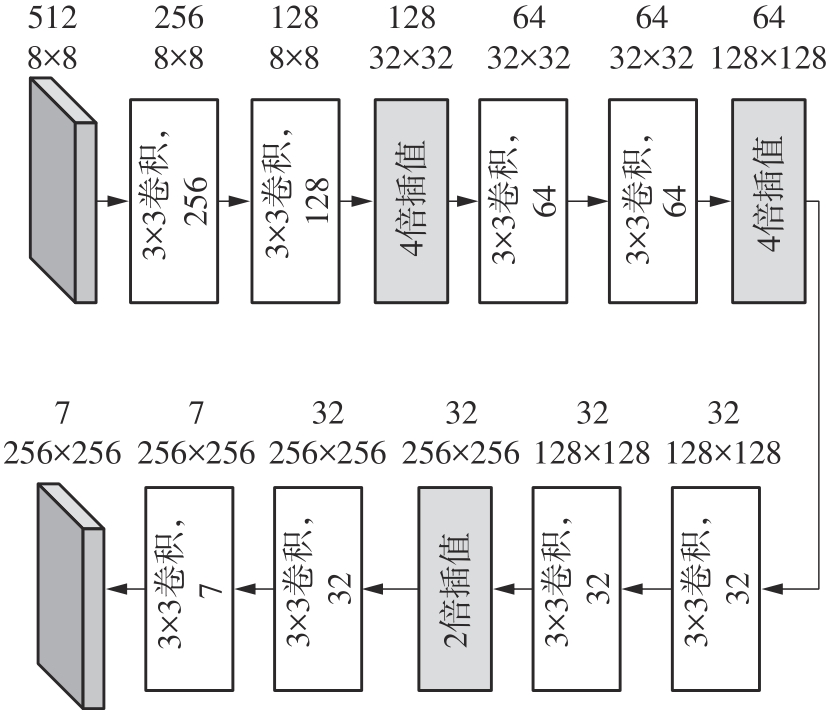
Fig.4
Markov decision model for autonomous driving problem"
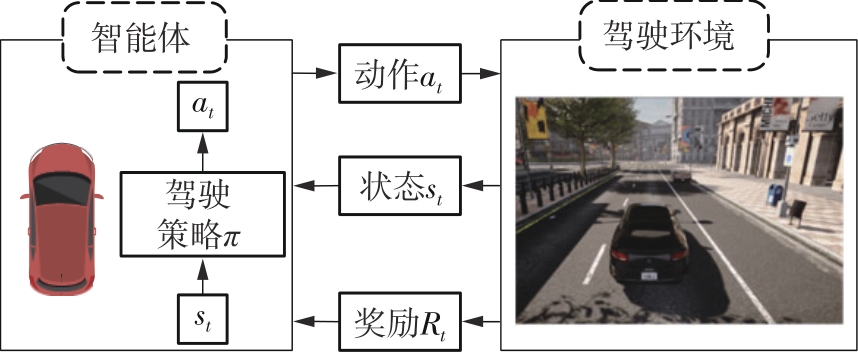
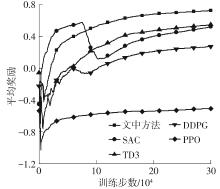
Fig.5
Comparison of training results among several methods"
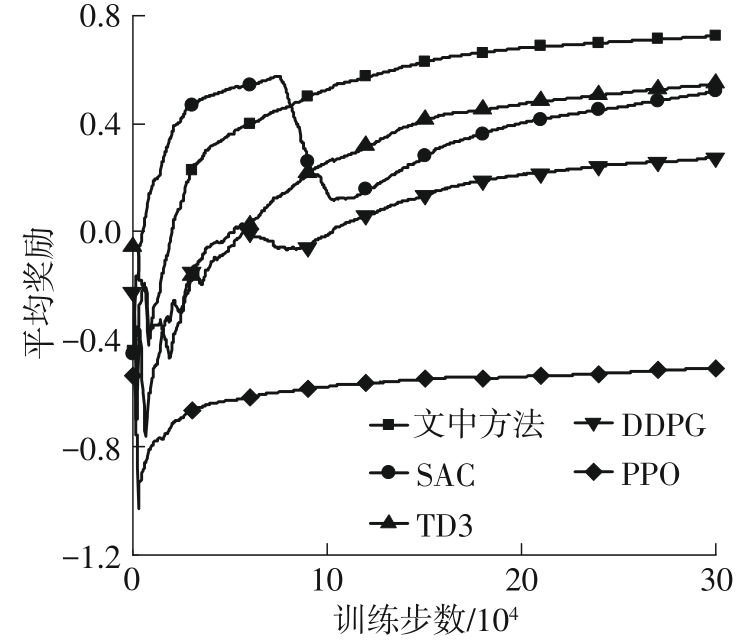
Fig.6
Comparison of training results for different auxiliary tasks"
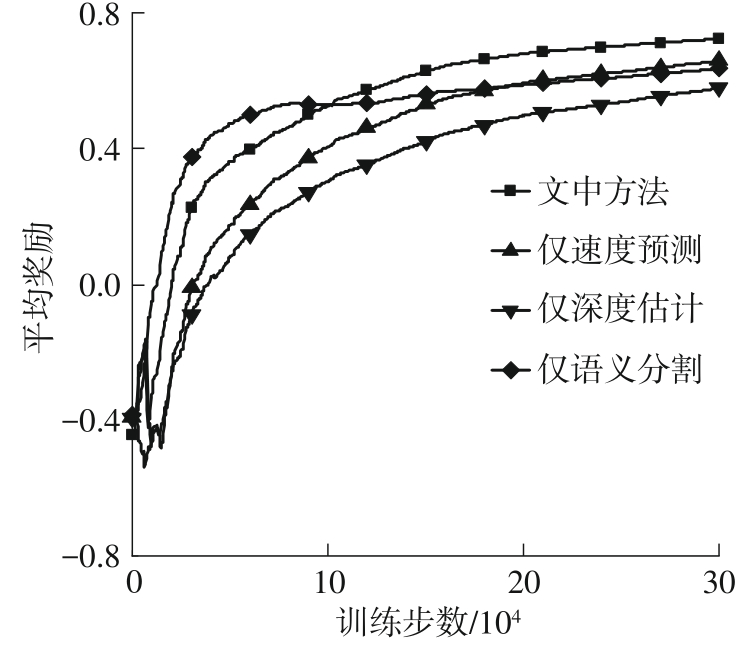

Fig.7
Qualitative test results of the proposed method"


Fig.8
Scenarios for quantitative test"

Table 2
Quantitative test results under two scenarios"
| 场景 | 模型 | 成功率/% | 驾驶分数 | ||||
|---|---|---|---|---|---|---|---|
| 车流密度 为10辆 | 车流密度 为50辆 | 车流密度 为100辆 | 车流密度 为10辆 | 车流密度 为50辆 | 车流密度 为100辆 | ||
| 环岛场景 | MA-DPL | 100 | 99 | 87 | 100.00 | 99.13 | 88.31 |
| SAC | 93 | 80 | 75 | 93.79 | 81.51 | 77.03 | |
| TD3 | 96 | 89 | 70 | 96.39 | 90.02 | 72.54 | |
| DDPG | 98 | 80 | 73 | 98.11 | 81.97 | 75.18 | |
| 五向路口场景 | MA-DPL | 98 | 96 | 84 | 98.34 | 96.44 | 85.31 |
| SAC | 96 | 69 | 43 | 96.29 | 71.85 | 47.35 | |
| TD3 | 93 | 85 | 41 | 93.71 | 86.26 | 45.21 | |
| DDPG | 98 | 72 | 42 | 98.12 | 74.45 | 46.38 | |

Fig.9
Scenarios for generalization test"

Table 3
Generalization test results of several methods"
| 方法 | 成功率/% | 驾驶分数 | ||||
|---|---|---|---|---|---|---|
| 车流密度为10辆 | 车流密度为50辆 | 车流密度为100辆 | 车流密度为10辆 | 车流密度为50辆 | 车流密度为100辆 | |
| MA-DPL | 97 | 65 | 56 | 97.74 | 73.76 | 66.07 |
| SAC[ | 81 | 60 | 37 | 86.31 | 70.21 | 51.74 |
| TD3[ | 82 | 60 | 34 | 86.61 | 70.07 | 49.74 |
| DDPG[ | 85 | 49 | 36 | 88.79 | 61.29 | 51.47 |
Table 4
Effect of reward functions on driving score"
| 奖励函数权重 | 驾驶分数 |
|---|---|
| ωi (i=1,2,…,7)≠0 | 66.1 |
| ω1=0(去除Rv) | 0.0 |
| ω2=0(去除Rd) | 46.8 |
| ω3=0(去除Ra) | 59.7 |
| ω4=0(去除Rc) | 55.5 |
| ω5=0(去除Ro) | 47.5 |
| ω6=0(去除Rl) | 57.3 |
| ω7=0(去除Rs) | 51.6 |
| 1 | ELALLID B B, BENAMAR N, HAFID A S,et al .A comprehensive survey on the application of deep and reinforcement learning approaches in autonomous driving[J].Journal of King Saud University-Computer and Information Sciences,2022,34(9):7366-7390. |
| 2 | 林泓熠,刘洋,李深,等 .车路协同系统关键技术研究进展[J].华南理工大学学报(自然科学版),2023,51(10):46-67. |
| LIN Hongyi, LIU Yang, LI Shen,et al .Research progress on key technologies in the cooperative vehicle infrastructure system[J].Journal of South China University of Technology (Natural Science Edition),2023,51(10):46-67. | |
| 3 | HEJASE B, YURTSEVER E, HAN T,et al .Dynamic and interpretable state representation for deep reinforcement learning in automated driving[J].IFAC-PapersOnLine,2022,55(24):129-134. |
