Journal of South China University of Technology(Natural Science Edition) ›› 2025, Vol. 53 ›› Issue (3): 1-11.doi: 10.12141/j.issn.1000-565X.240100
• Computer Science & Technology • Next Articles
Single-Stage Object Detection Algorithm with Enhanced Pillar Feature Encoding
LUO Yutao( ), MAO Haojie
), MAO Haojie
- School of Mechanical and Automotive Engineering/ Guangdong Provincial Key Laboratory of Automotive Engineering,South China University of Technology,Guangzhou 510640,Guangdong,China
-
Received:2024-03-05Online:2025-03-10Published:2024-04-26 -
Supported by:the Special Fund for High-Quality Development of Manufacturing Industry,the Ministry of Industry and Information Technology of China(R-ZH-023-QT-001-20221009-001)
CLC Number:
Cite this article
LUO Yutao, MAO Haojie. Single-Stage Object Detection Algorithm with Enhanced Pillar Feature Encoding[J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(3): 1-11.
share this article
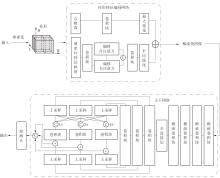
Fig.1
Overall structure of point cloud object detection algorithm"
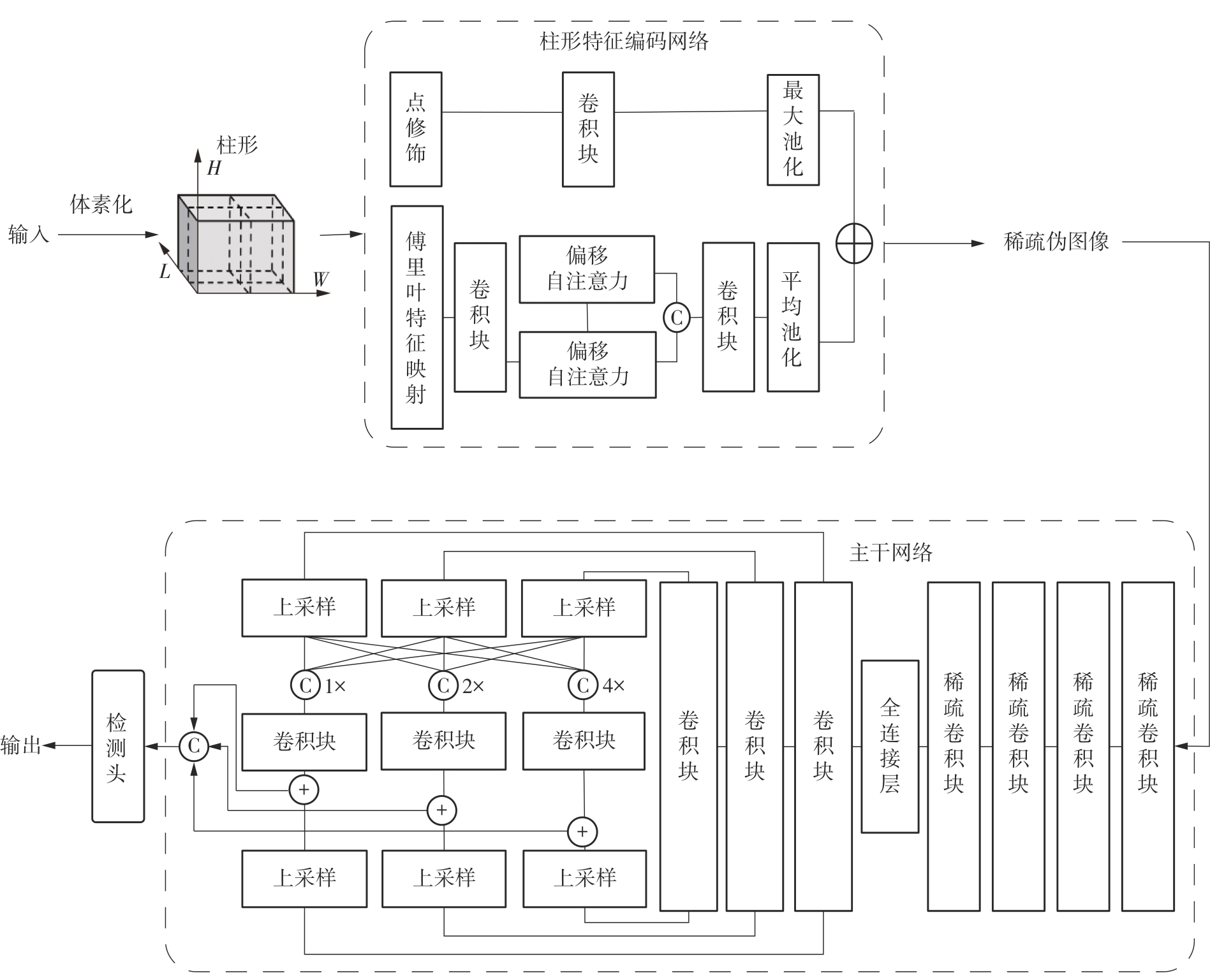
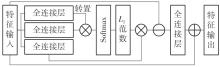
Fig.2
Structure of offset self-attention layer"
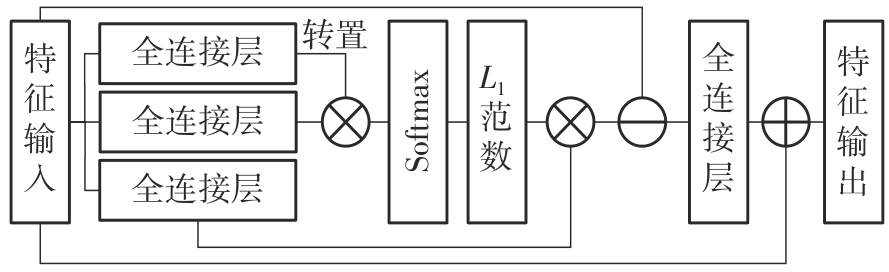
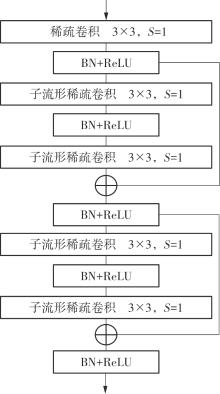
Fig.3
Sparse convolutional block structure"
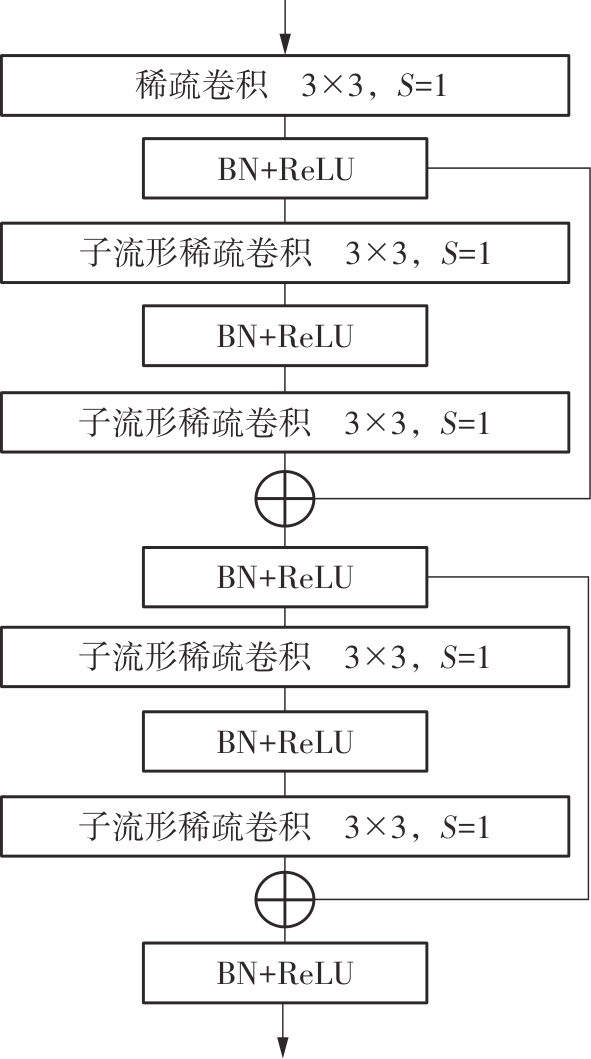
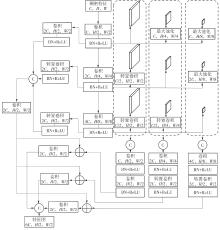
Fig.4
Structure of feature fusion network"
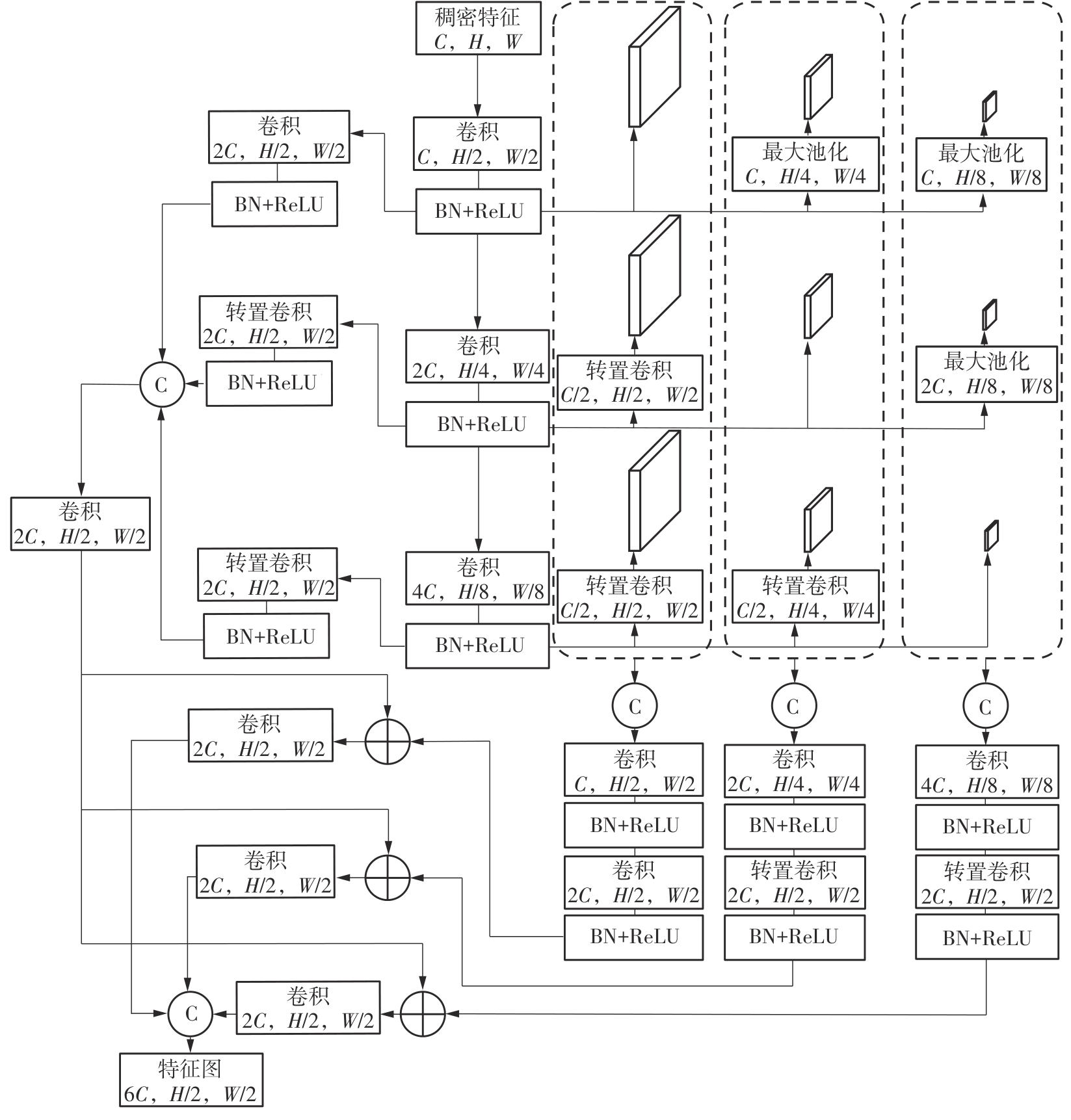
Table 1
Average precision for 3D detection on KITTI dataset"
| 算法 | 汽车(IoU = 0.7)的AP/% | 骑行者(IoU = 0.5)的AP/% | 行人(IoU = 0.5)的AP/% | 中等难度的mAP/% | vf /(f·s-1) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 容易 | 中等 | 困难 | 容易 | 中等 | 困难 | 容易 | 中等 | 困难 | |||
