Journal of South China University of Technology(Natural Science Edition) ›› 2026, Vol. 54 ›› Issue (3): 65-78.doi: 10.12141/j.issn.1000-565X.250092
• Intelligent Transportation System • Previous Articles Next Articles
CGT-YOLO-Based Algorithm for Small-Target Traffic Sign Recognition
XING Yan1,2, GUO Sihao1, ZHANG Zhen2,3, PAN Xiaodong2,3, AN Dong1,4
- 1.School of Transportation and Geomatics Engineering,Shenyang Jianzhu University,Shenyang 110168,Liaoning,China
2.National Engineering Research Center for Road Traffic Safety Control Technology,Shenyang 110168,Liaoning,China
3.Traffic Management Detachment of Shenyang Public Security Bureau,Shenyang 110168,Liaoning,China
4.Shenyang Cambrian Transportation Technology Co. ,Ltd. ,Shenyang 110168,Liaoning,China
-
Received:2025-04-01Online:2026-03-25Published:2025-10-31 -
Contact:郭思豪(1999 —),男,硕士,主要从事智能交通研究。 E-mail:27129433@qq.com -
About author:邢岩(1985—),男,博士,教授,主要从事智能交通研究。E-mail: xingyan@sjzu.edu.cn -
Supported by:the Open Project of National Engineering Research Center for Road Traffic Safety Control Technology(2024GCZXKFKT13B)
CLC Number:
Cite this article
XING Yan, GUO Sihao, ZHANG Zhen, PAN Xiaodong, AN Dong. CGT-YOLO-Based Algorithm for Small-Target Traffic Sign Recognition[J]. Journal of South China University of Technology(Natural Science Edition), 2026, 54(3): 65-78.
share this article
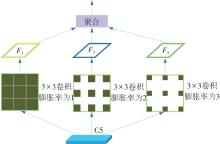
Fig.1
Structural diagram of CAM network"
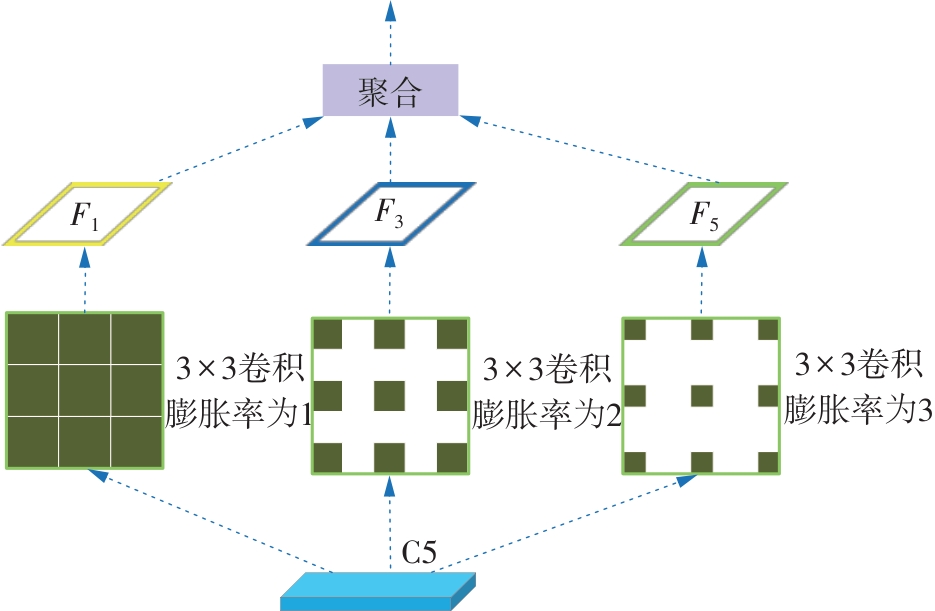
Fig.2
Integration method"
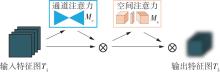
Fig.3
Structural diagram of GAM network"
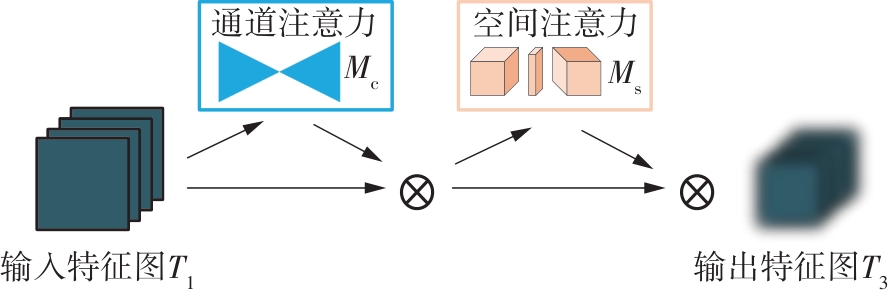
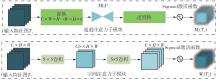
Fig.4
Attention submodule"
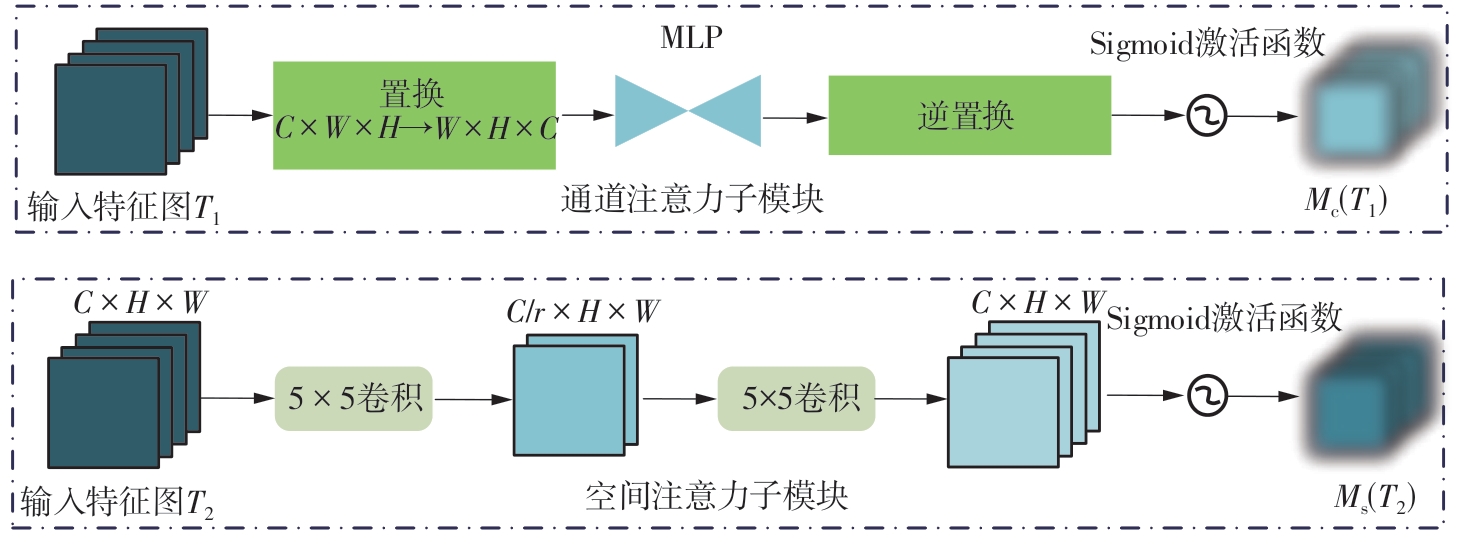
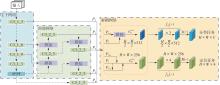
Fig.5
Structural diagram of TSC decoupled head"
