Journal of South China University of Technology(Natural Science Edition) ›› 2024, Vol. 52 ›› Issue (6): 1-11.doi: 10.12141/j.issn.1000-565X.230262
Special Issue: 2024年绿色智慧交通
• Green & Intelligent Transportation • Previous Articles Next Articles
Visual SLAM Algorithm Based on Memory Parking Scene
HU Xizhi( ), CUI Bofei(), WANG Qin, LIU Hong
), CUI Bofei(), WANG Qin, LIU Hong
- School of Mechanical and Automotive Engineering,South China University of Technology,Guangzhou 510640,Guangdong,China
-
Received:2023-04-22Online:2024-06-10Published:2023-10-27 -
Contact:CUI Bofei E-mail:huxizhi@scut.edu.cn;klysxc616@163.com -
Supported by:the National Natural Science Foundation of China(51975219)
CLC Number:
Cite this article
HU Xizhi, CUI Bofei, WANG Qin, LIU Hong. Visual SLAM Algorithm Based on Memory Parking Scene[J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(6): 1-11.
share this article
Table 1
Network details of lightweight shared encoder"
| 结构名称 | 执行操作 | 关键参数 | |||
|---|---|---|---|---|---|
| 输入输出通道数 | 核大小 | 步长 | |||
| Block1 | Conv1_a | DPconv+BN+LReLU | 1,64 | 3 × 3 | 1 |
| Conv1_b | DPconv+BN+LReLU | 64,64 | 3 × 3 | 1 | |
| Pooling1 | Max pooling | 64,64 | 2 × 2 | 2 | |
| Block2 | Conv2_a | DPconv+BN+LReLU | 64,64 | 3 × 3 | 1 |
| Conv2_b | DPconv+BN+LReLU | 64,64 | 3 × 3 | 1 | |