| 4 | HUANG C, ZHANG R, OUYANG M,et al .Deductive reinforcement learning for visual autonomous urban driving navigation[J].IEEE Transactions on Neural Networks and Learning Systems,2021,32(12):5379-5391. |
| 5 | ZHU M, WANG X, WANG Y .Human-like autonomous car-following model with deep reinforcement learning[J].Transportation Research Part C:Emerging Technologies,2018,97:348-368. |
| 6 | KENDALL A, HAWKE J, JANZ D,et al .Learning to drive in a day[C]∥ Proceedings of 2019 International Conference on Robotics and Automation.Montreal:IEEE,2019:8248-8254. |
| 7 | DOSOVITSKIY A,ROS G, CODEVILLA F,et al .CARLA:an open urban driving simulator[C]∥ Proceedings of the 1st Conference on Robot Learning.New York:ML Research Press,2017:1-16. |
| 8 | SAXENA D M,BAE S, NAKHAEI A,et al .Driving in dense traffic with model-free reinforcement learning[C]∥ Proceedings of 2020 IEEE International Conference on Robotics and Automation.Paris:IEEE,2020:5385-5392. |
| 9 | 邓小豪,侯进,谭光鸿,等 .基于强化学习的多目标车辆跟随决策算法[J].控制与决策,2021,36(10):2497-2503. |
| DEND Xiaohao, HOU Jin, TAN Guanghong,et al .Multi-objective vehicle following decision algorithm based on reinforcement learning[J].Control and Decision,2021,36(10):2497-2503. | |
| 10 | TOROMANOFF M, WIRBEL E, MOUTARDE F .End-to-end model-free reinforcement learning for urban driving using implicit affordances[C]∥ Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle:IEEE,2020:7153-7162. |
| 11 | CAI P, WANG H, SUN Y,et al .DiGNet:learning scalable self-driving policies for generic traffic scenarios with graph neural networks[C]∥ Proceedings of 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems.Prague:IEEE,2021:8979-8984. |
| 12 | CHEN J, YUAN B, TOMIZUKA M .Model-free deep reinforcement learning for urban autonomous driving[C]∥ Proceedings of 2019 IEEE Intelligent Transportation Systems Conference.Auckland:IEEE,2019:2765-2771. |
| 13 | AGARWAL T, ARORA H, SCHNEIDER J .Learning urban driving policies using deep reinforcement learning[C]∥ Proceedings of 2021 IEEE International Intelligent Transportation Systems Conference.Indianapolis:IEEE,2021:607-614. |
| 14 | KARGAR E, KYRKI V .Increasing the efficiency of policy learning for autonomous vehicles by multi-task representation learning[J].IEEE Transactions on Intelligent Vehicles,2022,7(3):701-710. |
