Journal of South China University of Technology(Natural Science Edition) ›› 2023, Vol. 51 ›› Issue (7): 21-33.doi: 10.12141/j.issn.1000-565X.220626
Special Issue: 2023年机械工程
• Mechanical Engineering • Previous Articles Next Articles
Small-Sample Fault Diagnosis Method Based on Multi-Head Convolution and Differential Self-Attention
CHEN Xindu1 FU Zhisen1,2,3 WU Zhiheng2,3 CHEN Qiyu2,3 GUO Weike2,3
- 1.School of Mechanical and Electrical Engineering,Guangdong University of Technology,Guangzhou 510006,Guangdong,China
2.Intelligent Manufacturing Research Institute,Guangdong Academy of Sciences,Guangzhou 510030,Guangdong,China
3.Guangdong Provincial Key Laboratory of Modern Control Technology,Guangzhou 510030,Guangdong,China
-
Received:2022-09-26Online:2023-07-25Published:2023-02-20 -
Contact:陈新度(1967-),男,博士,教授,博士生导师,主要从事智能装备、制造系统建模以及仿真优化等研究。 E-mail:chenxindu@gdut.edu.cn -
About author:陈新度(1967-),男,博士,教授,博士生导师,主要从事智能装备、制造系统建模以及仿真优化等研究。 -
Supported by:the Guangdong Province Key Field R&D Program(2019B090917004)
CLC Number:
Cite this article
CHEN Xindu, FU Zhisen, WU Zhiheng, et al.. Small-Sample Fault Diagnosis Method Based on Multi-Head Convolution and Differential Self-Attention[J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(7): 21-33.
share this article
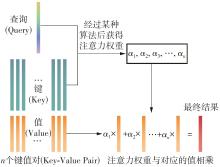
Fig.1
Schematic diagram of attention mechanism"
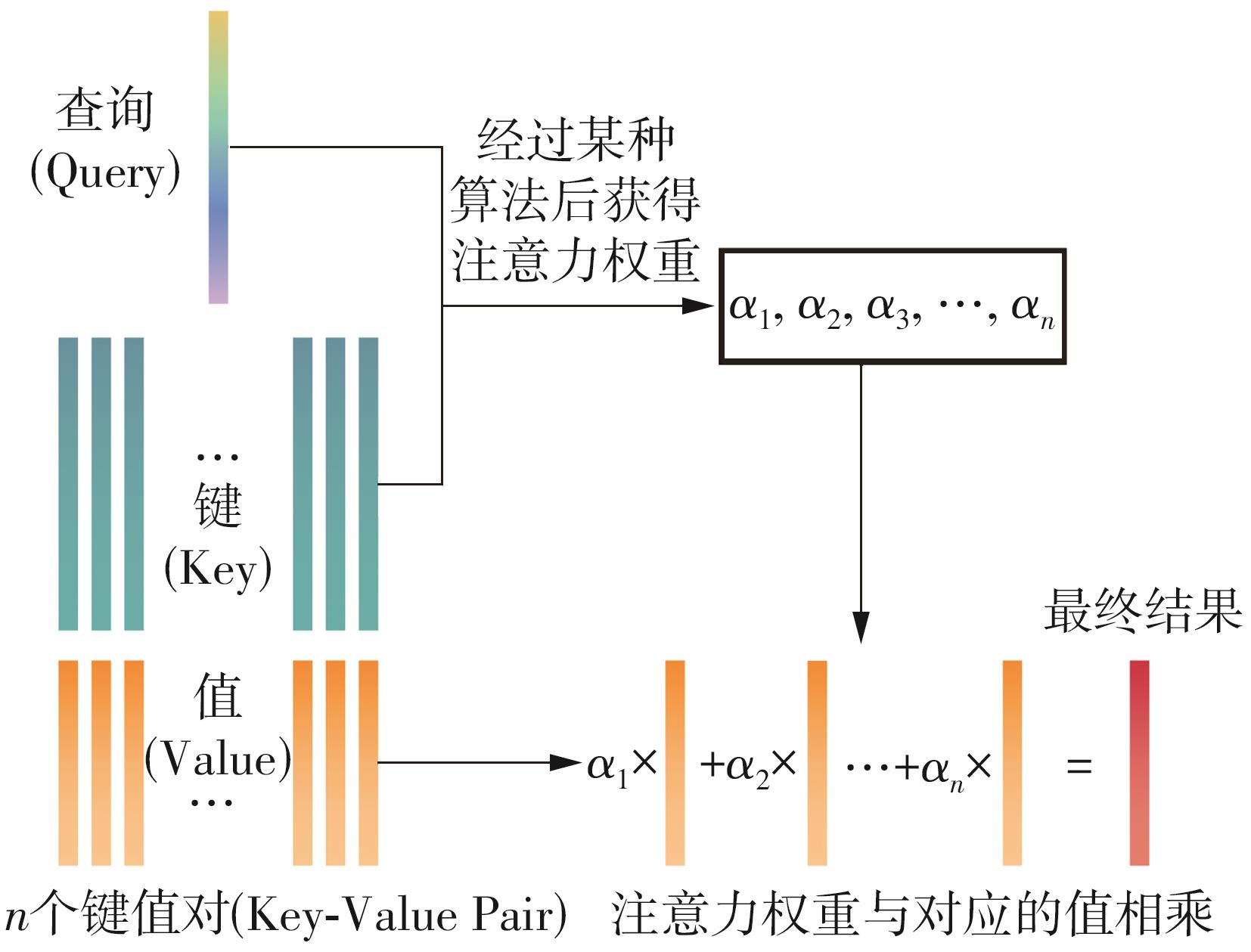
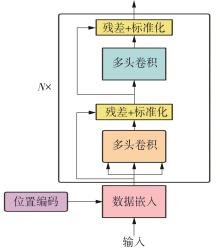
Fig.2
Transformer model structure[12]"
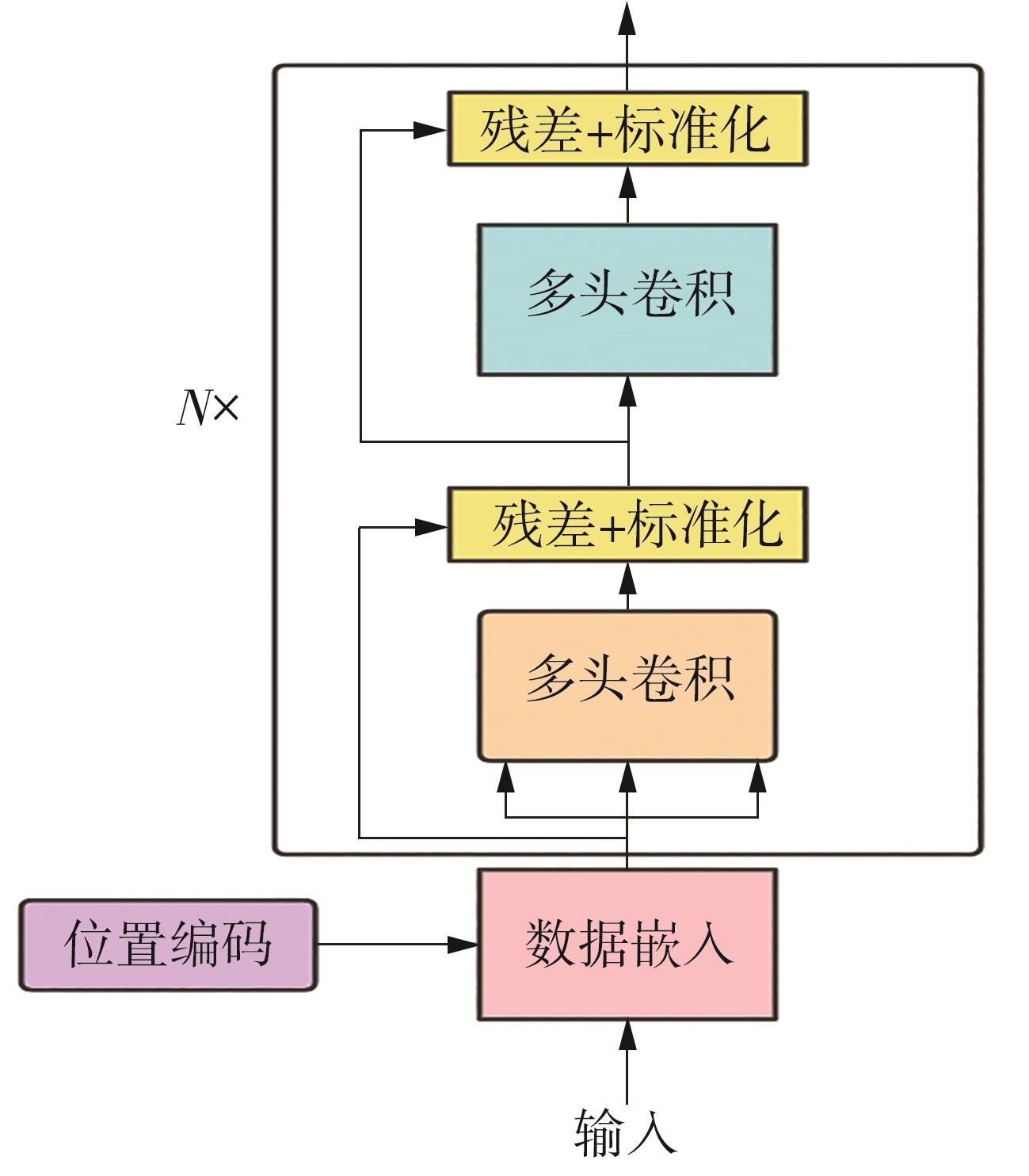
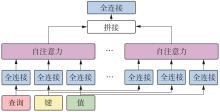
Fig.3
Common model structure of multi-head attention"