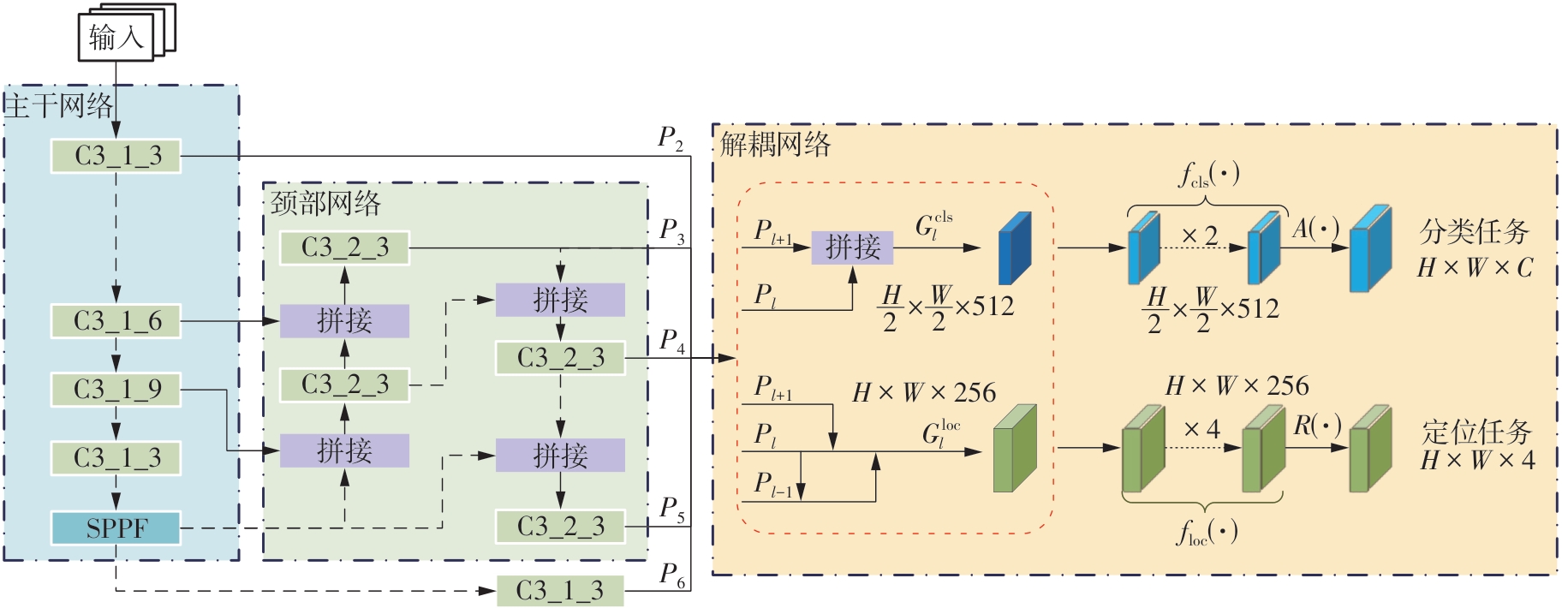
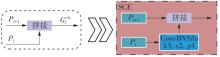
Fig.6
Structural diagram of SCE network"
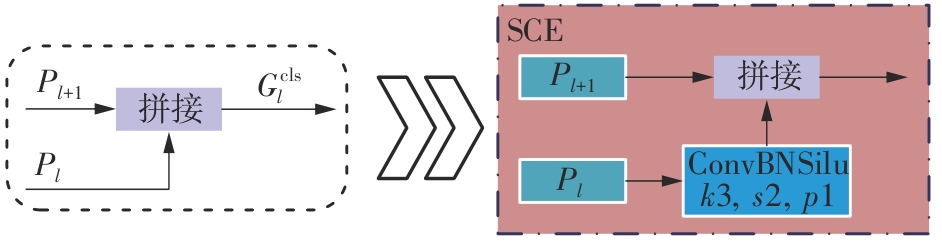
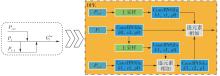
Fig.7
Structural diagram of DPE network"
Fig.8
Structural diagram of improved YOLOv5s network"
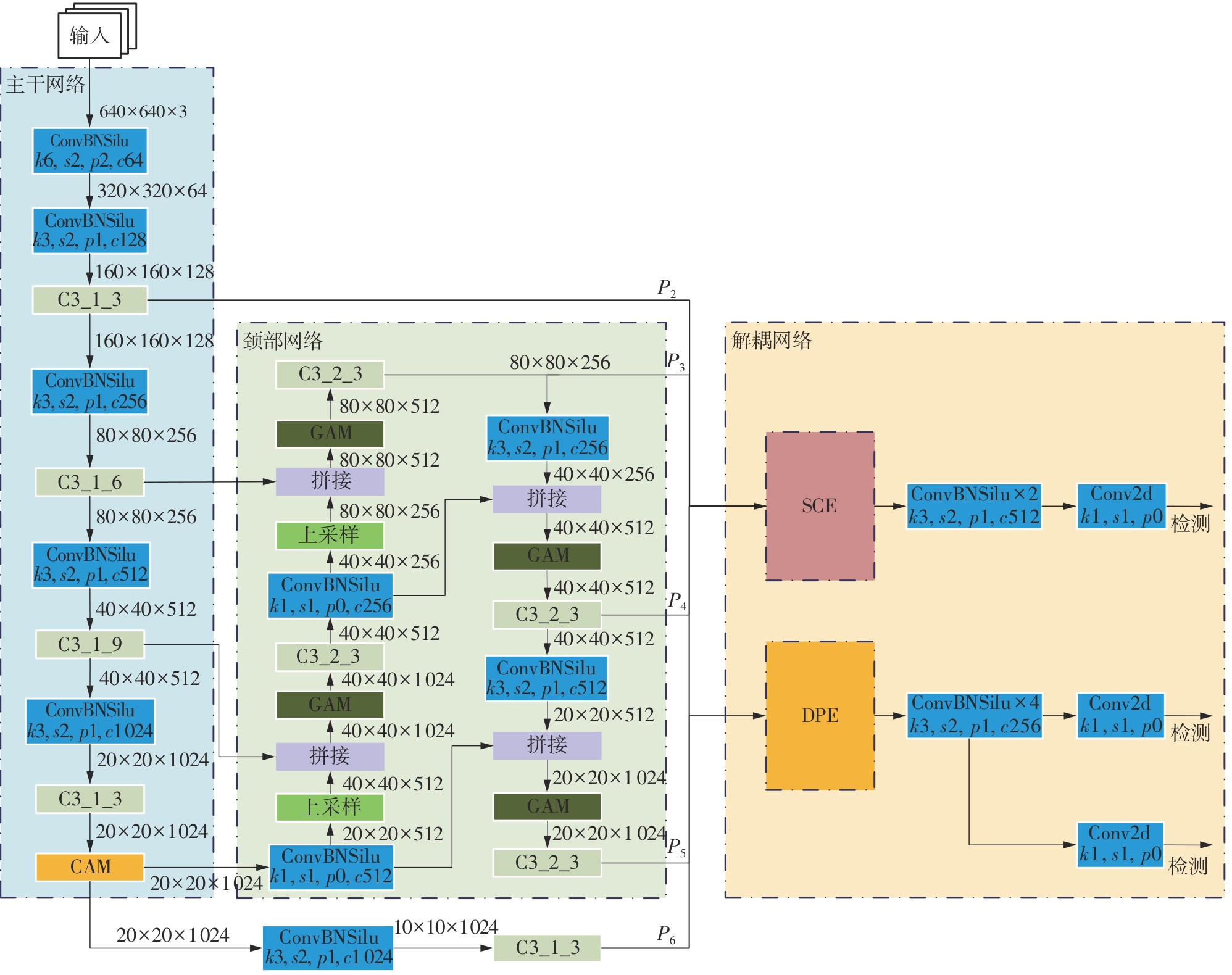
Table 1
Dataset labels"
| 类别 | 标志 | 英文 | 缩写 |
|---|---|---|---|
| 禁令标志 | 禁止驶入 | No Entry | NE |
| 禁止向左转弯 | No Left Turn | NLT | |
| 禁止向右转弯 | No Right Turn | NRT | |
| 禁止直行 | No Straight Through | NST | |
| 禁止掉头 | No U-Turn | NUT | |
| 禁止超车 | No Overtaking | NO | |
| 禁止车辆停放 | No Parking | NP | |
| 限制标志 | Regulatory Sign | RS | |
| 指示标志 | 直行 | Straight Ahead | SA |
| 向左转弯 | Turn Left | TL | |
| 向右转弯 | Turn Right | TR | |
| 允许掉头 | U turn | UT | |
| 分隔带右侧行驶 | Keep Right | KR | |
| 分隔带左侧行驶 | Keep Left | KL | |
| 人行横道 | Pedestrian Crossing | PC | |
| 机动车行驶 | Motor Vehicles Only | MVO | |
| 非机动车行驶 | Non-Motor Vehicles Only | NMVO | |
| 警告标志 | 交叉口 | Intersection | IN |
| 隧道 | Tunnel | TU | |
| 注意行人 | Caution: Pedestrians | CP | |
| 注意儿童 | Caution: Children | CC | |
| 车道变少 | Lane Reduction | LR |
Table 2
Model parameter setting"
| 参数 | 数值 |
|---|---|
| epochs | 300 |
| batch-size | 16 |
| imgsz | 640 |
| learning Rate | 0.001 |
| Weight_decay | 0.000 5 |
| momentum | 0.937 |
| depth_multiple | 0.33 |
| width_multiple | 0.5 |
Table 3
Effectiveness evaluation of different module combinations"
| YOLOv5s | C | G | T | 小目标召回率 | ACS | 分类准确率/% | 收敛时间(300轮)/h |
|---|---|---|---|---|---|---|---|
| √ | 0.793 | 0.45 | 95.2 | 1.863 | |||
| √ | √ | 0.869 | 0.62 | 95.4 | 2.013 | ||
| √ | √ | 0.831 | 0.59 | 95.3 | 2.084 | ||
| √ | √ | 0.820 | 0.46 | 96.1 | 1.681 | ||
| √ | √ | √ | 0.880 | 0.68 | 95.7 | 2.131 | |
| √ | √ | √ | 0.871 | 0.63 | 96.5 | 1.865 | |
| √ | √ | √ | 0.842 | 0.60 | 96.2 | 1.898 | |
