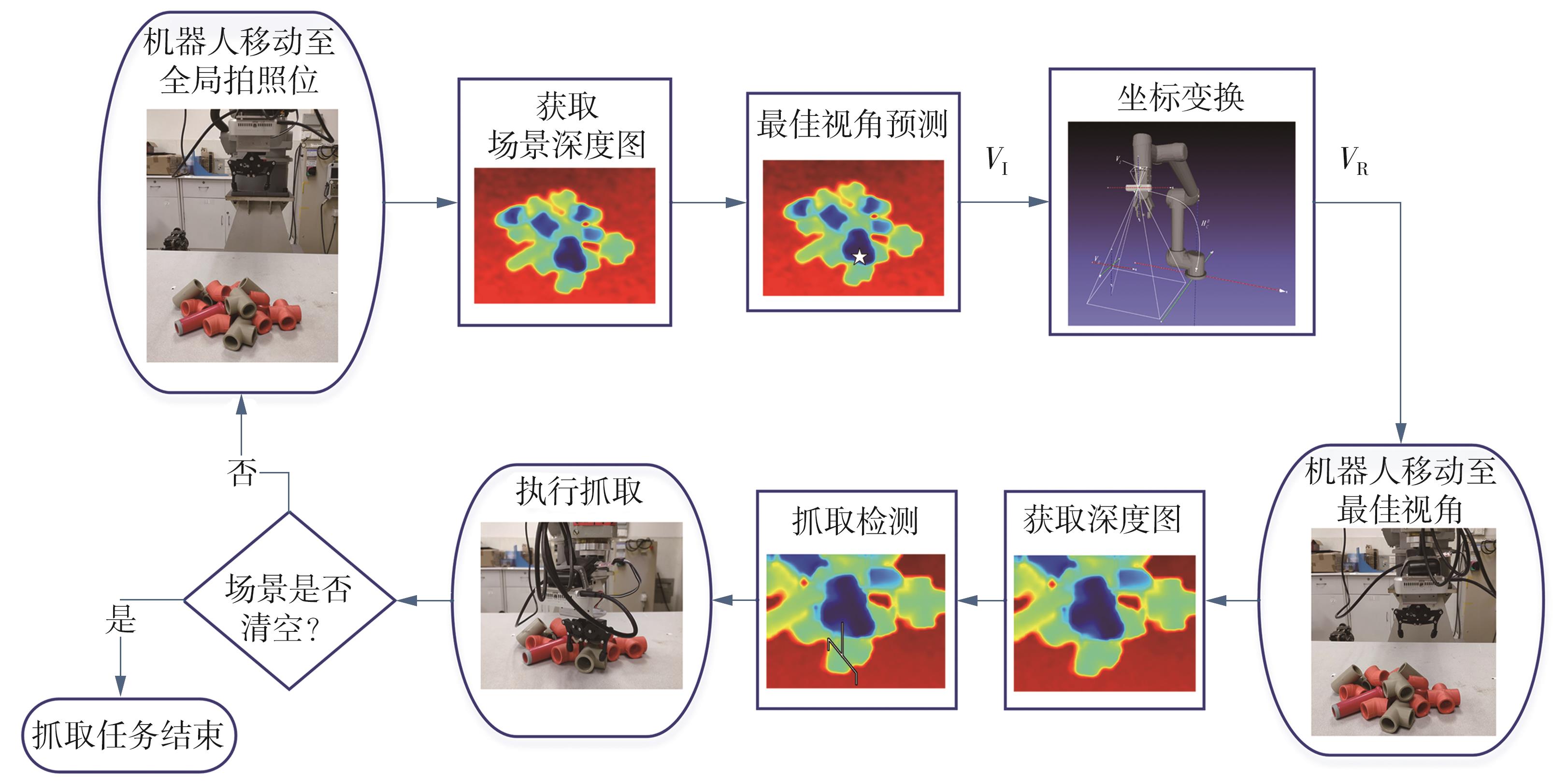
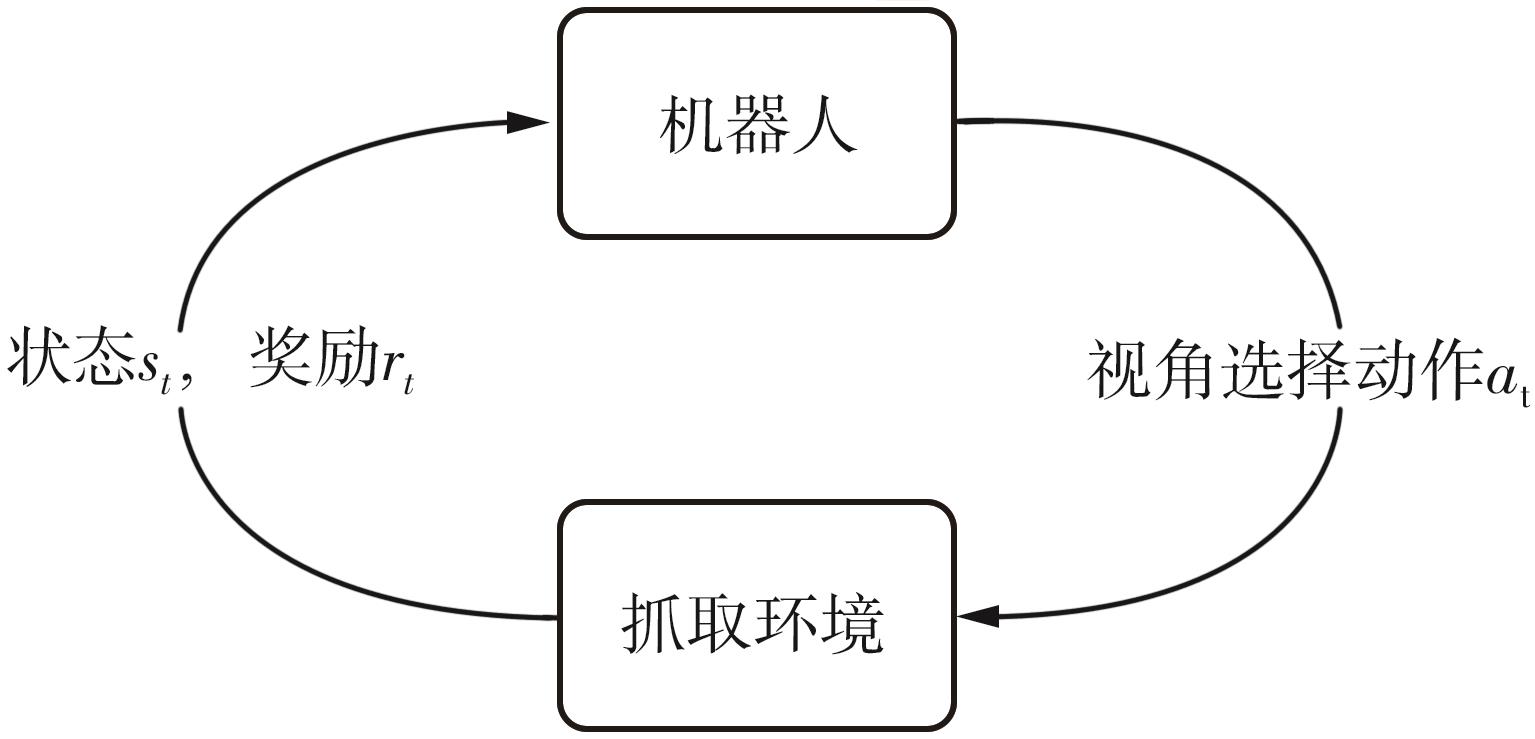
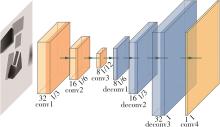
