Journal of South China University of Technology(Natural Science Edition) ›› 2022, Vol. 50 ›› Issue (12): 49-59.doi: 10.12141/j.issn.1000-565X.220025
Special Issue: 2022年计算机科学与技术
• Computer Science & Technology • Previous Articles Next Articles
Image Inpainting via Residual Attention Fusion and Gated Information Distillation
YU Ying HE Penghao XU Chaoyue
- School of Information Science and Engineering,Yunnan University,Kunming 650091,Yunnan,China
-
Received:2022-01-13Online:2022-12-25Published:2022-08-05 -
Contact:余映(1977-),男,博士,副教授,主要从事图像与视觉、人工神经网络研究。 E-mail:yuying.mail@163.com -
About author:余映(1977-),男,博士,副教授,主要从事图像与视觉、人工神经网络研究。 -
Supported by:the National Natural Science Foundation of China(62166048);the Applied Basic Research Project of Yunnan Province(2018FB102)
CLC Number:
Cite this article
YU Ying, HE Penghao, XU Chaoyue . Image Inpainting via Residual Attention Fusion and Gated Information Distillation[J]. Journal of South China University of Technology(Natural Science Edition), 2022, 50(12): 49-59.
share this article

Fig.1
Overall structure of the proposed model"
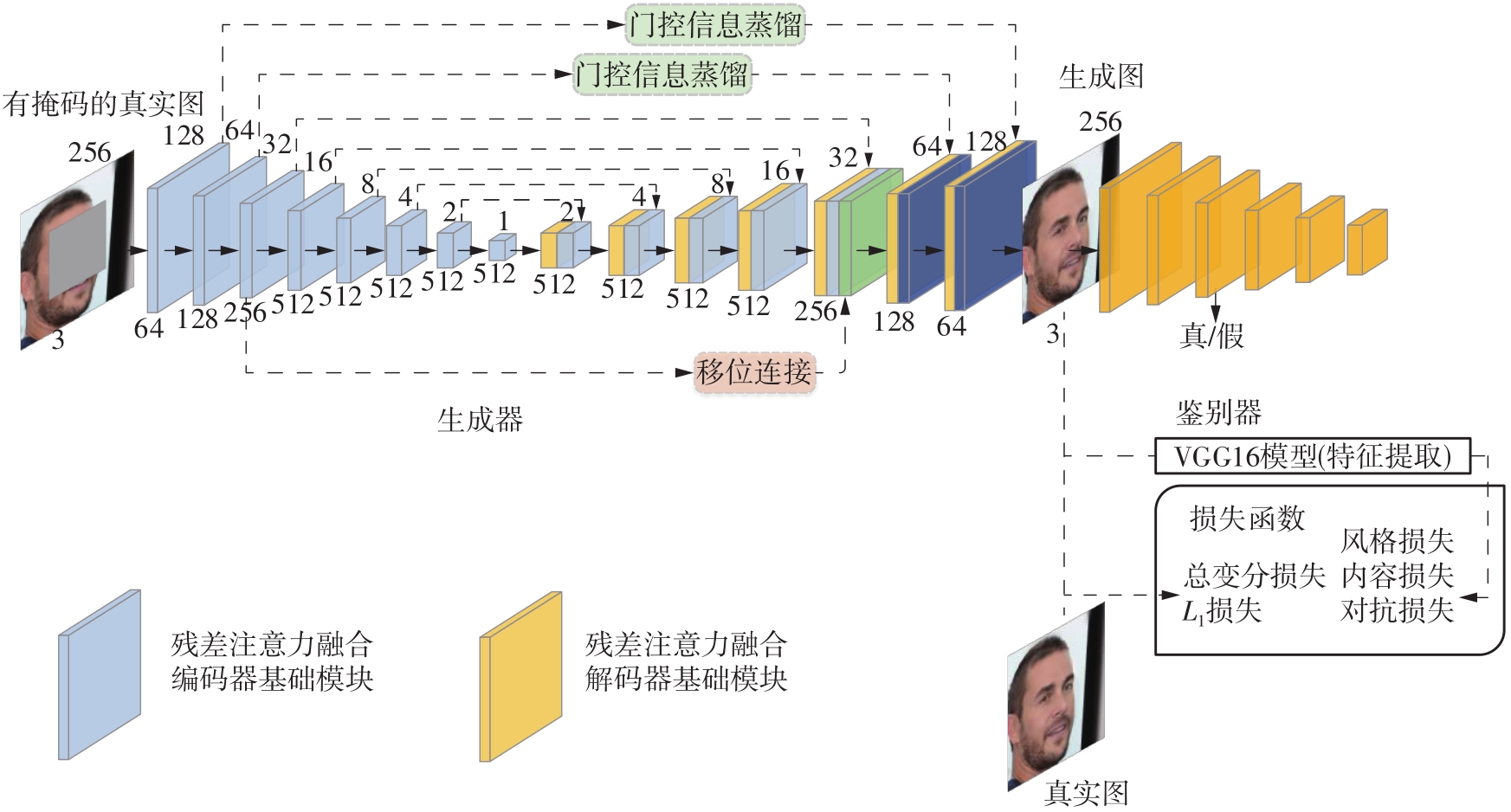
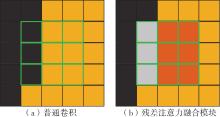
Fig.2
Comparison of the differences between ordinary convolution and residual attention fusion blocks"
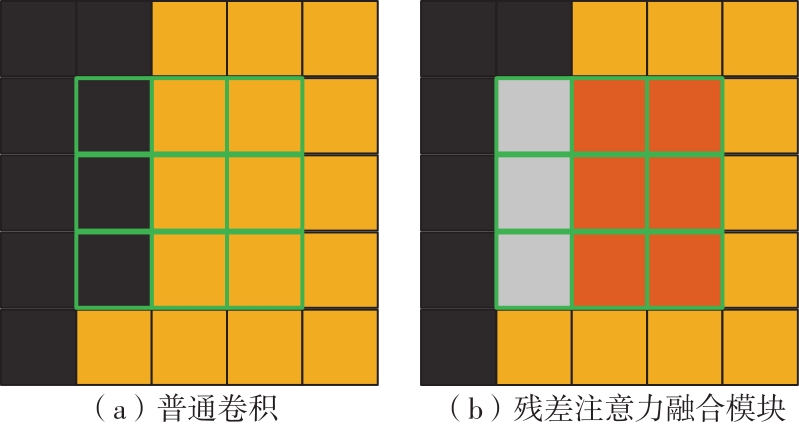
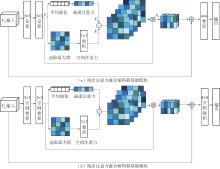
Fig.3
Residual attention fusion U-Net composition"
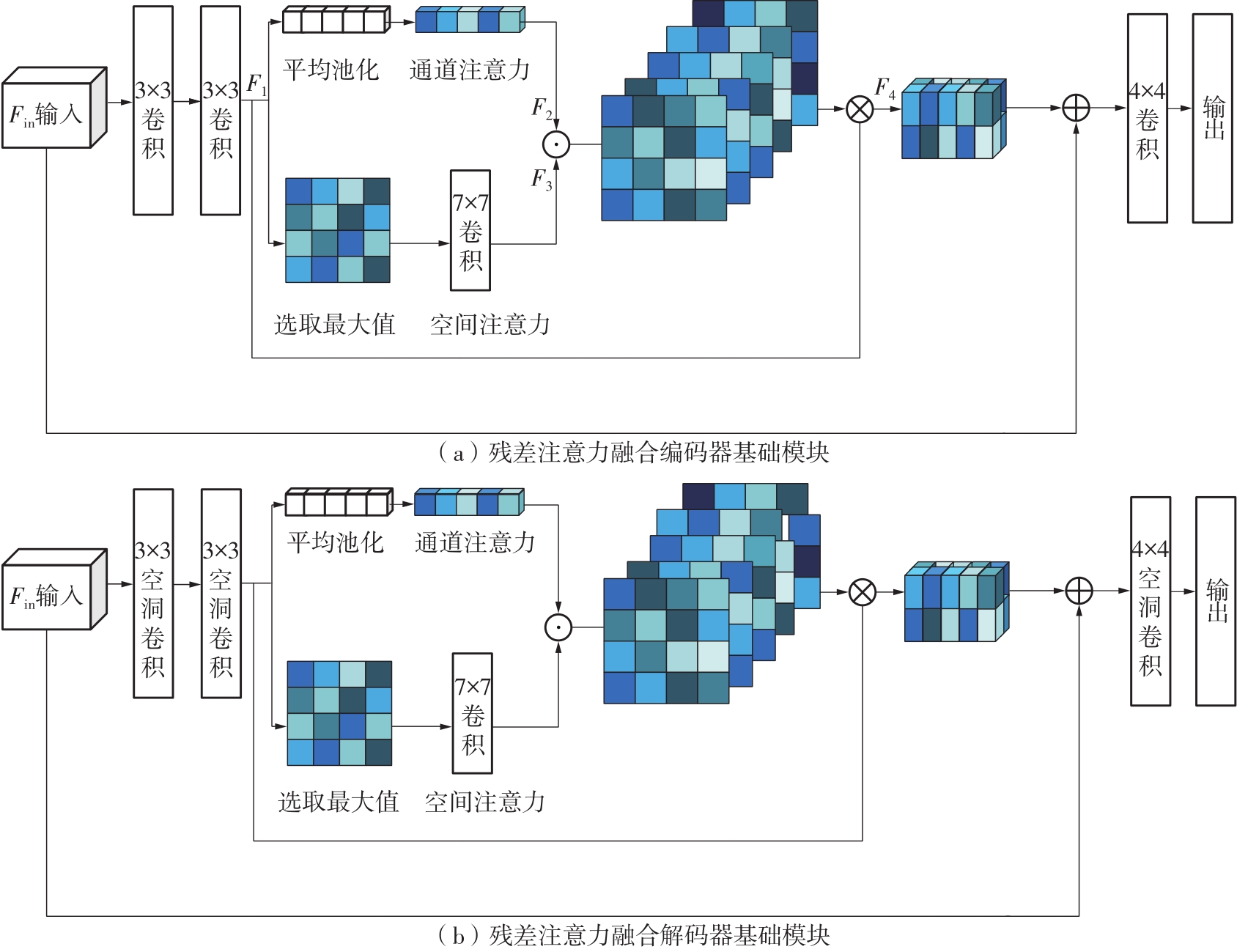
Fig.4
Gated information distillation block"
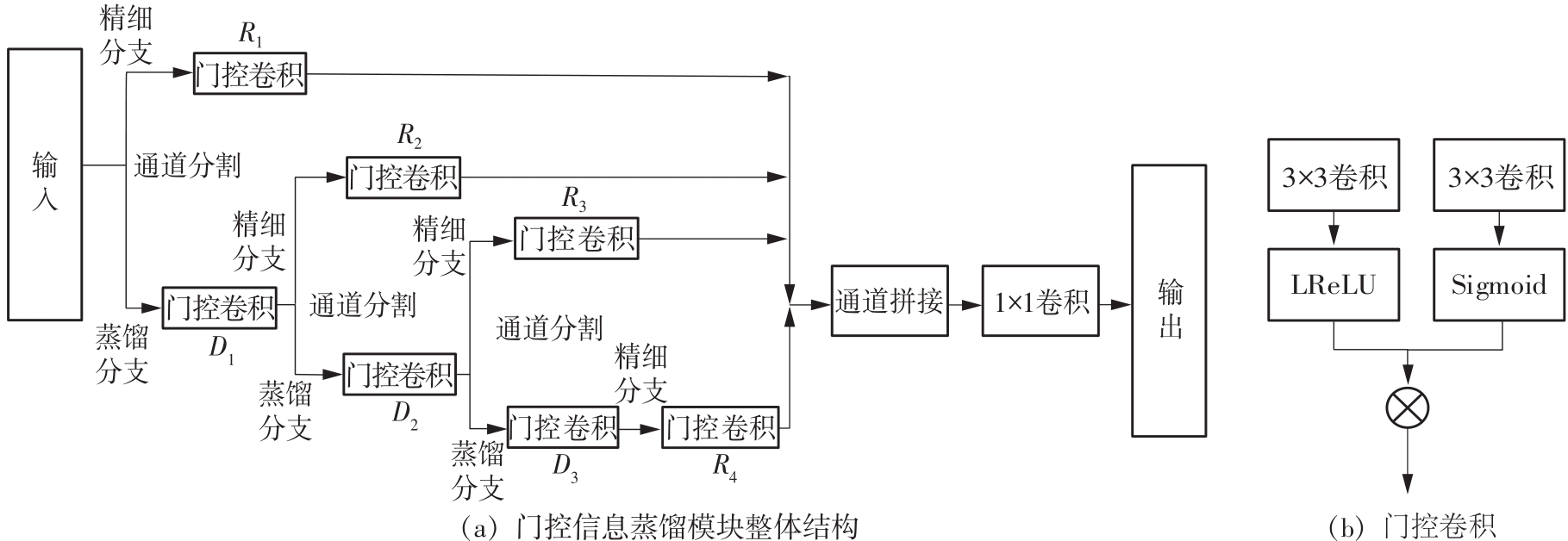
Table 1
Number of channels of the gated information distillation block"
| 输出结果 | 输入通道数 | 输出通道数 |