| √ | √ | √ | √ | 0.913 | 0.72 | 97.4 | 1.949 |
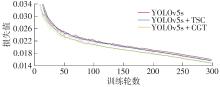
Fig.9
Convergence curves"
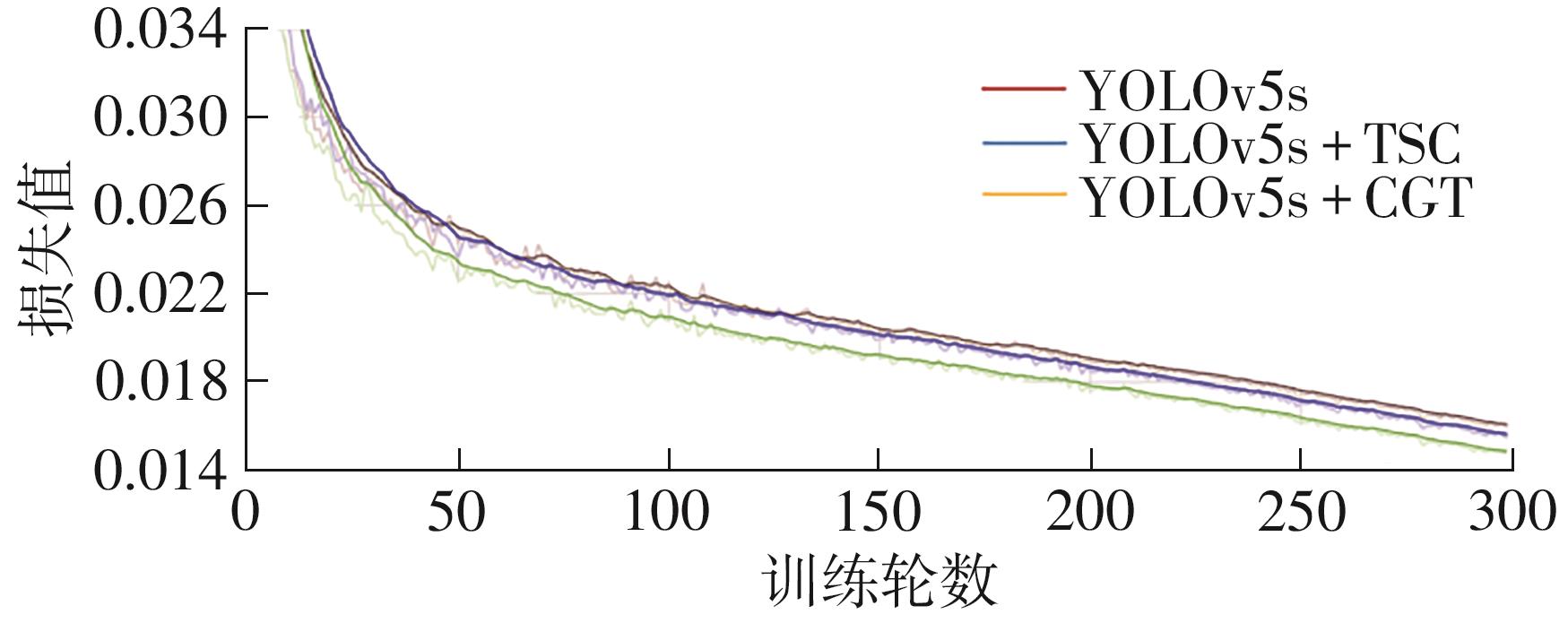
Table 4
Ablation study results on small target traffic sign dataset"
| YOLOv5s | C | G | T | mAP @0.50 | mAP @0.50∶0.95 | 精确率 | 召回率 |
|---|---|---|---|---|---|---|---|
| √ | 0.971 6 | 0.761 8 | 0.965 8 | 0.946 2 | |||
| √ | √ | 0.970 5 | 0.767 3 | 0.969 5 | 0.947 3 | ||
| √ | √ | 0.979 0 | 0.768 3 | 0.969 6 | 0.952 1 | ||
| √ | √ | 0.980 1 | 0.778 0 | 0.968 2 | 0.951 5 | ||
| √ | √ | √ | 0.966 9 | 0.767 8 | 0.972 0 | 0.952 4 | |
| √ | √ | √ | 0.980 5 | 0.781 7 | 0.972 9 | 0.953 5 | |
| √ | √ | √ | 0.981 1 | 0.784 6 | 0.974 8 | 0.953 3 | |
| √ | √ | √ | √ | 0.982 3 | 0.787 8 | 0.974 7 | 0.957 9 |
Table 5
Comparison of different detection algorithms"
| 模型 | mAP@0.50∶0.95 | 精确率 | 召回率 |
|---|---|---|---|
| Faster R-CNN | 0.759 7 | 0.954 3 | 0.942 8 |
| YOLOv5s | 0.761 8 | 0.965 8 | 0.946 2 |
| YOLOv8s | 0.773 5 | 0.969 1 | 0.949 7 |
| NanoDet-Plus | 0.761 2 | 0.959 1 | 0.937 6 |
| RT-DETR-Nano | 0.778 9 | 0.969 8 | 0.951 3 |
| CGT-YOLO | 0.787 8 | 0.974 7 | 0.957 9 |
Table 6
Comparison of improved model operational parameters"
| 模型 | 预处理/ms | 推理时间/ms | 后处理/ms | FPS/(帧·s-1) |
|---|---|---|---|---|
| YOLOv5s | 0.4 | 13.0 | 5.7 | 76.9 |
| CGT-YOLO | 0.5 | 13.8 | 6.1 | 72.5 |
Table 7
Small target traffic sign recognition results for the improved model"
| 模型 | 精确率 | 召回率 | MR/% | FPR/% | 准确率/% |
|---|---|---|---|---|---|
| YOLOv5s | 0.812 | 0.793 | 27.8 | 18.9 | 80.5 |
| CGT-YOLO | 0.885 | 0.913 | 15.7 | 7.3 | 90.1 |

Fig.10
Visual result diagram"

Table 8
Quantitative analysis of different scenarios"
| 场景 | AC | AI | DSR/% | |||
|---|---|---|---|---|---|---|
| YOLOv5s | CGT-YOLO | YOLOv5s | CGT-YOLO | YOLOv5s | CGT-YOLO | |
| 1 | 0.62 | 0.69 | 0.71 | 0.77 | 84.3 | 91.5 |