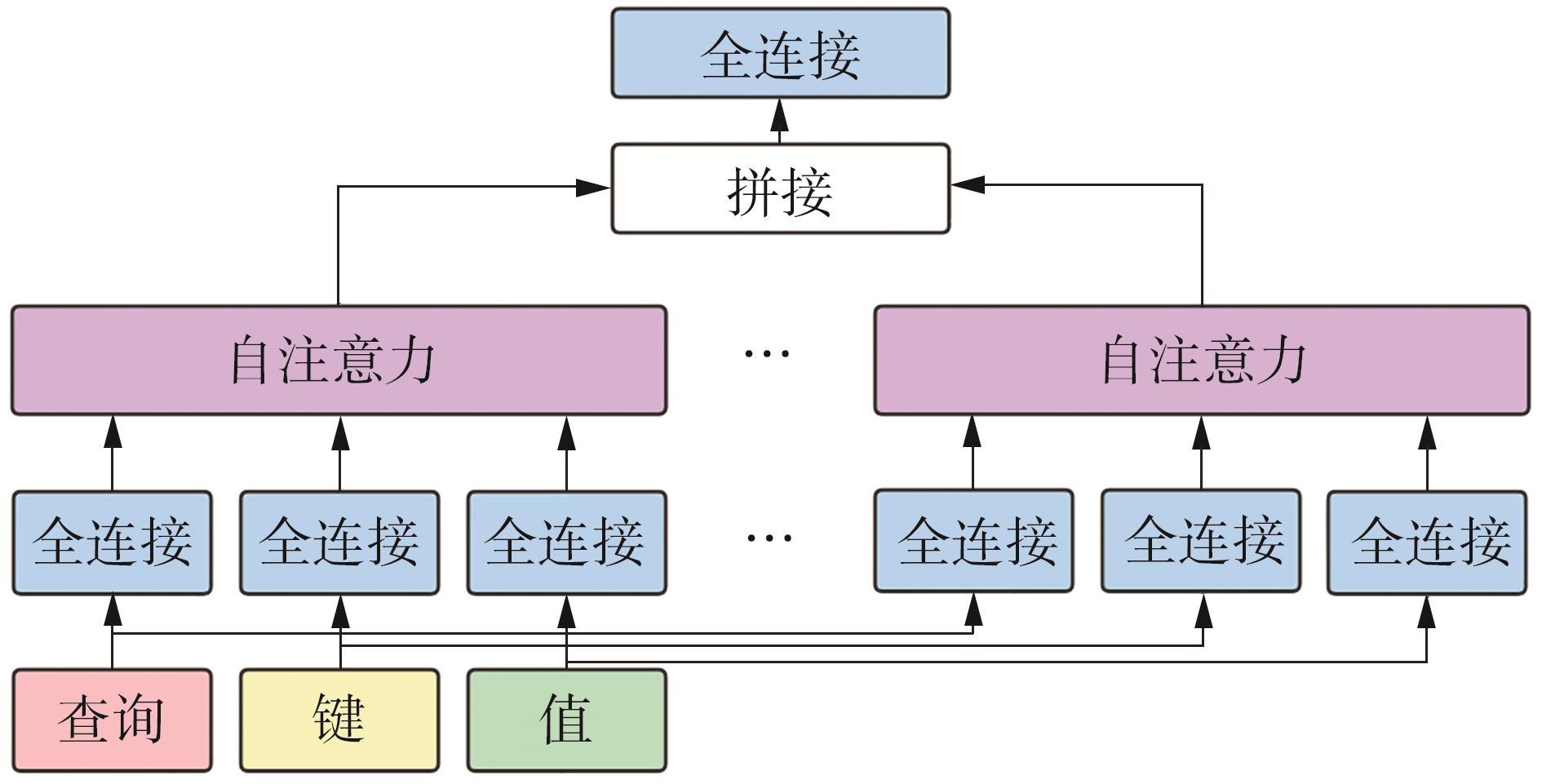
Fig.4
Network structure of Transformer model based on multi-head convolution and differential self-attention"
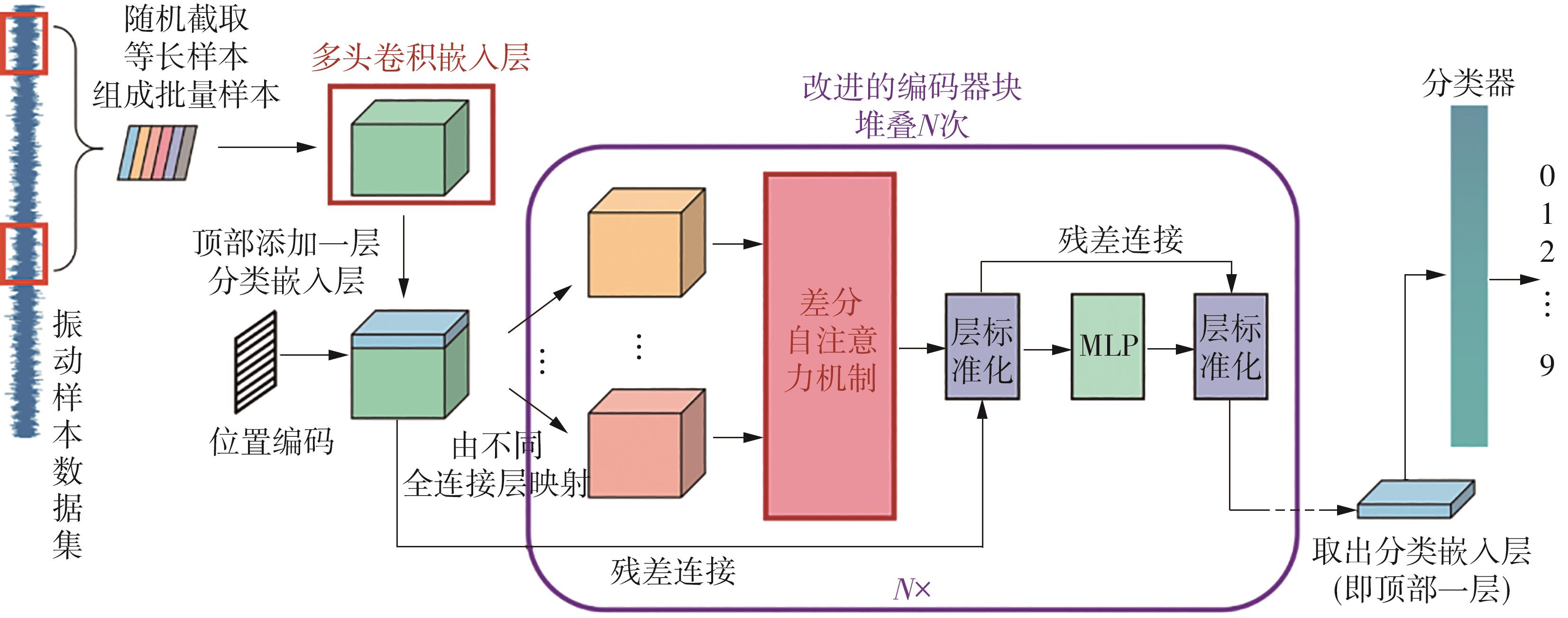
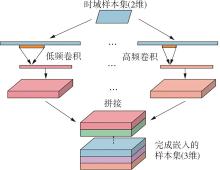
Fig.5
Process of multi-head convolution embedding layer"
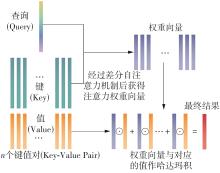
Fig.6
Schematic diagram of differential self-attention"
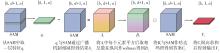
Fig.7
Algorithm process of differential self-attention"
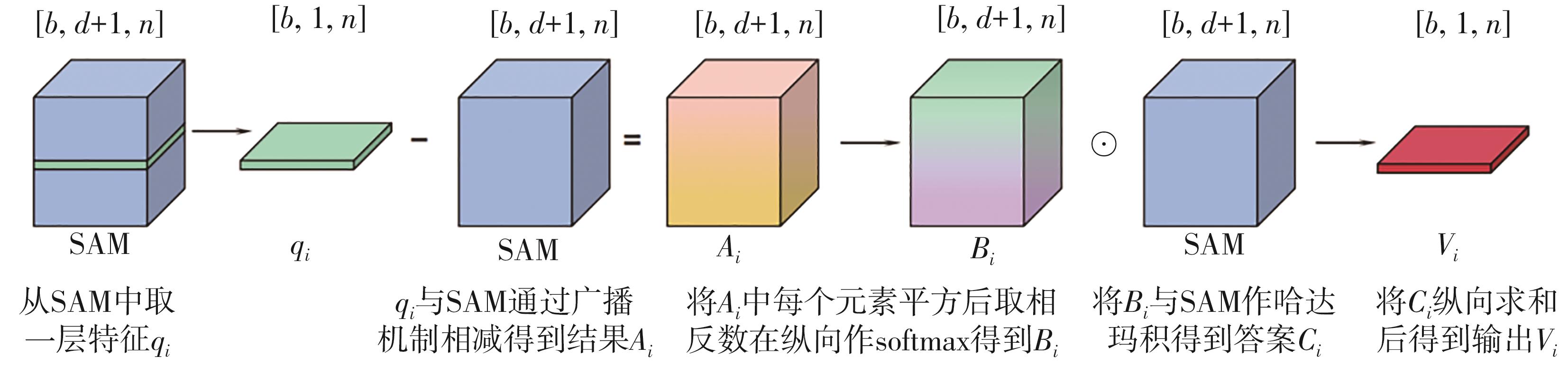
Fig.8
Image of ReLU and GeLU functions[14]"
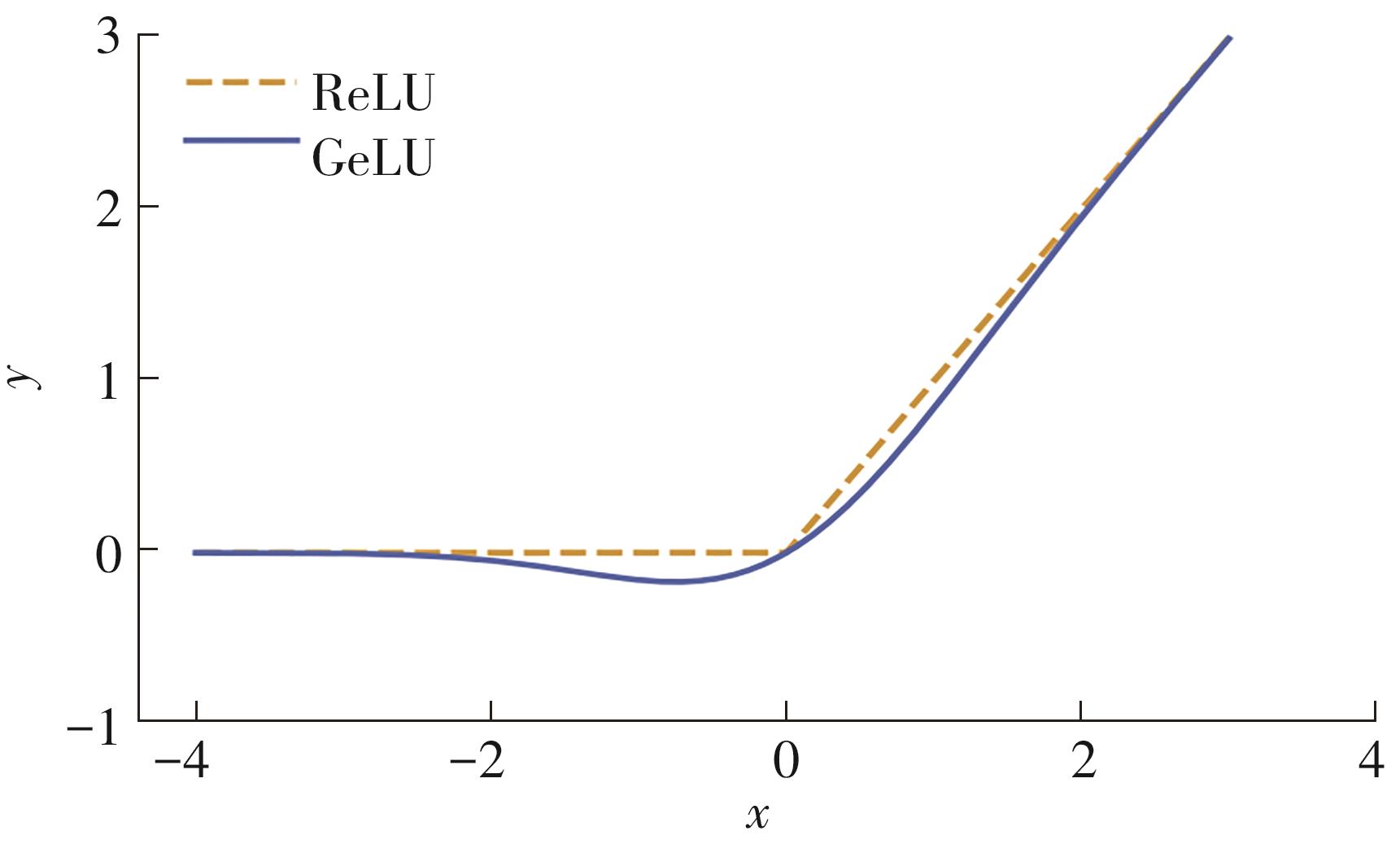
Table 1
Comparison experiment results of multi-head convolution hyperparameter"
| 编号 | 头数 | 卷积核大小 | 卷积层数 | 步长 | 输出通道 | 训练准确率/% | 测试准确率/% |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 21,15 | 3 | 1,1,1 | 80,70,48 | 96.00 | 94.45 |
| 2 | 2 | 21,11 | 4 | 2,2,2,2 | 80,70,48,48 | 96.80 | 96.02 |
| 3 | 2 | 21,7 | 4 | 4,2,2,2 | 80,70,48,48 | 97.10 | 95.73 |
| 4 | 3 | 21,15,11 | 3 | 1,1,1 | 80,70,32 | 99.14 | 98.85 |
| 5 | 3 | 21,15,7 | 4 | 2,2,2,2 | 80,70,32,32 | 99.83 | 99.60 |
| 6 | 3 | 21,15,11 | 4 | 4,2,2,2 | 80,70,32,32 | 99.70 | 99.78 |
| 7 | 4 | 21,15,11,7 | 3 | 1,1,1 | 80,70,24 | 98.90 | 98.54 |
| 8 | 4 | 21,15,11,7 | 4 | 2,2,2,2 | 80,70,24,24 | 99.37 | 99.21 |
| 9 | 4 | 21,15,11,7 | 4 | 4,2,2,2 | 80,70,24,24 | 99.28 | 99.46 |
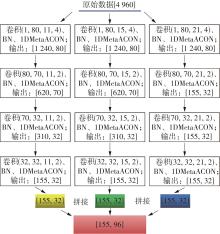
Fig.9
Optimal structure and parameters of multi-head convolutional layer"
Table 2
Comparison of the results of embedding methods"
| 嵌入法 | 训练准确率/% | 测试准确率/% |
|---|---|---|
| SSWT | 69.95 | 65.32 |
| EMD | 63.88 | 67.67 |