|---|---|---|
| D1 | 128 | 64 |
| R1 | 128 | 64 |
| D2 | 64 | 32 |
| R2 | 64 | 32 |
| D3 | 32 | 16 |
| R3 | 32 | 16 |
| R4 | 16 | 16 |
| 通道拼接 | 128 | 128 |
| 1×1卷积 | 128 | 128 |
Table 2
Quantitative analysis results of six models on two test sets"
| 模型 | CelebA-HQ数据集上 | Pairs数据集上 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SSIM | PSNR | L1损失 | L2损失 | FID | SSIM | PSNR | L1损失 | L2损失 | FID | ||
| GMCNN | 0.892 2 | 26.19 | 0.017 8 | 0.002 9 | 7.664 9 | 0.839 3 | 24.34 | 0.026 7 | 0.005 1 | 47.603 8 | |
| Shift-Net | 0.892 8 | 26.50 | 0.019 0 | 0.002 7 | 7.677 6 | 0.847 9 | 25.14 | 0.024 1 | 0.004 3 | 51.677 9 | |
| PEN | 0.870 3 | 25.35 | 0.023 6 | 0.003 4 | 14.141 5 | 0.828 0 | 23.82 | 0.025 3 | 0.005 8 | 63.825 9 | |
| PIC | 0.867 9 | 24.45 | 0.022 8 | 0.004 1 | 7.664 9 | 0.826 6 | 23.63 | 0.029 3 | 0.006 3 | 47.586 8 | |
| HIIH | 0.873 4 | 26.32 | 0.020 7 | 0.002 6 | 18.634 8 | 0.831 2 | 23.81 | 0.028 6 | 0.005 7 | 50.921 5 | |
| 本文模型 | 0.902 8 | 27.11 | 0.018 9 | 0.002 4 | 7.433 1 | 0.873 3 | 26.30 | 0.019 7 | 0.003 3 | 41.148 3 | |

Fig.5
Comparison of repair visual effects of six models"


Fig.6
Comparison of experimental results of module ablation"


Fig.7
Comparison of PSNR and FID for different module ablation experiments on the Pairs dataset"
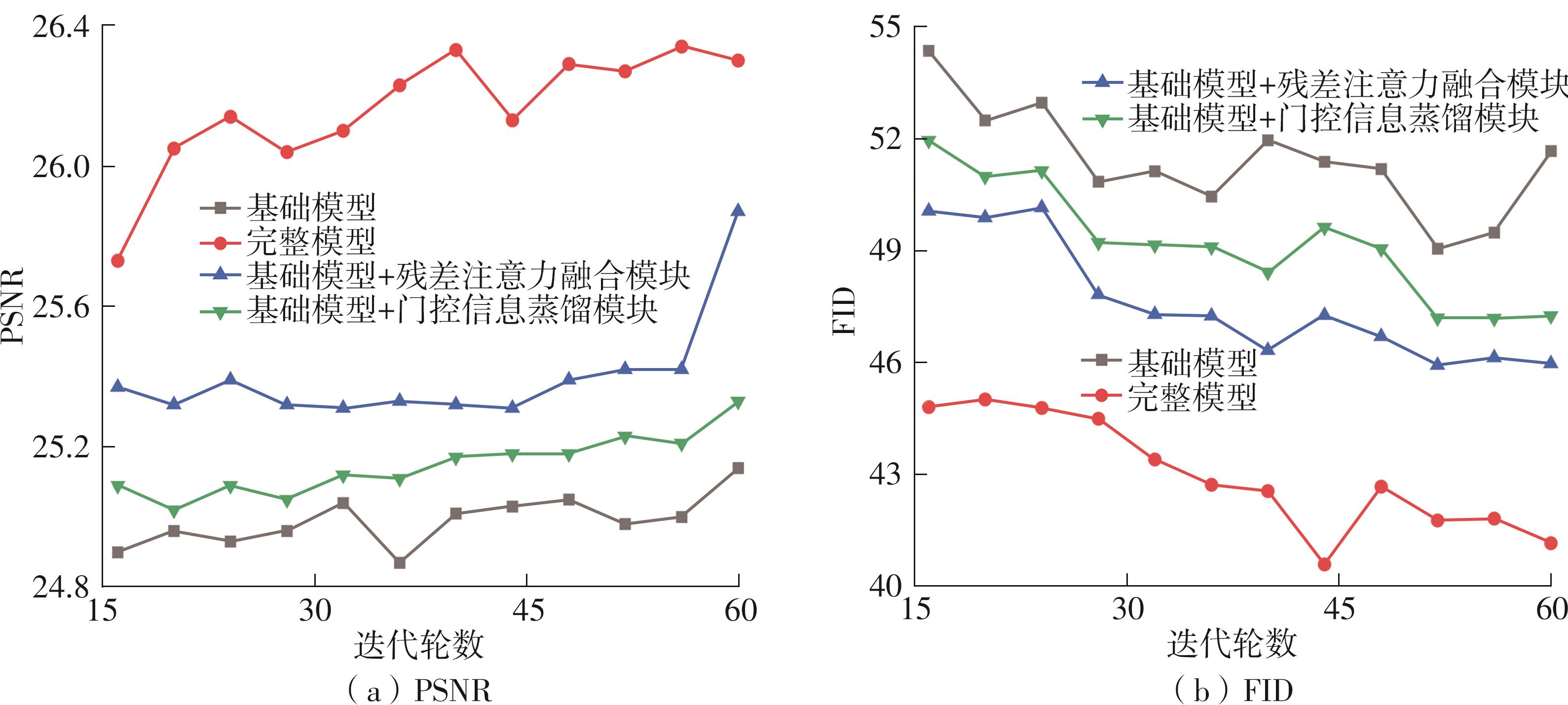

Fig.8
Comparison of ablation experimental results with different loss functions"

Table 3
Quantitative comparison of loss function ablation experiments on CelebA-HQ"
| 消融模型 | SSIM | PSNR | L1 | L2 | FID |
|---|---|---|---|---|---|
| 去除L1 | 0.260 3 | 10.12 | 0.222 0 | 0.098 6 | 414.975 3 |
| 去除Lstyle | 0.892 6 | 26.68 | 0.019 0 | 0.002 6 | 7.416 7 |