| Pooling2 | Max pooling | 64,64 | 2 × 2 | 2 | |
| Block3 | Conv3_a | DPconv+BN+LReLU | 64,128 | 3 × 3 | 1 |
| Conv3_b | DPconv+BN+LReLU | 128,128 | 3 × 3 | 1 | |
| Pooling3 | Max pooling | 128,128 | 2 × 2 | 2 | |
| Block4 | Conv4_a | DPconv+BN+LReLU | 128,128 | 3 × 3 | 1 |
| Conv4_b | DPconv+BN+LReLU | 128,128 | 3 × 3 | 1 | |
Table 2
Comparison of model size"
| 算法名称 | 模型参数量 | 模型计算量 |
|---|---|---|
| SuperPoint算法 | 1.52×106 | 1.58×1010 |
| 文中特征提取算法 | 2.28×105 | 2.12×109 |
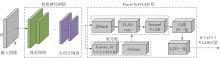
Fig.1
Schematic diagram of the proposed image retrieval algorithm"
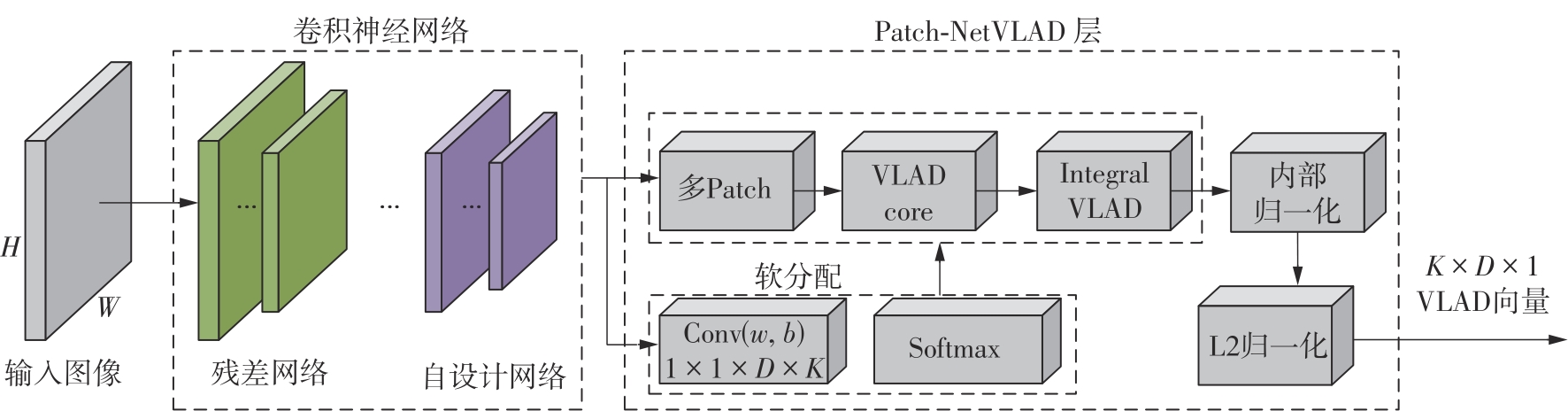
Fig.2
Improved image retrieval network structures"
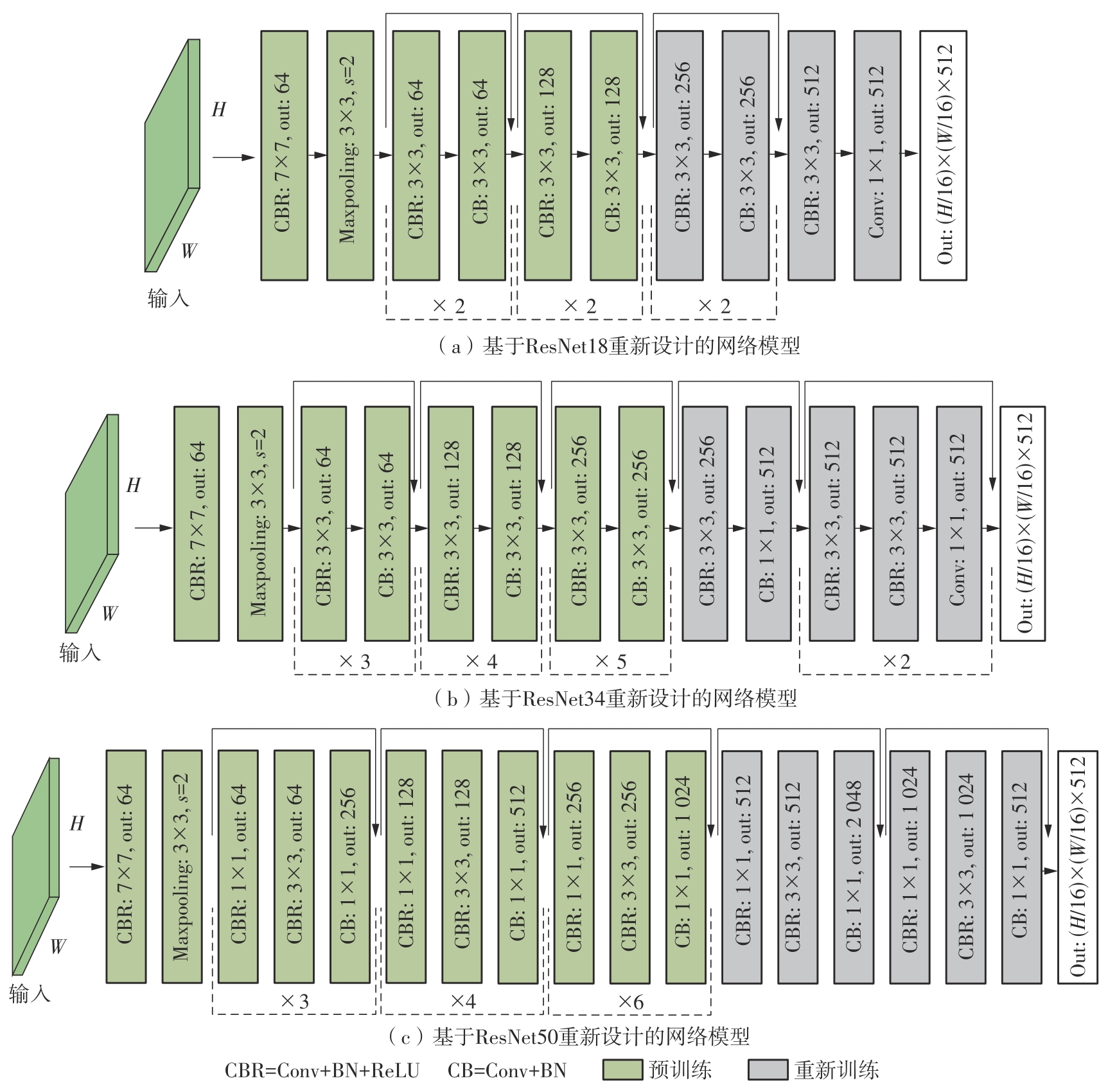
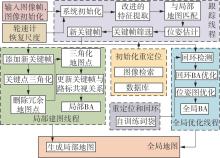
Fig.3
Flow chart of the constructed visual SLAM system"
Table 3
Performance comparison of key point detection performance for Hatches dataset"
| 算法名称 | 可重复率/% | 位置误差/m |
|---|---|---|
| ORB | 41.81 | 1.28 |
| SIFT | 42.20 | 1.17 |
| SuperPoint | 59.25 | 1.08 |
| 文中算法 | 54.48 | 1.19 |

Fig.4
Experiment images of feature extraction"

Table 4
Comparison of feature extraction and detection efficiency"
| 算法名称 | 每帧检测时间/s | 图片尺寸/(像素×像素) | 平均每帧图像的特征点数量 |
|---|---|---|---|
| ORB | 0.004 | 1 280✕960 | 949 |
| SIFT | 0.198 | 1 280✕960 | 837 |