| 2 | 0.64 | 0.71 | 0.70 | 0.76 | 85.2 | 92.4 |
| 3 | 0.61 | 0.69 | 0.68 | 0.75 | 83.3 | 90.8 |
| 4 | 0.65 | 0.72 | 0.72 | 0.78 | 86.1 | 93.2 |
| [1] | NANDI D, SAIF A F M S, PAUL P,et al .Traffic sign detection based on color segmentation of obscure image candidates:a comprehensive study[J].International Journal of Modern Education and Computer Science,2018,10(6):35-46. |
| [2] | GÓMEZ-MOEENO H, MALDONADO-BASCÓN S, GIL-JIMÉNEZ P,et al .Goal evaluation of segmentation algorithms for traffic sign recognition[J].IEEE Transactions on Intelligent Transportation Systems,2010,11(4):917-930. |
| [3] | WALI S B, HANNAN M A, HUSSAIN A,et al .An automatic traffic sign detection and recognition system based on colour segmentation,shape matching,and SVM[J].Mathematical Problems in Engineering,2015,DOI:10.1155/2015/250461 . |
| [4] | TABERNIK D, SKOČAJ D .Deep learning for large-scale traffic-sign detection and recognition[J].IEEE Transactions on Intelligent Transportation Systems,2019,21(4):1427-1440. |
| [5] | AYACHI R, AFIF M, SAID Y,et al .Traffic signs detection for real-world application of an advanced driving assisting system using deep learning[J].Neural Processing Letters,2020,51(1):837-851. |
| [6] | AHMED S, KAMAL U, HASAN M K .DFR-TSD:a deep learning based framework for robust traffic sign detection under challenging weather conditions[J].IEEE Transactions on Intelligent Transportation Systems,2021,23(6):5150-5162. |
| [7] | 马鸽,李洪伟,严梓维,等 .基于多注意力的改进YOLOv5s小目标检测算法[J].工程科学学报,2024,46(9):1647-1658. |
| MA Ge, LI Hongwei, YAN Ziwei,et al .Improved small target detection algorithm based on multiattention and YOLOv5s for traffic sign recognition[J].Chinese Journal of Engineering,2024,46(9):1647-1658. | |
| [8] | 胡均平,王鸿树,戴小标,等 .改进YOLOv5的小目标交通标志实时检测算法[J].计算机工程与应用,2023,59(2):185-193. |