| 去除Lcontent | 0.886 7 | 25.68 | 0.020 0 | 0.003 1 | 11.604 9 |
| 去除Ltv | 0.895 5 | 26.46 | 0.019 0 | 0.002 7 | 7.320 6 |
| 去除Ladv | 0.896 5 | 27.01 | 0.018 0 | 0.002 4 | 10.928 1 |
| 完整模型 | 0.902 8 | 27.11 | 0.018 0 | 0.002 4 | 7.664 9 |

Fig.9
Repair effects of the proposed model under the irregular mask dataset"

| 1 | BERTALMIO M, SAPIRO G, CASELLES V,et al .Image inpainting[C]∥ Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques.New York:ACM,2000:417-424. |
| 2 | BARNES C, SHECHTMAN E, FINKELSTEIN A,et al .PatchMatch:a randomized correspondence algorithm for structural image editing[J].ACM Transactions on Gra-phics,2009,28(3):24/1-11. |
| 3 | RONNEBERGER O, FISCHER P, BROX T .U-Net:convolutional networks for biomedical image segmentation [C]∥ Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention.Munich:Springer,2015:234-241. |
| 4 | IIZUKA S, SIMO-SERRA E, ISHIKAWA H .Globally and locally consistent image completion[J].ACM Transactions on Graphics,2017,36(4):107/1-14. |
| 5 | YAN Z, LI X, LI M,et al .Shift-Net:image inpainting via deep feature rearrangement[C]∥ Proceedings of the 15th European Conference on Computer Vision.Munich:Springer,2018:3-19. |
| 6 | 杨昊,余映 .利用通道注意力与分层残差网络的图像修复[J].计算机辅助设计与图形学学报,2021,33(5):671-681. |
| YANG Hao, YU Ying .Image inpainting using channel attention and hierarchical residual network[J].Journal of Computer-Aided Design and Computer Graphics,2021,33(5):671-681. | |
| 7 | LIU H, JIANG B, XIAO Y,et al .Coherent semantic attention for image inpainting[C]∥ Proceedings of 2019 IEEE/CVF International Conference on Computer Vision.Seoul:IEEE,2019:4169-4178. |