| PointPillars | 88.05 | 77.03 | 73.48 | 84.47 | 64.38 | 59.94 | 46.97 | 41.90 | 36.65 | 61.10 | 53.4 |
| TANet | 87.97 | 76.67 | 73.61 | 83.39 | 62.71 | 58.60 | 51.80 | 45.08 | 40.41 | 61.49 | 37.0 |
| PiFEnet | 86.96 | 73.61 | 62.02 | 76.96 | 59.99 | 55.84 | 58.00 | 49.89 | 44.09 | 61.16 | 18.9 |
| 文中算法 | 88.05 | 78.68 | 74.21 | 81.69 | 62.81 | 59.48 | 56.59 | 49.12 | 44.20 | 63.54 | 31.5 |
Table 2
Average orientation similarity for 3D detection on KITTI dataset"
| 算法 | 汽车(IoU = 0.7)的AOS/% | 骑行者(IoU = 0.5)的AOS/% | 行人(IoU = 0.5)的AOS/% | 中等难度的mAOS/% | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 容易 | 中等 | 困难 | 容易 | 中等 | 困难 | 容易 | 中等 | 困难 | ||
| PointPillars | 96.12 | 91.44 | 86.25 | 86.63 | 69.82 | 65.37 | 40.18 | 36.83 | 33.91 | 66.03 |
| TANet | 95.86 | 91.73 | 88.52 | 88.45 | 72.77 | 69.24 | 51.27 | 45.62 | 43.35 | 70.04 |
| PiFEnet | 94.41 | 83.68 | 71.36 | 64.97 | 50.99 | 48.25 | 61.74 | 53.99 | 49.15 | 62.89 |
| 文中算法 | 95.68 | 91.55 | 88.46 | 89.35 | 71.45 | 68.29 | 52.74 | 49.17 | 46.12 | 70.72 |
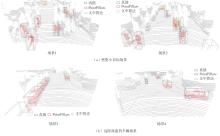
Fig.5
Visualization of detection results of two algorithms"
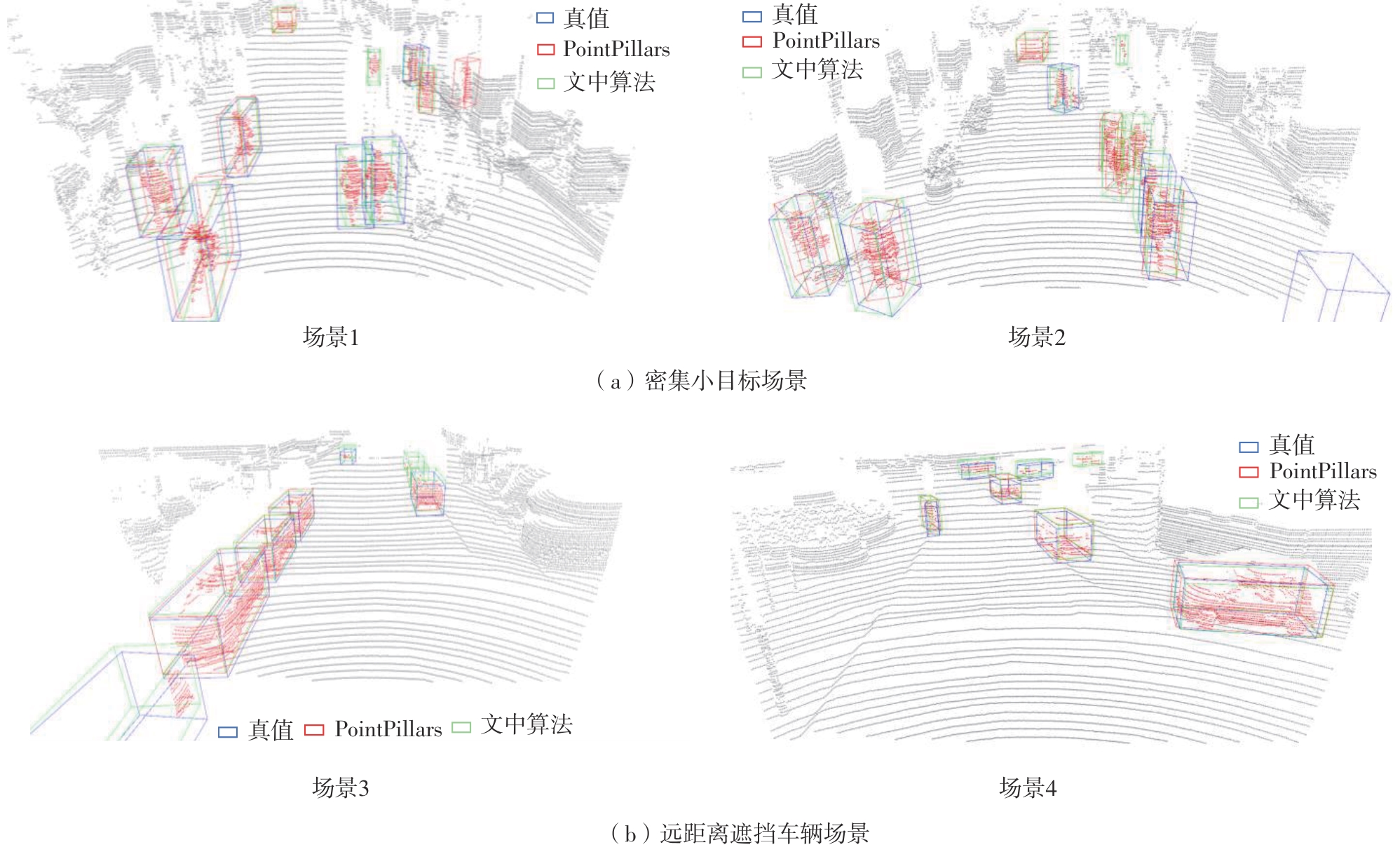
Table 3
Computing resources of real-time inference"
| 算法 | 参数量/106 | 显存占用/MB | tf / ms |
|---|---|---|---|
| 基线算法 | 3.43 | 2 037 | 18.7 |
| 柱形特征编码网络 | 4.48 | 2 533 | 23.6 |
| 主干网络 | 7.24 | 8 087 | 26.9 |
| 文中算法 | 8.25 | 8 367 | 31.7 |
Table 4
Ablation experimental results of algorithm component"
| 算法 | 汽车(IoU=0.7)的AP/% | 骑行者(IoU=0.5)的AP/% | 行人(IoU=0.5)的AP/% | mAP/% |
|---|---|---|---|---|