| 多头卷积嵌入法 | 99.70 | 99.78 |
Table 3
Results of control experiments of main hyperparameters"
| 实验编号 | 头数 | 块数 | 批量大小 | 样本长度 | 嵌入维度 | 训练准确率/% | 测试准确率/% |
|---|---|---|---|---|---|---|---|
| 1 | 3 | 2 | 150 | 1 024 | 64 | 95.97 | 94.51 |
| 2 | 3 | 4 | 100 | 2 480 | 96 | 98.86 | 96.72 |
| 3 | 3 | 3 | 150 | 4 960 | 96 | 97.98 | 96.90 |
| 4 | 4 | 2 | 150 | 1 024 | 64 | 99.20 | 95.84 |
| 5 | 4 | 4 | 100 | 2 480 | 96 | 99.43 | 98.40 |
| 6 | 4 | 3 | 150 | 4 960 | 96 | 100.00 | 99.78 |
| 7 | 5 | 2 | 150 | 1 024 | 64 | 97.50 | 89.37 |
| 8 | 5 | 4 | 100 | 2 480 | 96 | 97.99 | 90.61 |
| 9 | 5 | 3 | 150 | 4 960 | 96 | 98.91 | 92.46 |
Table 4
Selection results of major hyperparameters"
| 超参数 | 取值 | 超参数 | 取值 | ||
|---|---|---|---|---|---|
| 批量大小 | 150 | 编码器堆叠数目 | 3 | ||
| 初始学习率 | 0.001 | Dropout | 0.1 | ||
| 权重衰减 | 0.000 1 | 卷积头数 | 3 | ||
| 样本长度 | 4 960 | 卷积核尺寸 | 21,15,11 | ||
| 训练数据尺寸 | [156,96] | 分类器神经元数 | 60,10 | ||
| 注意力头数 | 4 | ||||
Table 5
Structure and parameters of the comparison model"
| 模型 | 结构 | 超参数 |
|---|---|---|
| DNN | Conv1d(192,60) linear1(960,480) linear1(480,240) linear1(240,120) linear1(120,60) | Dropout = 0.1 最大轮次 = 200 批量大小 = 150 激活函数 = GeLU 学习率 = 1×10-3 |
| ResNet-CNN | Conv1d(192,60)×20 ResNet() | |
| GRU | GRU(192,192) linear1(192,60) linear1(60,10) |
Table 6
Effect comparison of the models"
| 模型 | 平均准确率/% | 最大准确率/% | 方差 | 耗时/s |
|---|---|---|---|---|
| MDT | 99.79 | 99.92 | 1.55×10-6 | 881.4 |
| DNN | 84.17 | 96.21 | 9.13×10-3 | 430.8 |
| ResNet-CNN | 89.49 | 97.06 | 1.32×10-4 | 246.7 |
| GRU | 90.86 | 93.94 | 5.25×10-3 | 369.3 |
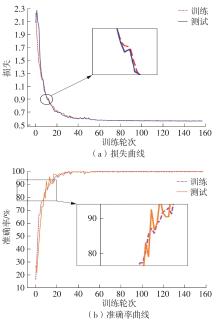
Fig.10