| 8 | XIE C, LIU S, LI C,et al .Image inpainting with learnable bidirectional attention maps[C]∥ Procee-dings of 2019 IEEE/CVF International Conference on Computer Vision.Seoul:IEEE,2019:8857-8866. |
| 9 | LIU G, REDA F A, SHIH K J,et al .Image inpain-ting for irregular holes using partial convolutions[C]∥ Proceedings of the 15th European Conference on Computer Vision.Munich:Springer,2018:89-105. |
| 10 | YU J, LIN Z, YANG J,et al .Free-form image inpain-ting with gated convolution[C]∥ Proceedings of 2019 IEEE/CVF International Conference on Computer Vision.Seoul:IEEE,2019:4470-4479. |
| 11 | LIU H, JIANG B, SONG Y,et al .Rethinking image inpainting via a mutual encoder-decoder with feature equalizations[C]∥ Proceedings of the 16th European Conference on Computer Vision.Glasgow:Springer,2020:725-741. |
| 12 | LI J, WANG N, ZHANG L,et al .Recurrent feature reasoning for image inpainting[C]∥ Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle:IEEE,2020:7757-7765. |
| 13 | NAZERI K,NG E, JOSEPH T,et al .EdgeConnect:structure guided image inpainting using edge prediction [C]∥ Proceedings of 2019 IEEE/CVF International Conference on Computer Vision.Seoul:IEEE,2019:3265-3274. |
| 14 | MA Y, LIU X, BAI S,et al .Coarse-to-fine image inpainting via region-wise convolutions and non-local correlation[C]∥ Proceedings of the 28th International Joint Conference on Artificial Intelligence.Macao:AAAI,2019:3123-3129. |
| 15 | WANG N, LI J, ZHANG L,et al .MUSICAL:multi-scale image contextual attention learning for inpainting [C]∥ Proceedings of the 28th International Joint Confe-rence on Artificial Intelligence.Macao:AAAI,2019:3748-3754. |