| 基线算法 | 77.03 | 64.38 | 41.90 | 61.10 |
| 仅配置柱形特征编码网络 | 76.91 | 60.52 | 46.55 | 61.33 |
| 仅配置主干网络 | 78.97 | 58.07 | 45.06 | 60.70 |
| 文中算法 | 78.68 | 62.81 | 49.12 | 63.54 |
Table 5
Ablation experimental results of Fourier feature mapping"
| 实验 | 汽车(IoU=0.7)的AP/% | 骑行者(IoU=0.5)的AP/% | 行人(IoU=0.5)的AP/% | mAP/% |
|---|---|---|---|---|
| 基线 | 77.03 | 64.38 | 41.90 | 61.10 |
| 实验1 | 76.48 | 59.09 | 41.47 | 59.01 |
| 实验2 | 77.18 | 59.26 | 44.20 | 60.21 |
| 实验3 | 77.08 | 58.13 | 45.62 | 60.28 |
| 实验4 | 76.86 | 59.96 | 47.39 | 61.40 |
| 实验5 | 76.64 | 60.03 | 45.95 | 60.87 |
| 实验6 | 72.05 | 51.10 | 45.02 | 56.06 |
| 实验7 | 68.25 | 48.69 | 35.98 | 50.97 |
| 实验 8 | 75.39 | 54.35 | 44.61 | 58.12 |
| 实验9 | 74.32 | 57.75 | 48.54 | 60.20 |
Table 6
Ablation experimental results of sampling density for pillar"
| 采样密度/点 | 汽车(IoU=0.7)的mAP/% | 骑行者(IoU=0.5)的mAP/% | 行人(IoU=0.5)的mAP/% | mAP/% |
|---|---|---|---|---|
| 16 | 78.46 | 57.16 | 49.25 | 61.62 |
| 32 | 78.68 | 59.48 | 49.12 | 63.54 |
| 48 | 78.43 | 58.87 | 51.49 | 62.93 |
Table 7
Ablation experimental results of enhanced pillar feature encoding for voxel-based algorithm applications"
| 算法 | 行人(IoU=0.5)的mAP/% | mAP/% | vf /(f·s-1) |
|---|---|---|---|
| SECOND | 46.79 | 62.58 | 29.3 |
| SECOND+ | 48.39 | 62.92 | 26.0 |
| Part-A2 | 47.62 | 63.69 | 11.8 |
| Part-A2+ | 49.66 | 64.33 | 11.1 |
| 文中算法 | 49.12 | 63.54 | 31.5 |
| 1 | WU Y, WANG Y, ZHANG S,et al .Deep 3D object detection networks using LiDAR data:a review[J].IEEE Sensors Journal,2020,21(2):1152-1171. |
| 2 | 田晟,宋霖,赵凯龙 .基于偏移注意力机制和多特征融合的点云分类[J].华南理工大学学报(自然科学版),2024,52(1):100-109. |