| SuperPoint | 0.679 | 1 280✕960 | 1 073 |
| 文中算法 | 0.355 | 1 280✕960 | 1 002 |
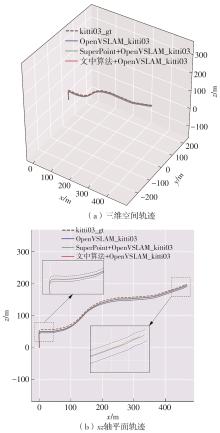
Fig.5
Screen capture images of experimental results of various algorithms running KITTI03 sequences"
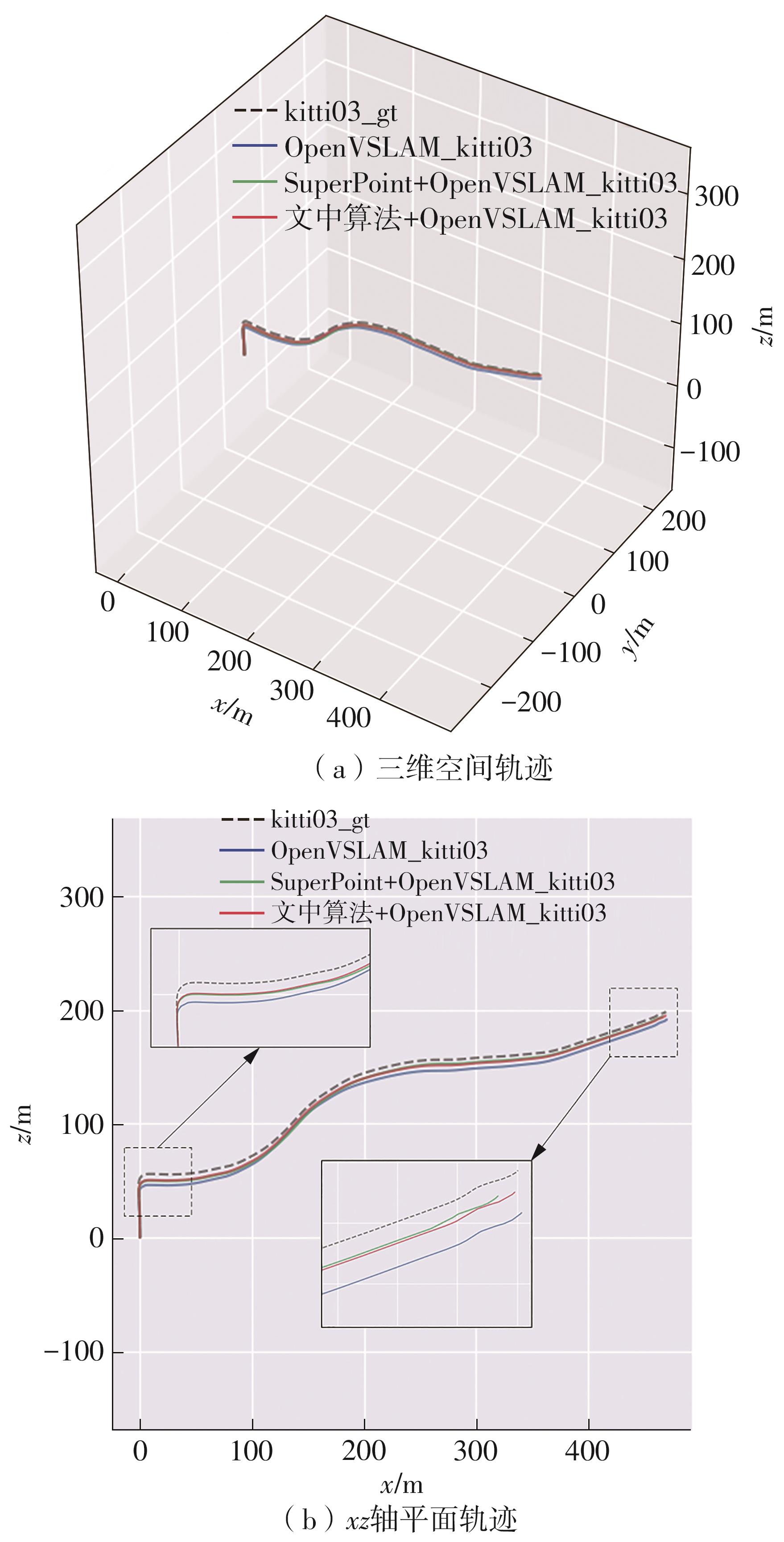
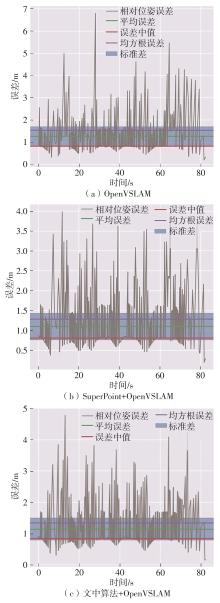
Fig.6
Screen capture images of RPE analysis of each system in KITTI03 sequence"
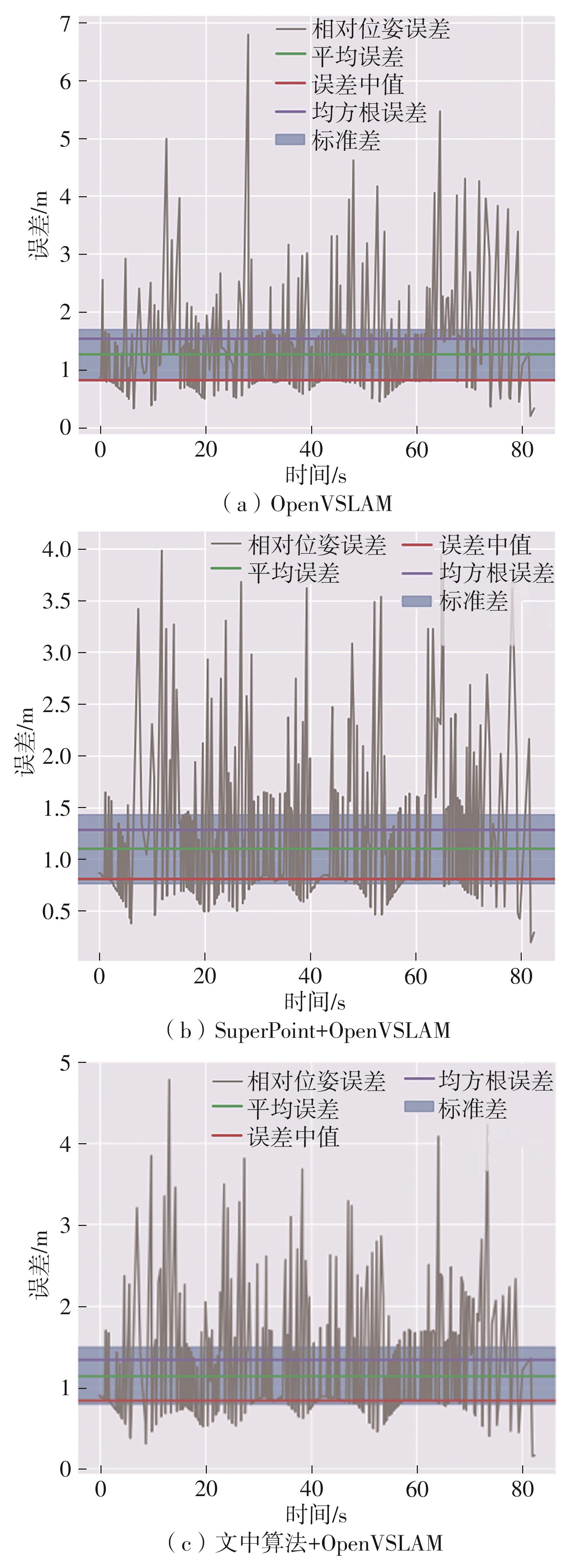
Table 5
Error indicators of each system in KITTI03 sequence"
| 系统名称 | RMSE | 最大误差 | 最小误差 | 标准差 | 平均误差 |
|---|---|---|---|---|---|
| OpenVSLAM | 1.52 | 6.79 | 0.20 | 0.89 | 1.26 |
| SuperPoint+OpenVSLAM | 1.29 | 3.98 | 0.19 | 0.66 | 1.10 |
| 文中算法+OpenVSLAM | 1.34 | 4.78 | 0.15 | 0.70 | 1.14 |
Fig.7
Loss curves obtained by training four network models"
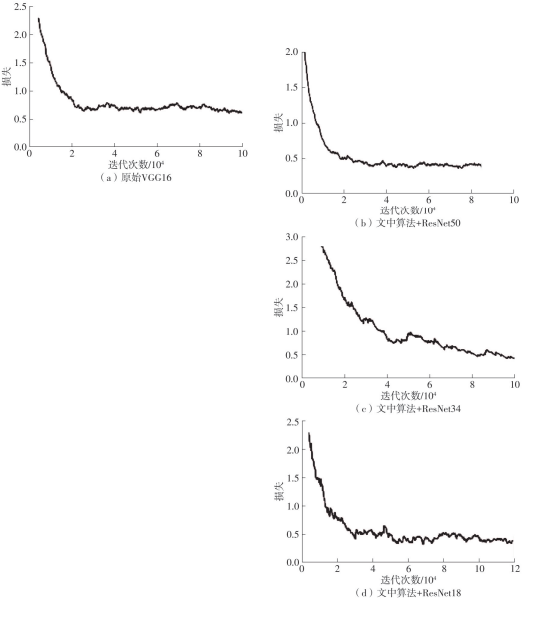
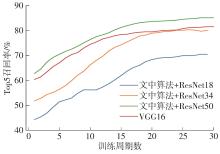
Fig.8
Comparison of Top5 recall rates"

Fig.9
Three kinds of scenery samples"


Fig.10
Mask image"

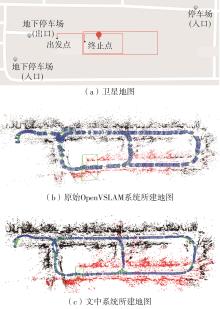
Fig.11
Comparison of constructed maps of underground parking lot"

Fig.12
Satellite map of aboveground parking lot"


Fig.13
Comparison of constructed maps of aboveground parking lot"

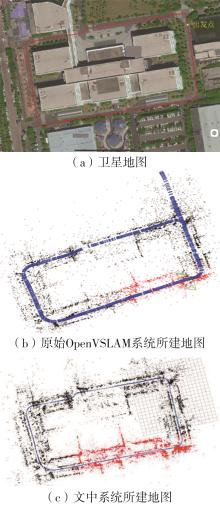
Fig.14
Comparison of constructed maps of outdoor road in a semienclosed park"