| 16 | IOFFE S, SZEGEDY C .Batch normalization:accelera-ting deep network training by reducing internal covariate shift[C]∥ Proceedings of the 32nd International Conference on Machine Learning.Lille:JMLR.org,2015:448-456. |
| 17 | WOO S, PARK J, LEE J Y,et al .CBAM:convolutional block attention module[C]∥ Proceedings of the 15th European Conference on Computer Vision.Munich:Springer,2018:3-19. |
| 18 | PARK J,WOO S, LEE J Y,et al .BAM:bottleneck attention module[C]∥ Proceedings of 2018 British Machine Vision Conference.Newcastle:Springer,2018:147/1-14. |
| 19 | KARRAS T, AILA T, LAINE S,et al .Progressive growing of GANs for improved quality,stability,and variation[C]∥ Proceedings of the 6th International Confe-rence on Learning Representations.Vancouver:Elsevier,2018:1-26. |
| 20 | DOERSCH C, SINGH S, GUPTA A,et al .What makes Paris look like Paris? [J].Communications of the ACM,2015,58(12):103-110. |
| 21 | WANG Y, TAO X, QI X J,et al .Image inpainting via generative multi-column convolutional neural networks [C]∥ Proceedings of the 32nd International Conference on Neural Information Processing Systems.Montreal:MIT Press,2018:329-338. |
| 22 | ZENG Y, FU J, CHAO H,et al .Learning pyramid-context encoder network for high-quality image inpainting[C]∥ Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach:IEEE,2019:1486-1494. |
| 23 | ZHENG C, CHAM T J, CAI J .Pluralistic image completion [C]∥ Proceedings of 2019 IEEE/CVF Con-ference on Computer Vision and Pattern Recognition.Long Beach:IEEE,2019:1438-1447. |