| HU Junping, WANG Hongshu, DAI Xiaobiao,et al .Real-time detection algorithm for small-target traffic signs based on improved YOLOv5[J].Computer Engineering and Applications,2023,59(2):185-193. | |
| [9] | 罗玉涛,高强 .基于通道注意力和特征增强的交通标志检测[J].华南理工大学学报(自然科学版),2023,51(12):64-72. |
| LUO Yutao, GAO Qiang .Traffic sign detection based on channel attention and feature enhancement[J].Journal of South China University of Technology (Natural Science Edition),2023,51(12):64-72. | |
| [10] | 郭君斌,于琳,于传强 .改进YOLOv5s算法在交通标志检测识别中的应用[J].国防科技大学学报,2024,46(6):123-130. |
| GUO Junbin, YU Lin, YU Chuanqiang .Application of improved YOLOv5s algorithm in traffic sign detection and recognition[J].Journal of National University of Defense Technology,2024,46(6):123-130. | |
| [11] | WANG J, CHEN Y, CAO M,et al .Improved YOLOv5 network for real-time multi-scale traffic sign detection[J].Neural Computing and Applications,2023,35(10):7853-7865. |
| [12] | MAHAUR B, MISHRA K K .Small-object detection based on YOLOv5 in autonomous driving systems[J].Pattern Recognition Letters,2023,168:115-122. |
| [13] | 孟勃,史伟大 .改进YOLOv7的交通标志识别模型[J].中国图象图形学报,2024,29(9):2737-2752. |
| MENG Bo, SHI Weida .Improved traffic sign recognition model for YOLOv7[J].Journal of Image and Graphics,2024,29(09):2737-2752. | |
| [14] | 田鹏,毛力 .改进YOLOv8的道路交通标志目标检测算法[J].计算机工程与应用,2024,60(8):202-212. |
| TIAN Peng, MAO Li .Improved YOLOv8 object detection algorithm for traffic sign target[J].Computer Engineering and Applications,2024,60(8):202-212. | |
| [15] | MIN W, LIU R, HE D,et al .Traffic sign recognition based on semantic scene understanding and structural traffic sign location[J].IEEE Transactions on Intelligent Transportation Systems,2022,23(9):15794-15807. |
| [16] | YAO Y, HAN L, DU C,et al .Traffic sign detection algorithm based on improved YOLOv4-Tiny[J].Signal Processing:Image Communication,2022,107:116783/1-11. |