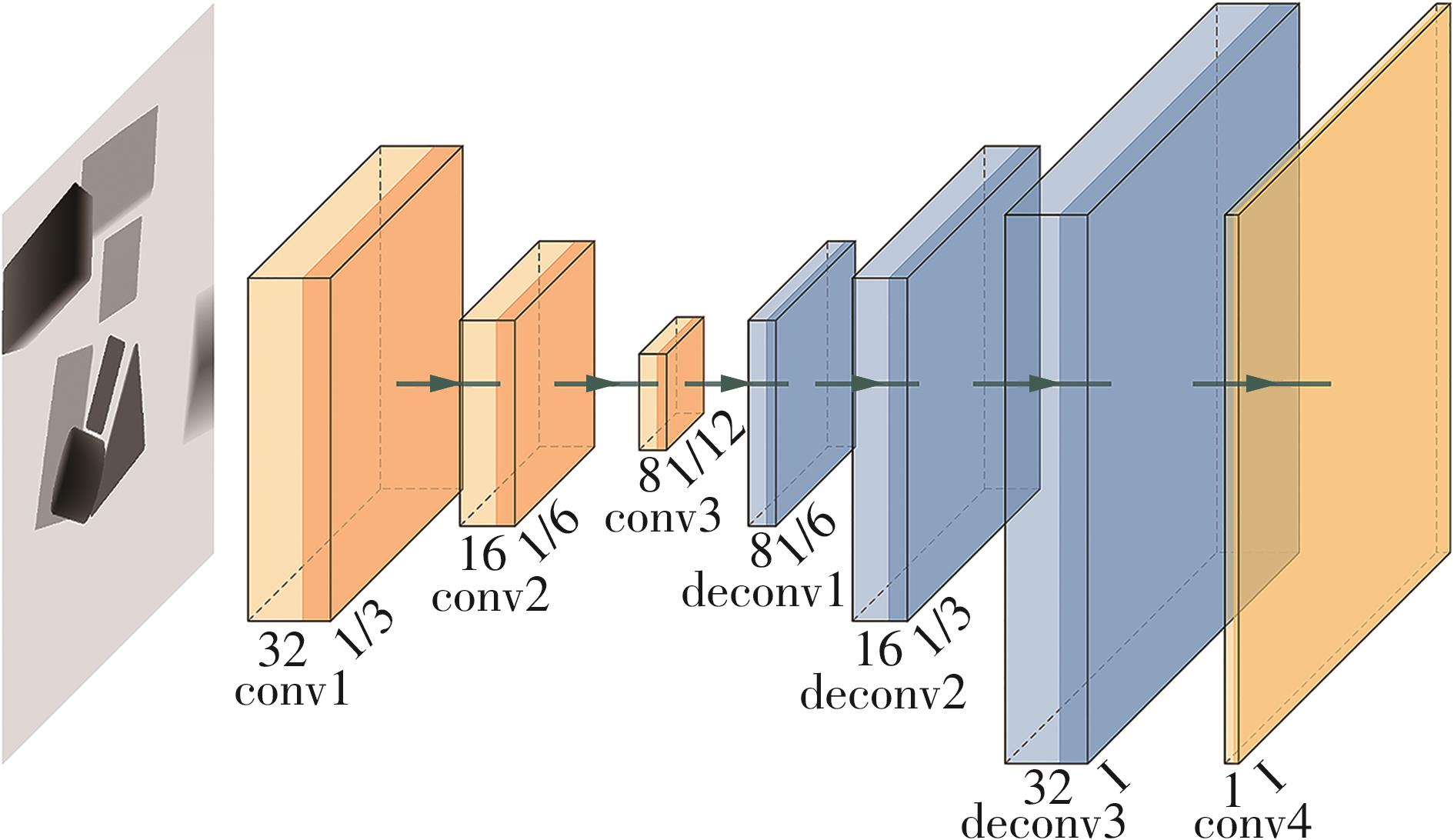
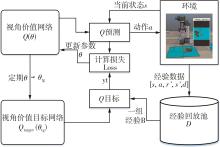
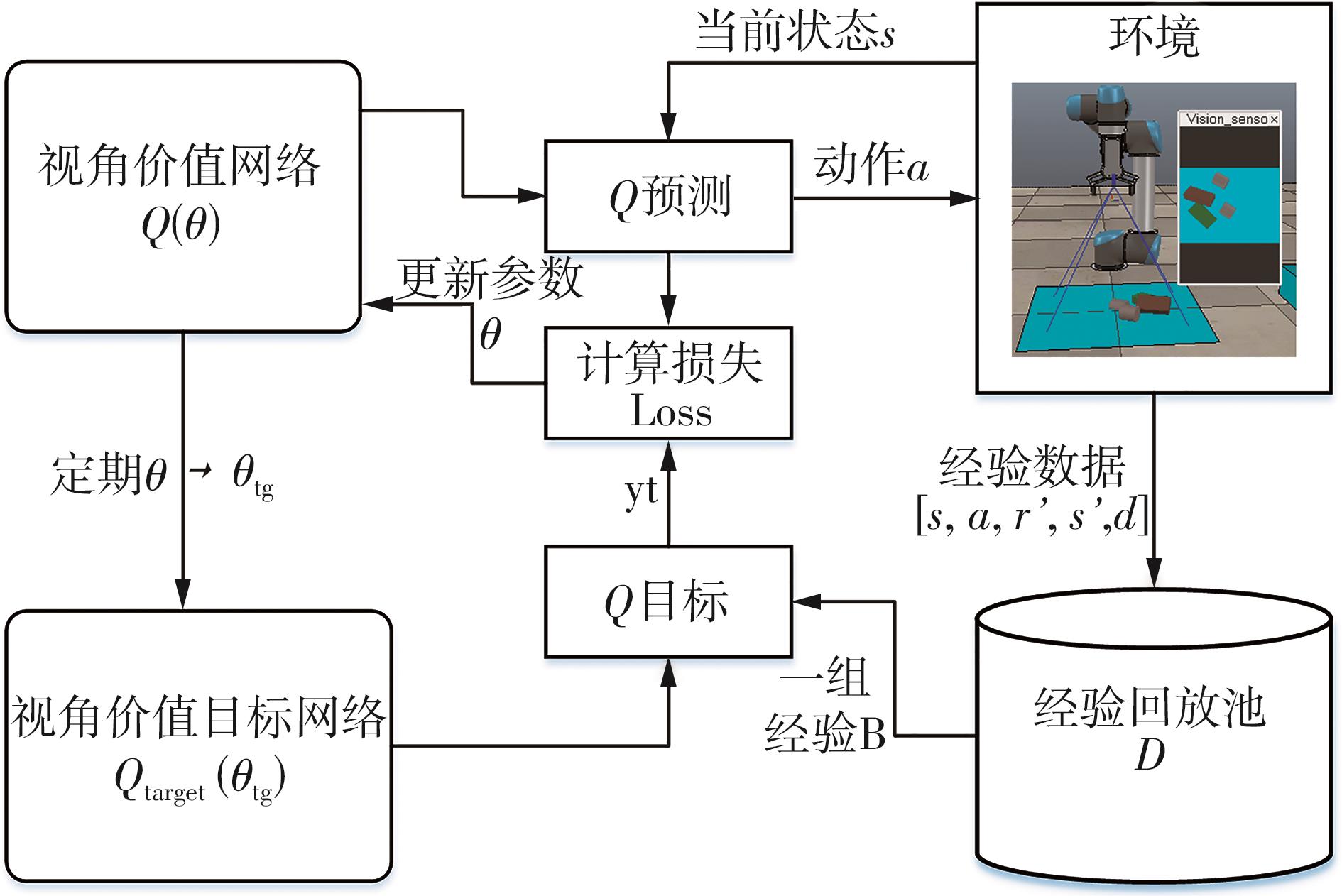