| 24 | WADHWA G, DHALL A, MURALA S,et al .Hyperrea-listic image inpainting with hypergraphs [C]∥ Procee-dings of 2021 IEEE Winter Conference on Applications of Computer Vision.Waikoloa:IEEE,2021:3911-3920. |
| [1] | . Feature-domain Proximal High-Dimensional Gradient Descent Network for Image Compressed Sensing [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(3): 119-130. |
| [2] | ZHENG Juanyi, DONG Jiahao, ZHANG Qingjue, et al. Reconfigurable Intelligence Surface Channel Estimation Algorithm Based on RDN [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(3): 102-111. |
| [3] | . Research on Forest Fire Recognition Based on Improved EfficientNet-E Model Based on ECA Attention Mechanism [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(2): 42-49. |
| [4] | LI Haiyan, YIN Haolin, LI Peng, et al.. Image Inpainting Algorithm Based on Dense Feature Reasoning and Mix Loss Function [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(9): 99-109. |
| [5] | LI Fang, GUO Weisen, ZHANG Ping, et al.. Prediction Technique for Remaining Useful Life of Bearing Based on Spatial-Temporal Dual Cell State [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(9): 69-81. |
| [6] | SU Jindian, YU Shanshan, HONG Xiaobin. A Self-Supervised Pre-Training Method for Chinese Spelling Correction [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(9): 90-98. |
| [7] | LI Jiachun, LI Bowen, LIN Weiwei. AdfNet: An Adaptive Deep Forgery Detection Network Based on Diverse Features [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(9): 82-89. |
| [8] | GUO Enqiang, FU Xinsha. Dropped Object Detection Method Based on Feature Similarity Learning [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(6): 30-41. |