| [17] | 高明华,杨璨 .基于改进卷积神经网络的交通目标检测方法[J].吉林大学学报(工学版),2022,52(6):1353-1361. |
| GAO Ming-hua, YANG Can .Traffic target detection method based on improved convolution neural network[J].Journal of Jilin University (Engineering and Technology Edition),2022,52(6):1353-1361. | |
| [18] | 崔静雯,马杰,张宇 .基于多尺度联合权重分配的目标检测算法[J].计算机工程与应用,2022,58(17):101-110. |
| CUI Jingwen, MA Jie, ZHANG Yu .Target detection algorithm based on multi-scale combined weight distribution[J].Computer Engineering and Applications,2022,58(17):101-110. | |
| [19] | XIAO J, ZHAO T, YAO Y,et al .Context augmentation and feature refinement network for tiny object detection[C]∥ Proceedings of International Conference on Learning Representations.[S.l.]:ICLR,2022:25-29. |
| [20] | LIU Y, SHAO Z, HOFFMANN N .Global attention mechanism:retain information to enhance channel-spatial interactions[J].arXiv preprint:2112.05561,2021. |
| [21] | ZHUANG J, QIN Z, YU H,et al .Task-specific context decoupling for object detection[J].arxiv preprint arxiv:,2023. |
| [22] | 翁俊辉,成乐,黄曼莉,等 .基于CS-YOLOv5s的无人机航拍图像小目标检测[J].电子测量技术,2024,47(7):157-162. |
| WENG Junhui, CHENG Le, HUANG Manli,et al .Small target detection for UAV aerial images based on CS-YOLOv5s[J].Electronic Measurement Techno-logy,2024,47(7):157-162. | |
| [23] | 祝江,魏汉迪,肖龙飞,等 .通航场景下的海上目标检测算法[J].船舶工程,2024,46(12):93-100. |
| ZHU Jiang, WEI Handi, XIAO Longfei,et al .Algorithms for maritime target detection and recognition in navigation scenes[J].Ship Engineering,2024,46(12):93-100. | |
| [24] | 谢竞,邓月明,王润民 .改进YOLOv8s的交通标志检测算法[J].计算机工程,2024,50(11):338-349. |
| XIE Jing, DENG Yueming, WANG Runmin .Improved traffic sign detection algorithm based on YOLOv8s[J].Computer Engineering,2024,50(11):338-349. | |
| [25] | 赵会鹏,曹景胜,潘迪敬,等 .改进YOLOv8算法的交通标志小目标检测[J].现代电子技术,2024,47(20):141-147. |