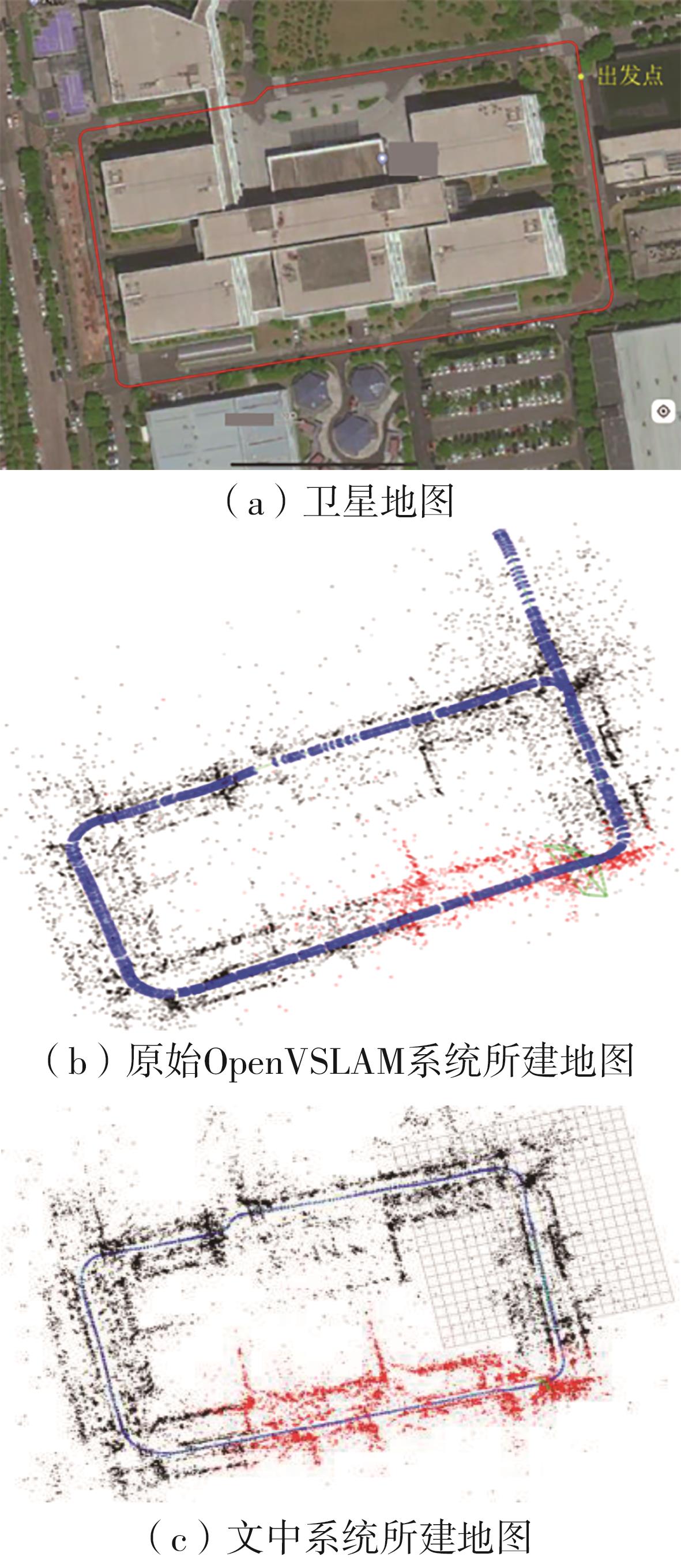

Fig.15
Schematic diagrams of placing ice cream cones for positioning experiments in indoor and outdoor scenes"

Table 6
Positioning error in three scenes"
| 场景类别 | 纵向定位误差/cm | 纵向定位误差目标 | 横向定位误差/cm | 横向定位误差目标 |
|---|---|---|---|---|
| 地下停车场 | 6.62 | 不大于30 cm | 6.71 | 不大于20 cm |
| 地上停车场 | 9.24 | 8.53 | ||
| 室外道路 | 9.39 | 9.67 | ||
| 平均值 | 8.42 | 8.30 |
| 1 | DAVISON A J, REID I D, MOLTON N D,et al .MonoSLAM:real-time single camera SLAM[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2007,29(6):1052-1067. |
| 2 | 田超然 .面向视觉SLAM的联合特征匹配和跟踪算法研究[D].深圳:中国科学院深圳先进技术研究院,2020. |
| 3 | KONDA K, MEMISEVIC R .Learning visual odometry with a convolutional network[C]∥Proceedings of the 10th International Conference on Computer Vision Theory and Applications.[S. l.]:SciTePress,2015:486-490. |
| 4 | COSTANTE G, MANCINI M, VALIGI P,et al .Exploring representation learning with CNNs for frame-to-frame ego-motion estimation[J].IEEE Robotics and Automation Letters,2016,1(1):18-25. |
| 5 | ULLMAN S .The interpretation of structure from motion[J].Proceedings of the Royal Society of London,Series B,Biological Sciences,1979,203(1153):405-426. |
| 6 | ZHOU H, UMMENHOFER B, BROX T .DeepTAM:deep tracking and mapping[C]∥Proceedings of the 2018 European Conference on Computer Vision.[S. l.]:[s. n.],2018:822-838. |