| [9] | ZHAO Jiandong, JIAO Lanxin, ZHAO Zhimin, et al. A Car-Following Model Driven by Combination of Theory and Data Considering Effects of Lane Change of Side Cars [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(6): 10-19. |
| [10] | YE Feng, CHEN Biao, LAI Yizong. Contrastive Knowledge Distillation Method Based on Feature Space Embedding [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(5): 13-23. |
| [11] | ZHAO Rongchao, WU Baili, CHEN Zhuyun, WEN Kairu, ZHANG Shaohui, LI Weihua. Graph Neural Network for Fault Diagnosis with Multi-Scale Time-Spatial Information Fusion Mechanism [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(12): 42-52. |
| [12] | HOU Liwei, WANG Hengsheng, ZOU Haoran. Deep Learning-Based Prediction of Contact Force in the Process of Shoveling Up Glass Subtrate [J]. Journal of South China University of Technology(Natural Science Edition), 2022, 50(8): 71-81. |
| [13] | MO Jianwen, ZHU Yanqiao, YUAN Hua, et al. Incremental learning based on neuron regularization and resource releasing [J]. Journal of South China University of Technology(Natural Science Edition), 2022, 50(6): 71-79,90. |
| [14] | LU Lu, ZHONG Wenyu, WU Xiaokun. Image tampering localization based on mutil-scale transformer [J]. Journal of South China University of Technology(Natural Science Edition), 2022, 50(6): 10-18. |
| [15] | ZHANG Qin, HU Jiahui, REN Hailin. Intelligent Pushing Method and Experiment of Feeding Assistant Robot [J]. Journal of South China University of Technology(Natural Science Edition), 2022, 50(6): 111-120. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||