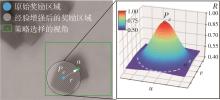
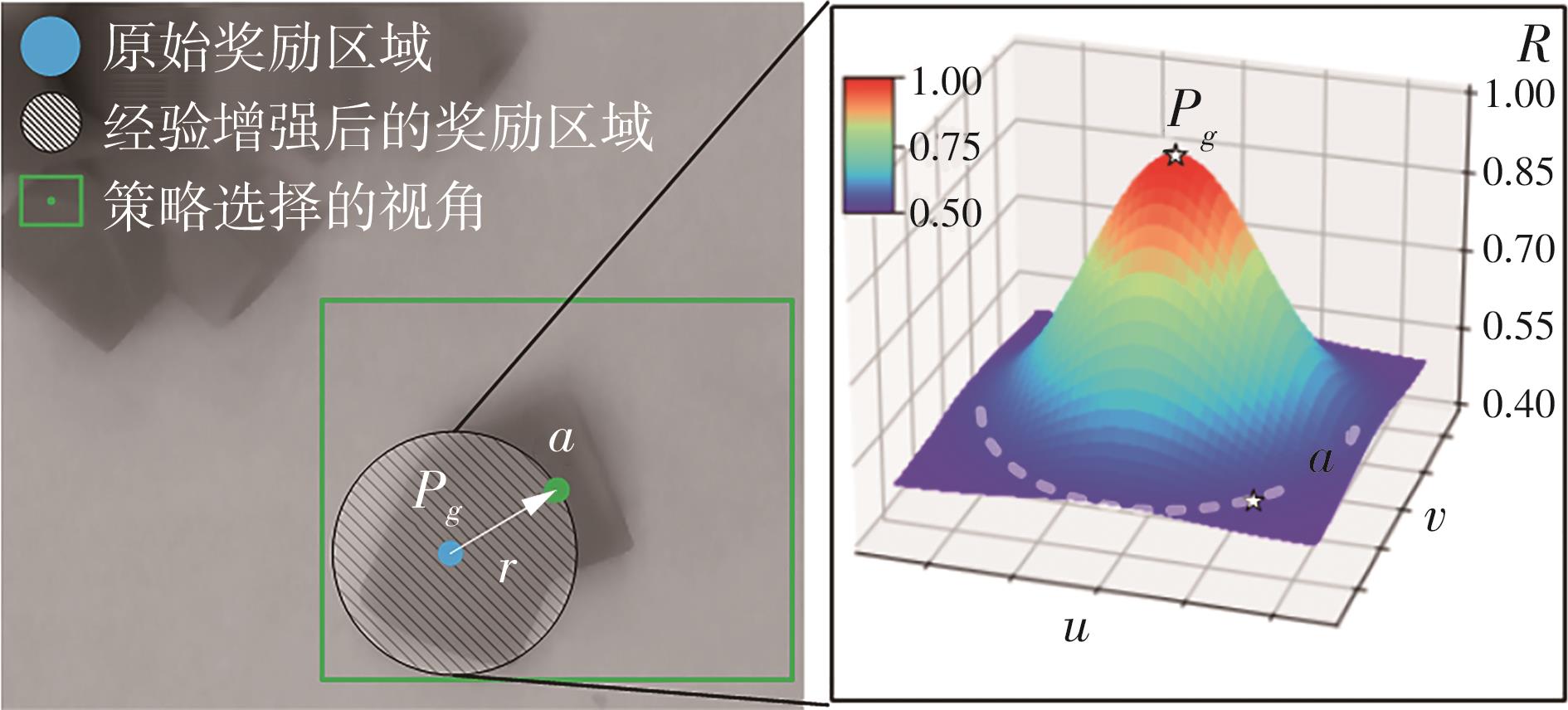
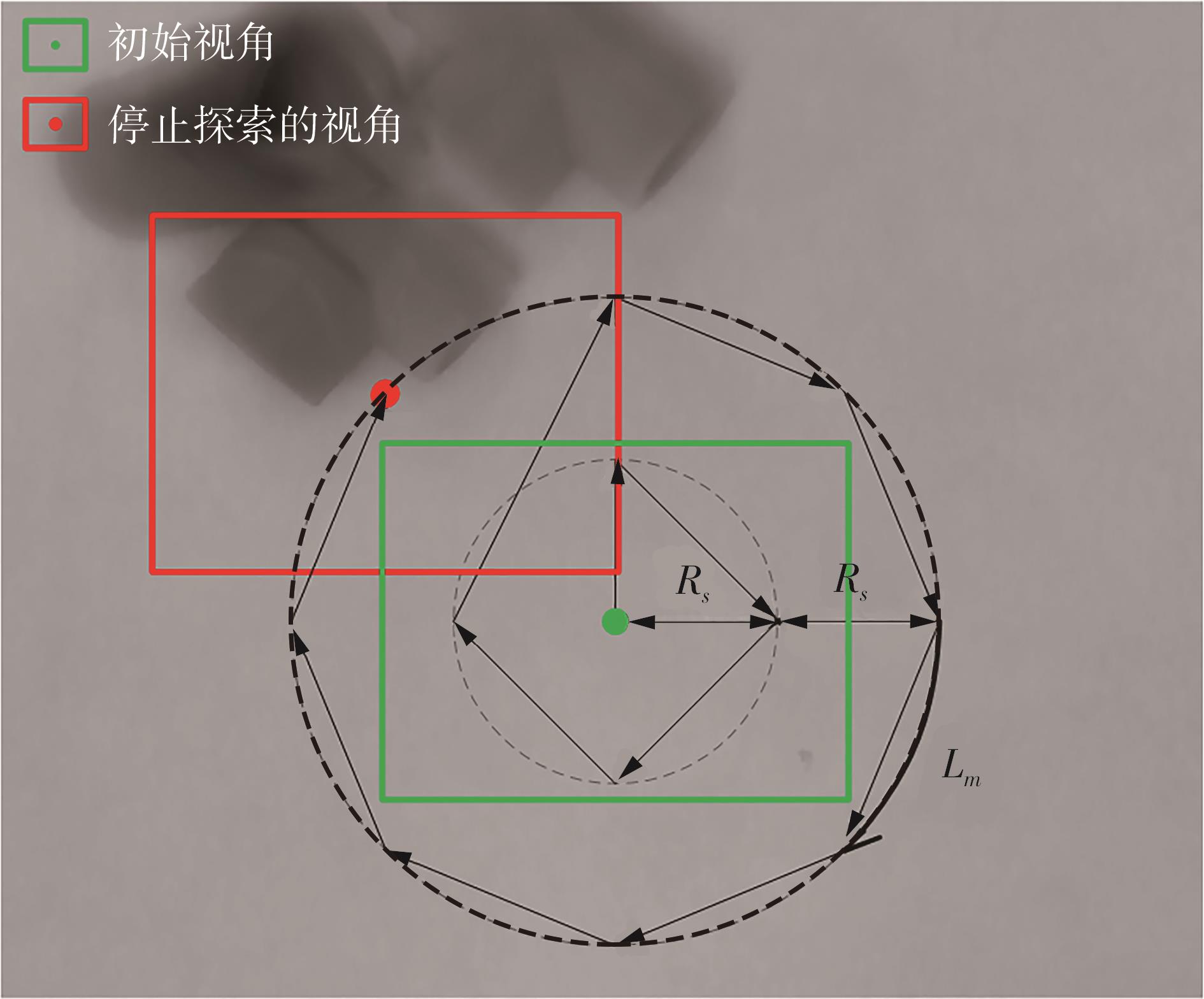
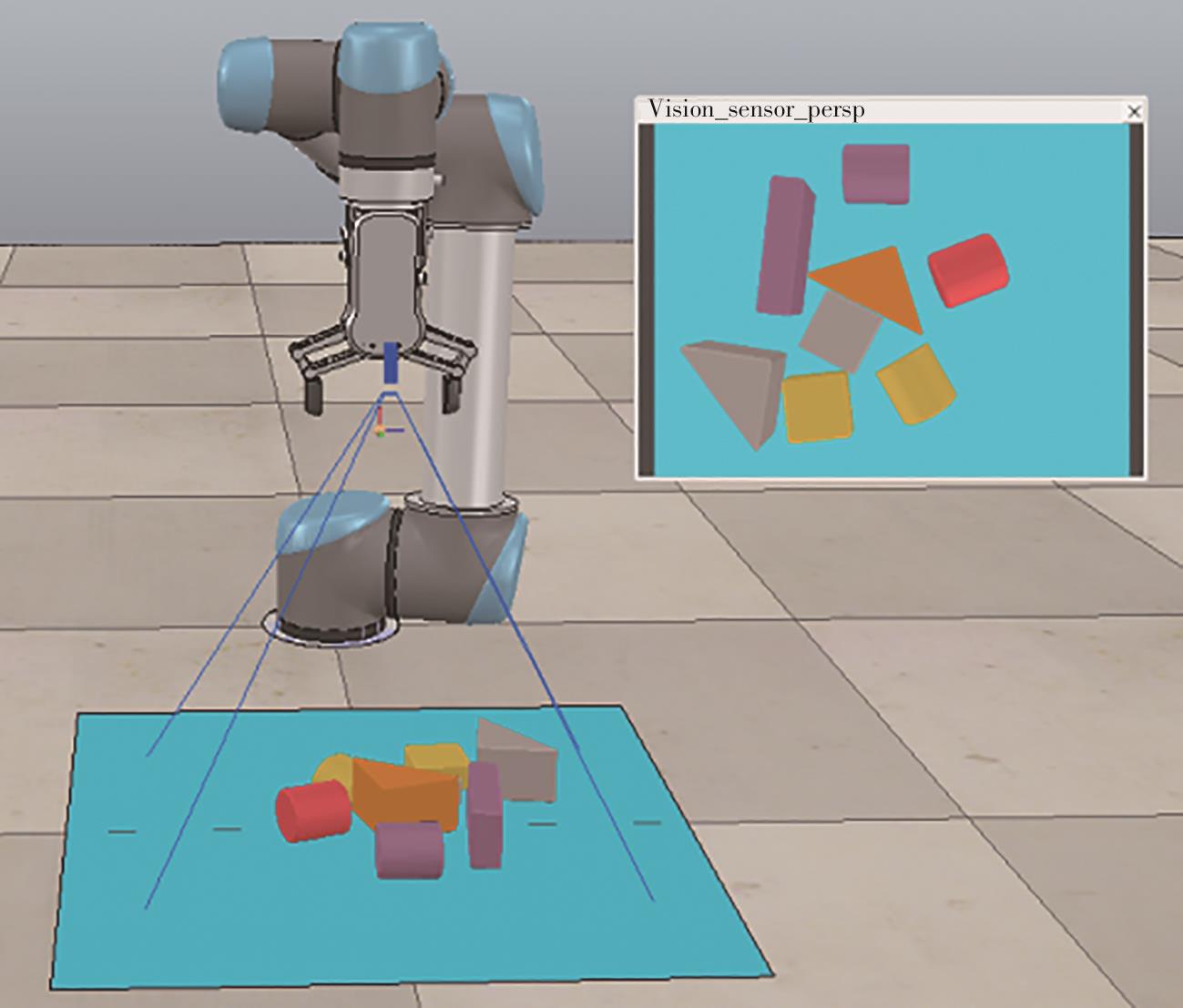