| TIAN Sheng, SONG Lin, ZHAO Kailong .Point cloud classification based on offset attention mechanism and multi-feature fusion[J].Journal of South China University of Technology (Natural Science Edition), 2024,52(1):100-109. | |
| 3 | ZENG Y, HU Y, LIU S,et al .RT3D:real-time 3-D vehicle detection in LiDAR point cloud for autonomous driving[J].IEEE Robotics and Automation Letters,2018,3(4):3434-3440. |
| 4 | MEYER G P, LADDHA A,KEE E,et al .LaserNet:an efficient probabilistic 3D object detector for autonomous driving[C]∥ Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach:IEEE,2019:12669-12678. |
| 5 | YUE Y, CAI Y, WANG D .GridNet-3D:a novel real-time 3D object detection algorithm based on point cloud[J].Chinese Journal of Electronics,2021,30(5):931-939. |
| 6 | SHI S, WANG X, LI H .PointRCNN:3D object proposal generation and detection from point cloud[C]∥ Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach:IEEE,2019:770-779. |
| 7 | YANG Z, SUN Y, LIU S,et al .STD:sparse-to-dense 3D object detector for point cloud[C]∥ Proceedings of 2019 IEEE/CVF International Conference on Computer Vision.Seoul:IEEE,2019:1951-1960. |
| 8 | YANG Z, SUN Y, LIU S,et al .3DSSD:point-based 3D single stage object detector[C]∥ Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle:IEEE,2020:11037-11045. |
| 9 | ZAMANAKOS G, TSOCHATZIDIS L, AMANATIADIS A,et al .A comprehensive survey of LiDAR-based 3D object detection methods with deep learning for autonomous driving[J].Computers & Graphics,2021,99:153-181. |
| 10 | ZHANG Y F, HU Q Y, XU G Q,et al .Not all points are equal:learning highly efficient point-based detectors for 3D LiDAR point clouds[C]∥ Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition.New Orlean:IEEE,2022:18931-18940. |