Loss and accuracy curves of MDT"
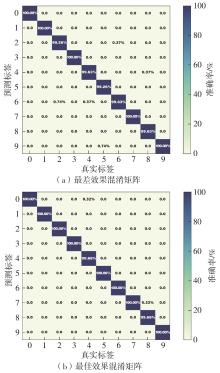
Fig.11
The worst and the best performnce confusion matrix of MDT model"
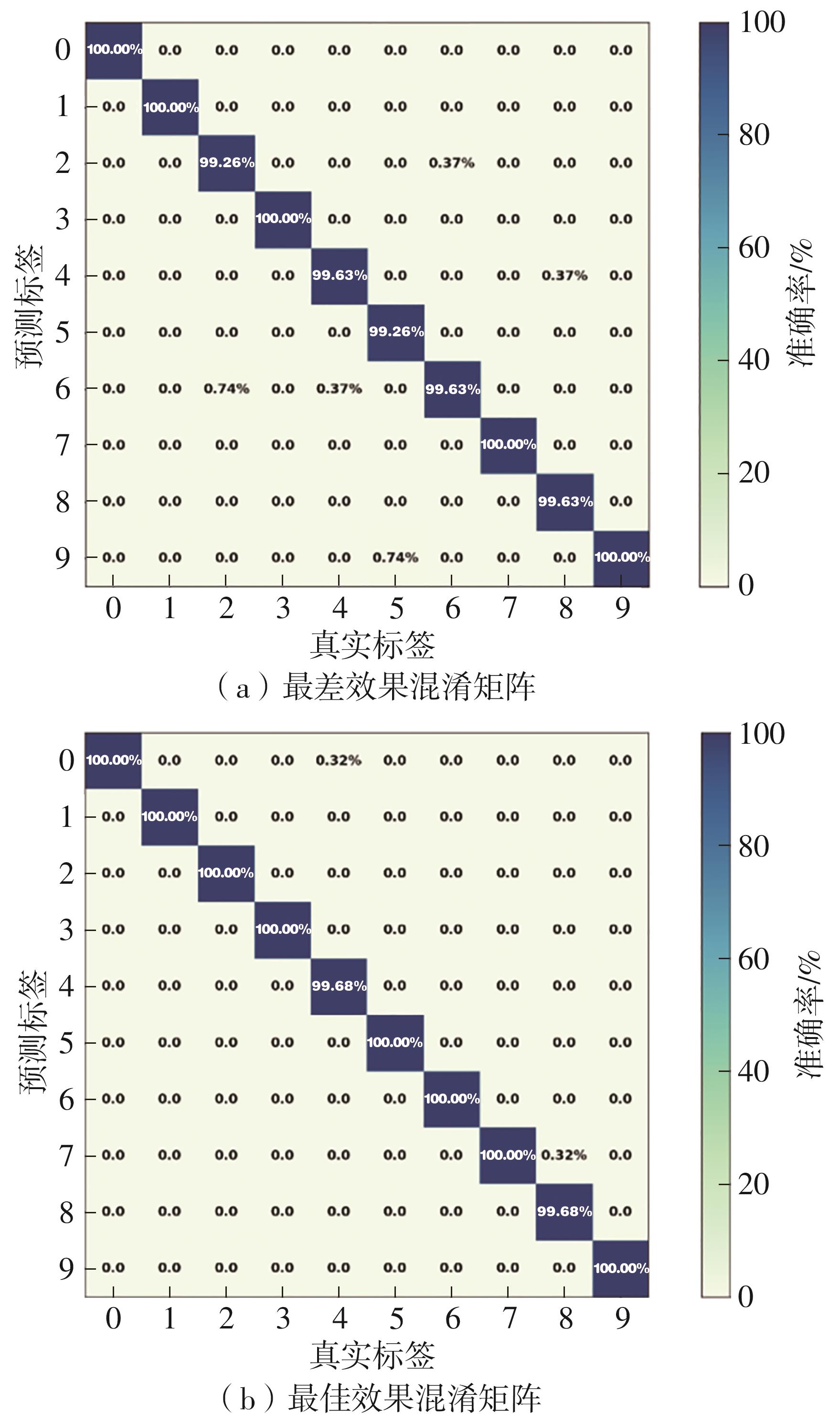
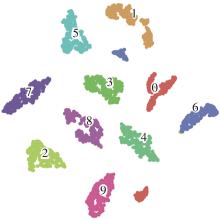
Fig.12
t-SNE plot of MDT terminal output features"
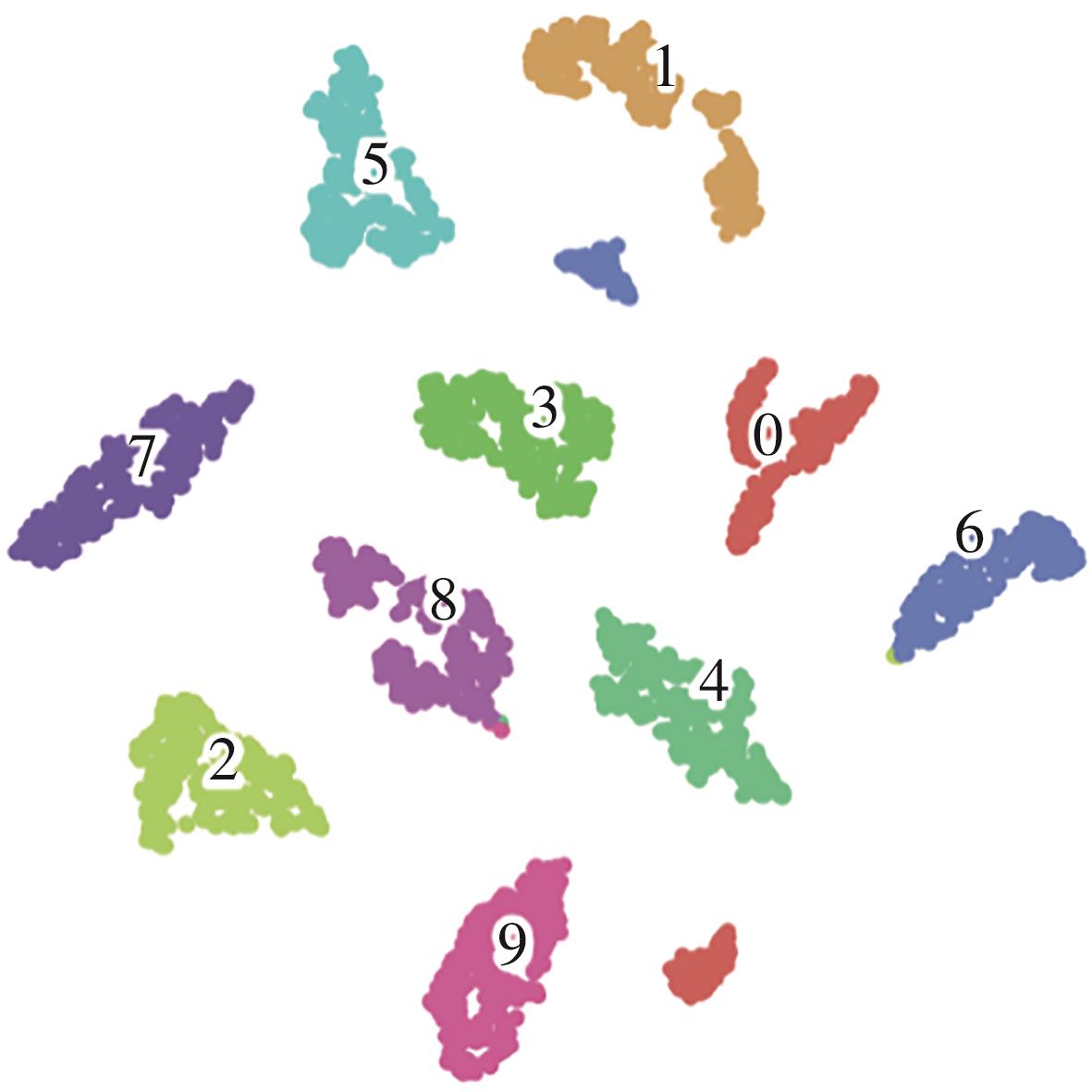

Fig.13
Loss curves, accuracy curves, confusion matrix diagram and T-SNE diagram of GRU"
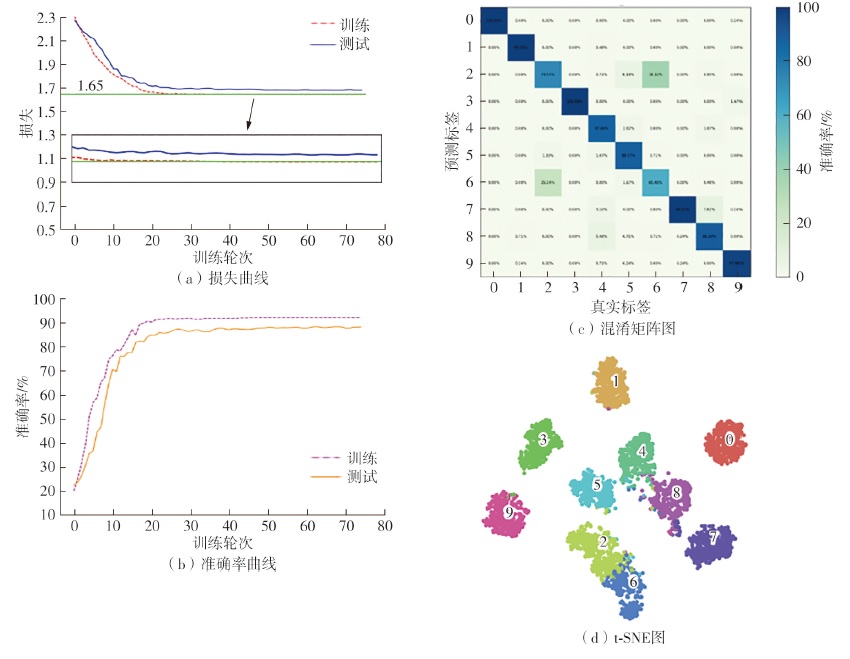
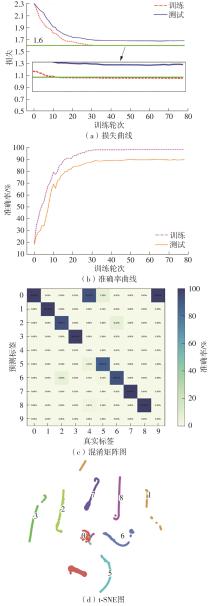
Fig.14
Loss curves, accuracy curves, confusion matrix diagram and T-SNE diagram of DNN"
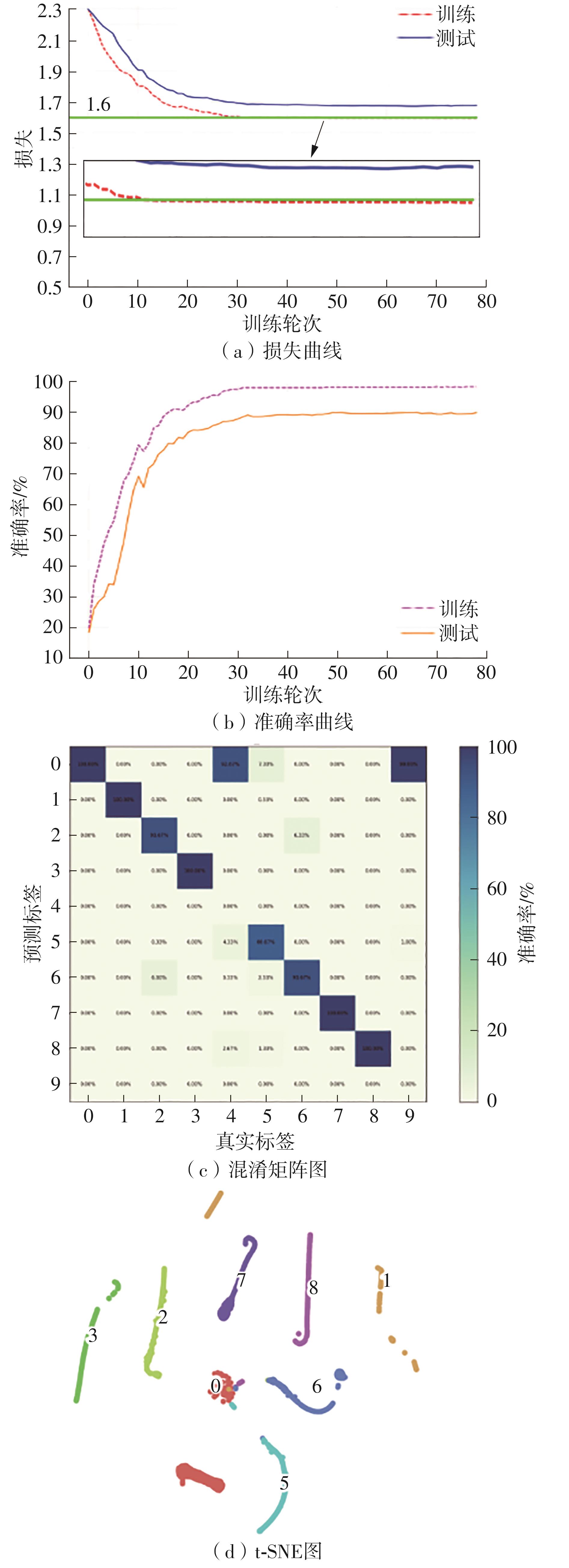
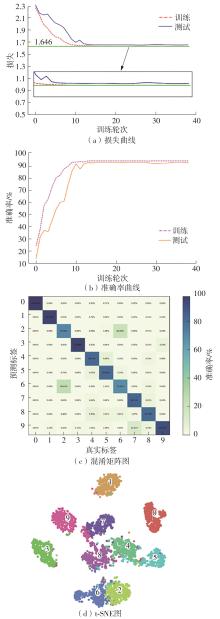
Fig.15
Loss curves, accuracy curves, confusion matrix diagram and T-SNE diagram of ResNet-CNN"
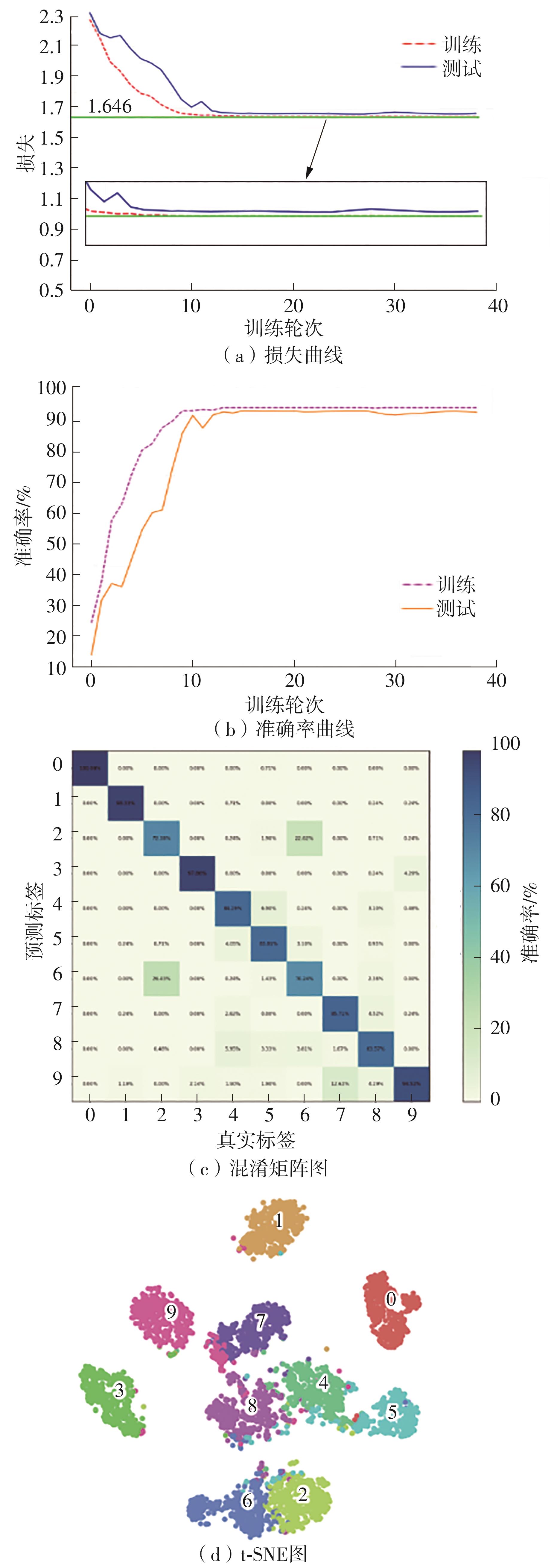
Table 7
Test accuracy of each model under different SNRs"
| SNR/dB | 准确率/% | |||
|---|---|---|---|---|
| MDT | ResNet-CNN | DNN | GRU | |
| -50 | 55.04 | 48.93 | 39.67 | 41.32 |
| -20 | 59.63 | 49.09 | 41.82 | 44.81 |
| -10 | 81.49 | 49.49 | 45.77 | 50.74 |
| -8 | 87.20 | 49.14 | 48.60 | 52.58 |
| -6 | 90.81 | 51.34 | 44.85 | 69.95 |
| -4 | 94.95 | 52.73 | 52.97 | 69.09 |
| -2 | 94.09 | 59.81 | 55.74 | 74.26 |
| 0 | 97.82 | 65.85 | 59.70 | 81.04 |
| 2 | 98.45 | 69.13 | 60.78 | 84.25 |
| 8 | 99.00 | 83.60 | 81.63 | 86.35 |
| 6 | 99.19 | 77.41 | 73.83 | 85.36 |
| 10 | 99.54 | 86.24 | 82.16 | 87.07 |
Table 8
Experimental accuracy of dot product and differential self-attention"
| 组别 | 准确率/% | |||
|---|---|---|---|---|
| 点积训练 | 点积测试 | 差分训练 | 差分测试 | |
| 1 | 24.98 | 26.66 | 80.10 | 83.43 |
| 2 | 92.81 | 93.98 | 92.74 | 93.10 |