| ZHAO Huipeng, CAO Jingsheng, PAN Dijing,et al .Traffic sign small target detection based on improved YOLOv8 algorithm[J].Modern Electronics Technique,2024,47(20):141-147. | |
| [26] | 任安虎,姜子渊,马晨浩 .基于改进YOLOv5s的道路裂缝检测算法[J].激光杂志,2024,45(4):88-94. |
| REN Anhu, JIANG Ziyuan, MA Chenhao .Road crack detection algorithm based on improved YOLOv5s[J].Laser Journal,2024,45(4):88-94. |
| [1] | ZHOU Xuan, LI Kexin, GUO Zixuan, YU Zhuliang, YAN Junwei, CAI Panpan. Short-Term Power Load Multi-Step Forecasting for Commercial Building Based on Improved Informer [J]. Journal of South China University of Technology(Natural Science Edition), 2026, 54(1): 42-52. |
| [2] | TANG Lili, LIU Yiqi. A Lightweight Multivariate Time Series Prediction Method for Wastewater Treatment [J]. Journal of South China University of Technology(Natural Science Edition), 2026, 54(1): 60-69. |
| [3] | CAO Ruifen, HU Weiling, LI Qiangsheng, BIN Yannan, ZHENG Chunhou. Prediction Method of IL-6 Inducing Peptides Based on Graph Neural Network [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(5): 109-117. |
| [4] | WANG Qingrong, WANG Junjie, ZHU Changfeng, HAO Fule. Carbon Emission Prediction in Transportation Industry Based on SD-ISSA-DALSTM [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(5): 66-81. |
| [5] | HOU Yue, YIN Jie, ZHANG Zhihao, LU Keke. A Spatiotemporal Heterogeneous Two-Stage Fusion Network for Traffic Flow Prediction [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(5): 82-93. |
| [6] | HU Yongjian, ZHUO Sichao, LIU Beibei, WANG Yufei, LI Jicheng. Improvement of Cross-Dataset Performance of Face Forgery Detection Based on Multi-Scale Spatiotemporal Features and Tampering Probabilities [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(6): 110-119. |