| 11 | ZHOU Y, TUZEL O .VoxelNet:end-to-end learning for point cloud based 3D object detection[C]∥ Procee-dings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:4490-4499. |
| 12 | YAN Y, MAO Y, LI B .SECOND:sparsely embedded convolutional detection[J].Sensors,2018,18:3337/1-17. |
| 13 | 龚章鹏,王国业,于是 .基于体素网络的道路场景多类目标识别算法[J].汽车工程,2021,43(4):469-477. |
| GONG Zhangpeng, WANG Guoye, YU Shi .The algorithm of multi-category object recognition in road scene based on voxel network[J].Automotive Engineering,2021,43(4):469-477. | |
| 14 | LI Z.LiDAR-based 3D object detection for autonomous driving[C]∥ Proceedings of 2022 International Confe-rence on Image Processing,Computer Vision and Machine Learning.Xi’an:IEEE,2022:507-512. |
| 15 | LANG A H, VORA S, CAESAR H,et al .PointPi-llars:fast encoders for object detection from point clouds[C]∥ Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach:IEEE,2019:12689-12697. |
| 16 | LIU Z, ZHAO X, HUANG T,et al .TANet:robust 3D object detection from point clouds with triple attention[C]∥ Proceedings of the 34th AAAI Conference on Artificial Intelligence.New York:AAAI,2020:11677-11684. |
| 17 | YE M, XU S, CAO T .HVNet:hybrid voxel network for LiDAR based 3D object detection[C]∥ Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle:IEEE,2020:1628-1637. |
| 18 | LE D T, SHI H, REZATOFIGHI H,et al .Accurate and real-time 3D pedestrian detection using an efficient attentive pillar network[J].IEEE Robotics and Automation Letters,2023,8(2):1159-1166. |