| 3 | 95.20 | 79.38 | 88.60 | 88.23 |
| 1 | 赵玉成,陈荣华,马占国 .旋转机械动力辨识与故障诊断技术[M].徐州:中国矿业大学出版社,2008. |
| 2 | SHAO H, JIANG H, ZHANG X,et al .Rolling bearing fault diagnosis using an optimization deep belief network[J].Measurement Science and Technology,2015,26(11):115002. |
| 3 | GOODFELLOW I, POUGET-ABADIE J, MIRZA M,et al .Generative adversarial networks[J].Communications of the ACM,2020,63(11):139-144. |
| 4 | RADFORD A, METZ L, CHINTALA S .Unsupervised representation learning with deep convolutional generative adversarial networks[DB/OL].(2016-01-17)[2022-08-04].. |
| 5 | GULRAJANI I, AHMED F, ARJOVSKY M,et al .Improved training of Wasserstein GANs[C]∥NIPS’17:Proceedings of the 31st International Conference on Neural Information Processing Systems,2017.[S. l.]:[s. n.],2017:5767-5777. |
| 6 | SHEN S, JIN G, GAO K,et al .AE-GAN:adversarial eliminating with GAN[DB/OL].(2017-09-26)[2022-08-04].. |
| 7 | MIRZA M, OSINDERO S .Conditional generative adversarial nets[DB/OL].(2014-11-06)[2022-08-04].. |
| 8 | SAUFI S R, AHMAD Z A B, LEONG M S,et al .Gearbox fault diagnosis using a deep learning model with limited data sample[J].IEEE Transactions on Industrial Informatics,2020,16(10):6263-6271. |
| 9 | LI X, ZHANG W, DING Q .Understanding and improving deep learning-based rolling bearing fault diagnosis with attention mechanism[J].Signal Processing,2019,161:136-154. |
| 10 | ZHANG X, HE C, LU Y,et al .Fault diagnosis for small samples based on attention mechanism[J].Measurement,2022,187:110242. |
| 11 | XIE Z, CHEN J, FENG Y,et al .End to end multi-task learning with attention for multi-objective fault diagnosis under small sample[J].Journal of Manufacturing Systems,2022,62:301-316. |