| 15 | ZHANG Z, LINIGER A, DAI D,et al .End-to-end urban driving by imitating a reinforcement learning coach[C]∥ Proceedings of 2021 IEEE/CVF International Conference on Computer Vision.Montreal:IEEE,2021:15222-15232. |
| 16 | HAN Y, YILMAZ A .Learning to drive using sparse imitation reinforcement learning[C]∥ Proceedings of 2022 the 26th International Conference on Pattern Recognition.Montreal:IEEE,2022:3736-3742. |
| 17 | CODEVILLA F, SANTANA E, LÓPEZ A M,et al .Exploring the limitations of behavior cloning for autonomous driving[C]∥ Proceedings of 2019 IEEE/CVF International Conference on Computer Vision.Seoul:IEEE,2019:9328-9337. |
| 18 | CHITTA K, PRAKASH A, JAEGER B,et al .Transfuser:imitation with transformer-based sensor fusion for autonomous driving[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2023,45(11):12878-12895. |
| 19 | CHITTA K, PRAKASH A, GEIGER A .NEAT:neural attention fields for end-to-end autonomous driving[C]∥ Proceedings of IEEE/CVF International Conference on Computer Vision.Montreal:IEEE,2021:15793-15803. |
| 20 | LILLICRAP T P, HUNT J J, PRITZEL A,et al .Continuous control with deep reinforcement learning [EB/OL].(2019-07-05)[2023-07-28].. |
| 21 | FUJIMOTO S, VAN HOOF H, MEGER D .Addressing function approximation error in actor-critic methods[C]∥ Proceedings of the 35th International Conference on Machine Learning.New York:ML Research Press,2018:1587-1596. |
| 22 | SCHULMAN J, WOLSKI F, DHARIWAL P,et al .Proximal policy optimization algorithms[EB/OL].(2017-08-28)[2023-07-28].. |
| 23 | HAARNOJA T, ZHOU A, ABBEEL P,et al .Soft actor-critic:off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]∥ Proceedings of the 35th International Conference on Machine Learning.New York:ML Research Press,2018:1861-1870. |
| [1] | CHEN Cuifeng, LIN Zhenhong, HUANG Chikun, et al. Review of Decision-Making Analysis for Transportation Energy Transition [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(1): 32-48. |
| [2] | ZHOU Xuan, MO Haohua, YAN Junwei. Investigating an Enhanced H-AC Algorithm-Based Strategy for Energy-Saving Optimization Control in Cold Source System [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(1): 21-31. |
| [3] | CHENG Xiaohua, WANG Zefu, ZENG Jun, et al. Distributed Energy Cluster Scheduling Method Based on EA-RL Algorithm [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(1): 1-9. |
| [4] | WANG Fujian, CHENG Huiling, MA Dongfang, et al. Reconstruction of Urban Vehicle Path Chain Based on Deep Inverse Reinforcement Learning [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(7): 120-128. |