| 19 | SHI G, LI R, MA C .PillarNet:real-time and high-performance pillar-based 3D object detection[C]∥ Proceedings of the 17th European Conference on Computer Vision.Tel Aviv:Springer,2022:35-52. |
| 20 | ZHOU S, TIAN Z, CHU X,et al .FastPillars:a deployment-friendly pillar-based 3D detector[EB/OL].(2023-02-05)[2024-03-20].. |
| 21 | 程鑫,王宏飞,周经美,等 .基于体素柱形的激光雷达点云车辆目标检测算法[J].中国公路学报,2023,36(3):247-260. |
| CHENG Xin, WANG Hong-fei, ZHOU Jing-mei,et al .Vehicle detection algorithm based on voxel pillars from LiDAR point cloud[J].China Journal of Highway and Transport,2023,36(3):247-260. | |
| 22 | TANCIK M, SRINIVASAN P P, MILDENHALL B,et al .Fourier features let networks learn high frequency functions in low dimensional domains[C]∥ Advances in Neural Information Processing Systems 33:34 th Confe-rence on Neural Information Processing Systems.San Diego:Neural Information Processing Systems Foundation,Inc.,2020:7537-7547. |
| 23 | VASWANI A, SHAZEER N, PARMAR N,et al .Attention is all you need[C]∥ Advances in Neural Information Processing Systems 30:31st Conference on Neural Information Processing Systems.San Diego:Neural Information Processing Systems Foundation, Inc.,2017:5999-6009. |
| 24 | GUO M H, CAI J X, LIU Z N,et al .PCT:point cloud transformer[J].Computational Visual Media,2021,7:187-199. |
| 25 | SHI S, WANG Z, SHI J,et al .From points to parts:3D object detection from point cloud with part-aware and part-aggregation network[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,43(8):2647-2664. |
| [1] | YUE Yongheng, LEI Wenpeng. Foggy Road Environment Perception Algorithm Based on an Improved CycleGAN and YOLOv8 [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(2): 48-57. |