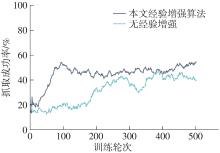
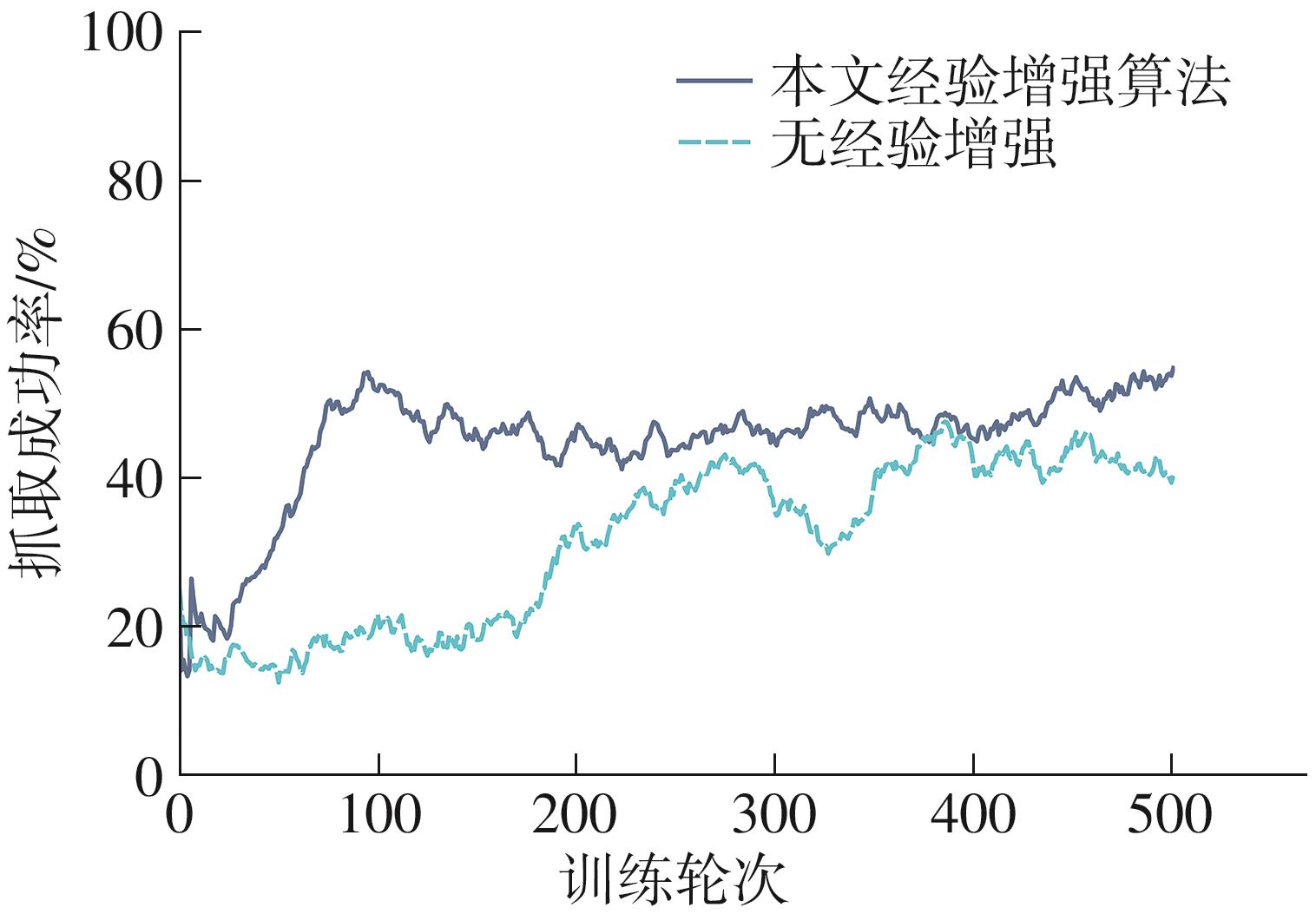
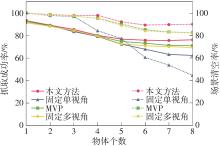
| 1 |
DU G, WANG K, LIAN S,et al .Vision-based robotic grasping from object localization,object pose estimation to grasp estimation for parallel grippers:a review[J].Artificial Intelligence Review,2021,54:1677-1734
|
| 2 |
LOWE D G .Object recognition from local scale-invariant features[C]∥ Proceedings of the seventh IEEE International Conference on Computer Vision.Corfu:IEEE,1999:1150-1157.