| 7 | NEWCOMBE R A, LOVEGROVE S J, DAVISON A J .DTAM:dense tracking and mapping in real-time[C]∥Proceedings of 2011 International Conference on Computer Vision.[S. l.]:IEEE,2011:2320-2327. |
| 8 | HANDA A, BLOESCH M, PĂTRĂUCEAN V,et al .gvnn:neural network library for geometric computer vision[C]∥Proceedings of Computer Vision—ECCV 2016 Workshops.Amsterdam:Springer International Publishing,2016:67-82. |
| 9 | WANG S, CLARK R, WEN H,et al .Deepvo:towards end-to-end visual odometry with deep recurrent convolutional neural networks[C]∥Proceedings of 2017 IEEE International Conference on Robotics and Automation.[S. l.]:IEEE,2017:2043-2050. |
| 10 | TANG J, FOLKESSON J, JENSFELT P .Geometric correspondence network for camera motion estimation[J].IEEE Robotics & Automation Letters,2018,3(2):1010-1017. |
| 11 | 兰凤崇,李继文,陈吉清 .面向动态场景复合深度学习与并行计算的DG-SLAM算法[J].吉林大学学报(工学版),2021,51(4):1437-1446. |
| LAN Feng-chong, LI Ji-wen, CHEN Ji-qing .DG-SLAM algorithm for dynamic scene compound deep learning and parallel computing[J].Journal of Jilin University (Engineering and Technology Edition),2021,51(4):1437-1446. | |
| 12 | 阮晓钢,郭佩远,黄静 .动态场景下基于深度学习的语义视觉SLAM[J].北京工业大学学报,2022,48(1):16-23. |