| 12 | VASWANI A, SHAZEER N, PARMAR N,et al .Attention is all you need[C]∥ Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017).Long Beach:[s. n.],2017. |
| 13 | SHAZEER N, MIRHOSEINI A, MAZIARZ K,et al .Outrageously large neural networks:the sparsely-gated mixture-of-experts layer[DB/OL].(2017-03-04)[2022-08-04].. |
| 14 | DING Y, JIA M, MIAO Q,et al .A novel time-frequency Transformer based on self-attention mechanism and its application in fault diagnosis of rolling bearings[J].Mechanical Systems and Signal Processing,2022,168:108616. |
| 15 | 郑英,金淼,张洪,等 .一种基于一维多路卷积神经网络的故障分类方法:CN110033021A[P].2019-07-19. |
| 16 | DAUBECHIES I, LU J, WU H T .Synchrosqueezed wavelet transforms:an empirical mode decomposition-like tool[J].Applied and Computational Harmonic Analysis,2011,30(2):243-261. |
| 17 | HUANG N E, SHEN Z, LONG S R,et al .The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis[J].Proceedings of the Royal Society of London. Series A:Mathematical,Physical and Engineering Sciences,1998,454(1971):903-995. |
| [1] | ZHAO Rongchao, WU Baili, CHEN Zhuyun, WEN Kairu, ZHANG Shaohui, LI Weihua. Graph Neural Network for Fault Diagnosis with Multi-Scale Time-Spatial Information Fusion Mechanism [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(12): 42-52. |
| [2] | CHEN Zhong, TANG Xin, ZHANG Daming, HE Dongshan, ZHANG Xianmin. Stockwell Transform Combined with Subdomain Adaptation for Escalator Motor Bearing Transfer Diagnosis [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(12): 34-41. |