| [7] | ZHOU Lang, FAN Kun, QU Hua, et al. Forest Fire Recognition by Improved EfficientNet-E Model Based on ECA Attention Mechanism [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(2): 42-49. |
| [8] | YANG Chunling, CHEN Wenjun, LIU Jiahui. Feature-Space Optimization-Inspired and Multi-Hypothesis Cross-Attention Reconstruction Neural Network for Video Compressive Sensing [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(10): 9-21. |
| [9] | QIANG Ruiru, ZHAO Xiaoqiang. A Small Sample Rolling Bearing Fault Diagnosis Method Based on Gramian Angular Difference Field and Generative Adversarial Network [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(10): 64-75. |
| [10] | TIAN Sheng, SONG Lin, ZHAO Kailong. Point Cloud Classification Based on Offset Attention Mechanism and Multi-Feature Fusion [J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(1): 100-109. |
| [11] | LI Jiachun, LI Bowen, LIN Weiwei. AdfNet: An Adaptive Deep Forgery Detection Network Based on Diverse Features [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(9): 82-89. |
| [12] | LI Haiyan, YIN Haolin, LI Peng, et al.. Image Inpainting Algorithm Based on Dense Feature Reasoning and Mix Loss Function [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(9): 99-109. |
| [13] | GUO Enqiang, FU Xinsha. Dropped Object Detection Method Based on Feature Similarity Learning [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(6): 30-41. |
| [14] | LIU Yupeng, ZHANG Lei. Cognitive Diagnosis Model Integrating Forgetting and Importance of Knowledge Points [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(5): 54-62. |
| [15] | LU Lu, LAI Jinxiong. Smart Contract Vulnerability Detection Method Based on Capsule Network and Attention Mechanism [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(5): 36-44. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||