|
| 3 |
DROST B, ULRICH M, NAVAB N,et al .Model globally,match locally:efficient and robust 3d object recognition[C]∥ 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.San Francisco:IEEE,2010:998-1005.
|
| 4 |
HINTERSTOISSER S, HOLZER S, CAGNIART C,et al .Multimodal templates for real-time detection of texture-less objects in heavily cluttered scenes[C]∥ 2011 International Conference on Computer Vision.Barcelona:IEEE,2011:858-865.
|
| 5 |
XIANG Y, SCHMIDT T, NARAYANAN V,et al .Posecnn:a convolutional neural network for 6d object pose estimation in cluttered scenes[J].Robotics:Science and Systems,2017,14:233-244
|
| 6 |
WANG C, XU D, ZHU Y,et al .Densefusion:6d object pose estimation by iterative dense fusion[C]∥ Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.New York:IEEE,2019:3343-3352.
|
| 7 |
LENZ I, LEE H, SAXENA A .Deep learning for detecting robotic grasps[J].The International Journal of Robotics Research,2015,34(4-5):705-724.
|
| 8 |
PARK D, CHUN S Y .Classification based grasp detection using spatial transformer network[J/OL].[2018-03-04]..
|
| 9 |
MORRISON D, CORKE P, LEITNER J .Closing the loop for robotic grasping:A real-time,generative grasp synthesis approach[J/OL].[2018-05-15].
|
| 10 |
GUALTIERI M, PLATT R .Viewpoint selection for grasp detection[C]∥ 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems,IROS. Vancouver:IEEE,2017:258-264.
|
| 11 |
TEN P A, GUALTIERI M, SAENKO K,et al .Grasp pose detection in point clouds[J].The International Journal of Robotics Research,2017,36(13-14):1455-1473.
|
| 12 |
MORRISON D, CORKE P, LEITNER J .Multi-view picking:Next-best-view reaching for improved grasping in clutter[C]∥ 2019 International Conference on Robotics and Automation,ICRA. Singapore:IEEE,2019:8762-8768.
|
| 13 |
ZENG A, SONG S, WELKER S,et al .Learning synergies between pushing and grasping with self-supervised deep reinforcement learning[C]∥ 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems,IROS. Madrid:IEEE,2018:4238-4245.
|
| 14 |
DENG Y, GUO X, WEI Y,et al .Deep reinforcement learning for robotic pushing and picking in cluttered environment[C]∥ 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems,IROS. Macau:IEEE,2019:619-626.
|
| 15 |
KALASHNIKOV D, IRPAN A, PASTOR P,et al .Scalable deep reinforcement learning for vision-based robotic manipulation[C]∥ Conference on Robot Learning.Zurich:PMLR,2018:651-673.
|
| 16 |
MNIH V, KAVUKCUOGLU K, SILVER D,et al .Human-level control through deep reinforcement learning[J].Nature,2015,518(7540):529-533.
|
| 17 |
NOH H, HONG S, HAN B .Learning deconvolution network for semantic segmentation[C]∥ Proceedings of the IEEE International Conference on Computer Vision.Santiago:IEEE,2015:1520-1528.
|
| 18 |
SCHAUL T, QUAN J, ANTONOGLOU I,et al .Prioritized experience replay[J/OL].[2016-02-25].
|
| 19 |
KROEMER O, NIEKUM S, KONIDARIS G D .A review of robot learning for manipulation:challenges,representations,and algorithms[J].Journal of Machine Learning Research,2021,22(30):1-82.
|
| 20 |
王高,柳宁,叶文生,等 .一种视觉智能数控系统的数据融合方法:CN104200469A[P].2014-12-10.
|
| 21 |
VAN HASSELT H, GUEZ A, SILVER D .Deep reinforcement learning with double q-learning[C]∥ Proceedings of the AAAI conference on artificial intelligence.Arizona:AAAI,2016.
|
| 22 |
QI C R, SU H, MO K,et al .Pointnet:deep learning on point sets for 3d classification and segmentation[C]∥ Proceedings of the IEEE conference on computer vision and pattern recognition.Hawaii:IEEE,2017:652-660.
|
| 23 |
CHEN X, YE Z, SUN J,et al .Transferable active grasping and real embodied dataset[C]∥ 2020 IEEE International Conference on Robotics and Automation,ICRA. Paris:IEEE,2020:3611-3618.
|