| [2] | YUE Yongheng, NING Ruihou. Intelligent Vehicle Object Detection Algorithm Based on Lightweight CenterNet [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(8): 45-55. |
| [3] | PENG Yipu, LI Jian, HAN Yanqun, TANG Zhiyuan, LI Zichao, YU Fengxiao, CHEN Li, ZOU Kui. Alignment Analysis of Railway Steel Truss Arch Bridge Based on Point Cloud Slicing Algorithm [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(7): 97-106. |
| [4] | HU Yongjian, ZHUO Sichao, LIU Beibei, WANG Yufei, LI Jicheng. Improvement of Cross-Dataset Performance of Face Forgery Detection Based on Multi-Scale Spatiotemporal Features and Tampering Probabilities [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(6): 110-119. |
| [5] | LIU Hao, YUAN Hui, CHEN Chen, GAO Wei. Point Cloud Geometry Coding Framework Based on Sampling [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(6): 148-156. |
| [6] | TIAN Sheng, SONG Lin, ZHAO Kailong. Point Cloud Classification Based on Offset Attention Mechanism and Multi-Feature Fusion [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(1): 100-109. |
| [7] | YU Bin, ZHANG Yuqin, WANG Yuchen, et al. Automated Extraction of Road Geometry Information Using Mobile LiDAR Point Cloud [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(2): 88-99. |
| [8] | YAO Qiangqiang, TIAN Ying, WANG Shengyuan, et al. Research on Path Tracking Control Strategy of Intelligent Vehicles Based on Force Drive [J]. Journal of South China University of Technology(Natural Science Edition), 2022, 50(2): 33-41,57. |