| [5] | CHEN Feng, MAO Haobin, CAI Jiling, et al.. Multidimensional Cross-Layer Bandwidth Prediction for Low-Latency Real-Time Video [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(11): 18-27. |
| [6] | LIN Hongyi, LIU Yang, LI Shen, et al. Research Progress on Key Technologies in the Cooperative Vehicle Infrastructure System [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(10): 46-67. |
| [7] | XU Lunhui, YU Jiaxin, PEI Mingyang, et al. Repositioning Strategy for Ride-Hailing Vehicles Based on Geometric Road Network Structure and Reinforcement Learning [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(10): 99-109. |
| [8] | WANG Gao, CHEN Xiaohong, LIU Ning, et al. A Robot Grasping Policy Based on Viewpoint Selection Experience Enhancement Algorithm [J]. Journal of South China University of Technology(Natural Science Edition), 2022, 50(9): 126-137. |
| [9] |
YAN Junwei HUANG Qi ZHOU Xuan .
Energy-saving Optimization Operation of Central Air-conditioning System Based on Double-DQN Algorithm
|
| [10] | . Effect of Combination Mode of Traffic Guidance Information on Route Decision-Making [J]. Journal of South China University of Technology (Natural Science Edition), 2017, 45(8): 77-83. |
| [11] | Xu Yu- bin Chen Jia- mei Ma Lin. Q- Learning- Based Network Selection Strategy for Access Control in WLAN/WIMAX [J]. Journal of South China University of Technology (Natural Science Edition), 2013, 41(8): 41-46,60. |
| [12] | Hao Chuan-chuan Fang Zhou Li Ping. Efficient Reinforcement-Learning Control Algorithm Using Experience Reuse [J]. Journal of South China University of Technology(Natural Science Edition), 2012, 40(6): 70-75. |
| [13] | Zhang Min Xiao Ren-bin. Partner Selection of Virtual Enterprises in View of Multi-Attribute Group Decision-Making [J]. Journal of South China University of Technology (Natural Science Edition), 2011, 39(1): 124-128. |
| [14] | Yu Tao Hu Xi-bing Liu Jing. Multi-Objective Optimal Power Flow Calculation Based on Multi-Step Q(λ) Learning Algorithm [J]. Journal of South China University of Technology (Natural Science Edition), 2010, 38(10): 139-145. |
| [15] | Ji Yan-jie Wang Wei Deng Wei. Real-Time Decision-Making Method Based on Fuzzy Logic for Parking Reservation [J]. Journal of South China University of Technology (Natural Science Edition), 2010, 38(10): 100-104. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||