| [3] | LIU Yiqi, HUANG Zhipeng, YU Guangping, et al. Full Life-cycle Intelligent Detection, Diagnosis and Analysis for Sludge Bulking [J]. Journal of South China University of Technology(Natural Science Edition), 2022, 50(6): 91-99,110. |
| [4] | TANG Hongbin, FU Zheng, DENG Xishu, et al. Fault Diagnosis Method of Piston Pump in Construction Machinery under Variable Load Condition [J]. Journal of South China University of Technology (Natural Science Edition), 2021, 49(2): 110-119. |
| [5] | GUO Mingjun, LI Weiguang, YANG Qijiang, et al. Amplitude Filter Characteristics of PCA and Its Application in Feature Extraction of Rotor [J]. Journal of South China University of Technology (Natural Science Edition), 2020, 48(5): 125-133. |
| [6] | GUO Mingjun, LI Weiguang, YANG Qijiang, et al. Sparse Algorithm-Based Purification of Multi-Condition Axis Trajectory of Large Rotor [J]. Journal of South China University of Technology (Natural Science Edition), 2020, 48(4): 45-53. |
| [7] | ZHOU Xuan, WANG Xiaopei, LIANG Liequan, et al. Random Forests Algorithm-Based Fault Diagnosis for Refrigerant Charge [J]. Journal of South China University of Technology (Natural Science Edition), 2020, 48(2): 16-24. |
| [8] | XU Yuge LAI Chunling LUO Fei . Bagging Ensemble Fault Diagnosis Modeling with Imbalanced classification in Wastewater Treatment Plant [J]. Journal of South China University of Technology (Natural Science Edition), 2018, 46(8): 107-115. |
| [9] | ZHAO De-zun LI jian-yong CHENG Wei-dong. Fault Diagnosis of Rolling Bearing Under Gear Noise Interference and Variable Rotating Speed [J]. Journal of South China University of Technology (Natural Science Edition), 2016, 44(2): 67-73. |