| [9] | FU Xinsha, PENG Jinhui, ZENG Yanjie, et al. Road Markings Condition Assessment Method for Intelligent Vehicles [J]. Journal of South China University of Technology(Natural Science Edition), 2022, 50(11): 1-13. |
| [10] | LUO Dongyu, WANG Jiangfeng, CHEN Jingya, et al. Operating Speed Prediction Based on Dynamic Visual Field in Three-Dimensional Point Cloud Environment [J]. Journal of South China University of Technology (Natural Science Edition), 2021, 49(7): 17-25. |
| [11] | MO Haijun CHEN Jie WANG Shundong. Fast Point Feature Histogram Descriptor Algorithm Combined With Point Cloud Texture Information [J]. Journal of South China University of Technology (Natural Science Edition), 2021, 49(6): 56-65,76. |
| [12] | HAO Xueli, SUN Zhaoyun, GENG Fangyuan, et al. Quantitative Evaluation for Aggregate Particle Angularity Based on 3D Point Cloud Data [J]. Journal of South China University of Technology (Natural Science Edition), 2021, 49(1): 142-152. |
| [13] | WU Qiuxia, LI Lingmin. 3D Object Detection Based on Point Cloud Bird's Eye View Remapping [J]. Journal of South China University of Technology(Natural Science Edition), 2021, 49(1): 39-46. |
| [14] | ZENG Dequan, YU Zhuoping, XIONG Lu, et al. Intelligent Vehicle Obstacle Avoidance Trajectory Planning in Structured Road Based on Analytic Hierarchy Process [J]. Journal of South China University of Technology (Natural Science Edition), 2020, 48(7): 65-75. |
| [15] | ZHANG Libin WU Dao SHAN Hongying LIU Qifeng. Dynamic Measurement Method for Vehicle Contour Dimensions Based on Laser Point Cloud [J]. Journal of South China University of Technology (Natural Science Edition), 2019, 47(3): 61-69. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||