| RUAN Xiaogang, GUO Peiyuan, HUANG Jing .Semantic visual SLAM based on deep learning in dynamic scenes[J].Journal of Beijing University of Technology,2022,48(1):16-23. | |
| 13 | DETONE D, MALISIEWICZ T, RABINOVICH A .Superpoint:self-supervised interest point detection and description[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops.[S. l.]:IEEE,2018:224-236. |
| 14 | SCHMID C, MOHR R, BAUCKHAGE C .Evaluation of interest point detectors[J].International Journal of Computer Vision,2000,37(2):151-172. |
| 15 | GEIGER A, LENZ P, STILLER C,et al .Vision meets robotics:the kitti dataset[J].The International Journal of Robotics Research,2013,32(11):1231-1237. |
| 16 | STURM J, ENGELHARD N, ENDRES F,et al .A benchmark for the evaluation of RGB-D SLAM systems[C]∥Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems.[S. l.]:IEEE,2012:573-580. |
| [1] | ZUO Bin, DONG Tianhang, ZHANG Zehui, WANG Huajun, HUO Weiwei, GONG Wenfeng, CHENG Junsheng. Proton Exchange Membrane Fuel Cell Fault Prediction Method Based on Deep Learning [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(7): 21-30. |
| [2] | HU Guanghua, DAI Zhigang, WANG Qinghui. Machining Feature Recognition Method of B-Rep Model Based on Graph Neural Network [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(5): 20-31. |