| [10] | XIAO Hong-jun LIU Yi-qi HUANG Dao-ping. Application of Gaussian Process Modeling Method in Industrial Processes [J]. Journal of South China University of Technology (Natural Science Edition), 2016, 44(12): 36-43,52. |
| [11] | He Guo- lin Ding Kang Li Lin- sheng Deng Ren- gang. Vibration Test and Analysis of Transmission Chain of Wind Turbine Based on Double- Elastic Support [J]. Journal of South China University of Technology (Natural Science Edition), 2014, 42(3): 90-97. |
| [12] | Xie Xiao-peng Xiao Hai-bing Feng Wei Huang Bo Ge Shuang. Fault Pattern Recognition of Energy Loss Based on Locally Linear Embedding [J]. Journal of South China University of Technology(Natural Science Edition), 2012, 40(12): 1-6. |
| [13] | Wang Xiao-feng Shen Gui-xiang Zhang Ying-zhi Chen Bing-kun Zheng Shan Liu Wei. Comparison of Parameter Estimation Methods for Reliability Model [J]. Journal of South China University of Technology (Natural Science Edition), 2011, 39(6): 47-52. |
| [14] | Yang Tong-guang Jiang Xing-hua Fu Qiang. Fault Diagnosis for Broken Bar of Speed Sensorless Induction Motor [J]. Journal of South China University of Technology (Natural Science Edition), 2011, 39(10): 152-156. |
| [15] | Wen Fu-shuan Guo Wen-xin Liao Zhi-wei Wei Liu-hong Xin Jian-bo . An Optimization Algorithm for Fault Diagnosis of High-Voltage Transmission Lines Based on Waveform Matching [J]. Journal of South China University of Technology (Natural Science Edition), 2010, 38(7): 56-61,83. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||