| [3] | LIU Hao, YUAN Hui, CHEN Chen, et al. Point Cloud Geometry Coding Framework Based on Sampling [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(6): 148-156. |
| [4] | YANG Chunling, LIANG Ziwen. Feature-Domain Proximal High-Dimensional Gradient Descent Network for Image Compressed Sensing [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(3): 119-130. |
| [5] | ZHENG Juanyi, DONG Jiahao, ZHANG Qingjue, et al. Reconfigurable Intelligence Surface Channel Estimation Algorithm Based on RDN [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(3): 102-111. |
| [6] | CONG Ming, WEN Xu, WANG Minghao, et al. A GPS-Laser-IMU Fusion Mapping Algorithm Based on Iterated Kalman Filter [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(3): 75-83. |
| [7] | ZHOU Lang, FAN Kun, QU Hua, et al. Forest Fire Recognition by Improved EfficientNet-E Model Based on ECA Attention Mechanism [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(2): 42-49. |
| [8] | CHEN Qiong, FENG Yuan, LI Zhiqun, YANG Yong. Semantic-Visual Consistency Constraint Network for Zero-Shot Image Semantic Segmentation [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(10): 41-50. |
| [9] | LIU Weipeng, LI Xu, REN Ziwen, QI Yedong. Algorithm for Multiscale Residual Deformable Lung CT Image Registration [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(10): 135-145. |
| [10] | HU Guanghua, TU Qianxi. Surface Defect Detection Method for Industrial Products Based on Photometric Stereo and Dual Stream Feature Fusion Network [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(10): 112-123. |
| [11] | LI Fang, GUO Weisen, ZHANG Ping, et al.. Prediction Technique for Remaining Useful Life of Bearing Based on Spatial-Temporal Dual Cell State [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(9): 69-81. |
| [12] | SU Jindian, YU Shanshan, HONG Xiaobin. A Self-Supervised Pre-Training Method for Chinese Spelling Correction [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(9): 90-98. |
| [13] | LI Jiachun, LI Bowen, LIN Weiwei. AdfNet: An Adaptive Deep Forgery Detection Network Based on Diverse Features [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(9): 82-89. |
| [14] | GUO Enqiang, FU Xinsha. Dropped Object Detection Method Based on Feature Similarity Learning [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(6): 30-41. |
| [15] | ZHAO Jiandong, JIAO Lanxin, ZHAO Zhimin, et al. A Car-Following Model Driven by Combination of Theory and Data Considering Effects of Lane Change of Side Cars [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(6): 10-19. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||