华南理工大学学报(自然科学版) ›› 2025, Vol. 53 ›› Issue (6): 131-139.doi: 10.12141/j.issn.1000-565X.240196
轨迹数据驱动的职住地识别及出行活动特征分类方法
- 1.北京交通大学 交通运输学院,北京 100044
2.同济大学,交通学院,上海 201804
3.乌鲁木齐市城市综合交通项目研究中心,新疆 乌鲁木齐 830063
Method for Workplace and Residence Identification and Travel Activity Classification Driven by Trajectory Data
XIE Kun1(), XING Xinyuan2, DONG Honghui1, DONG Chunjiao1, CHEN Yuanduo3
- 1.School of Traffic and Transportation,Beijing Jiaotong University,Beijing 100044,China
2.School of Transportation,Tongji University,Shanghai 201804,China
3.Urumqi Urban Comprehensive Transportation Project Research Center,Urumqi 830063,Xinjiang,China
摘要:
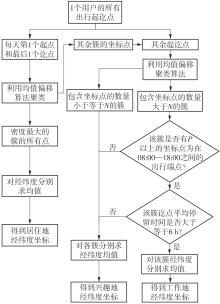
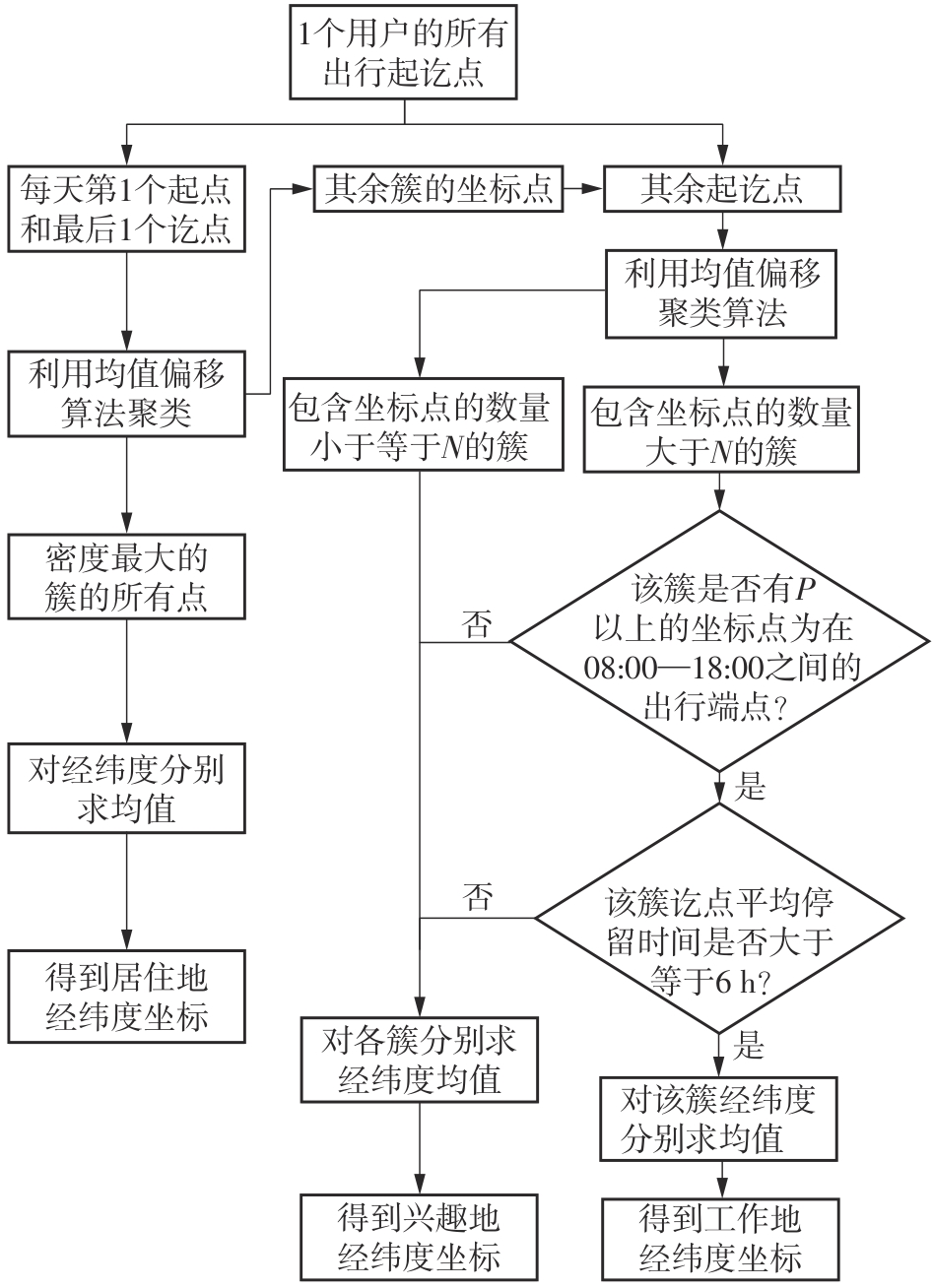
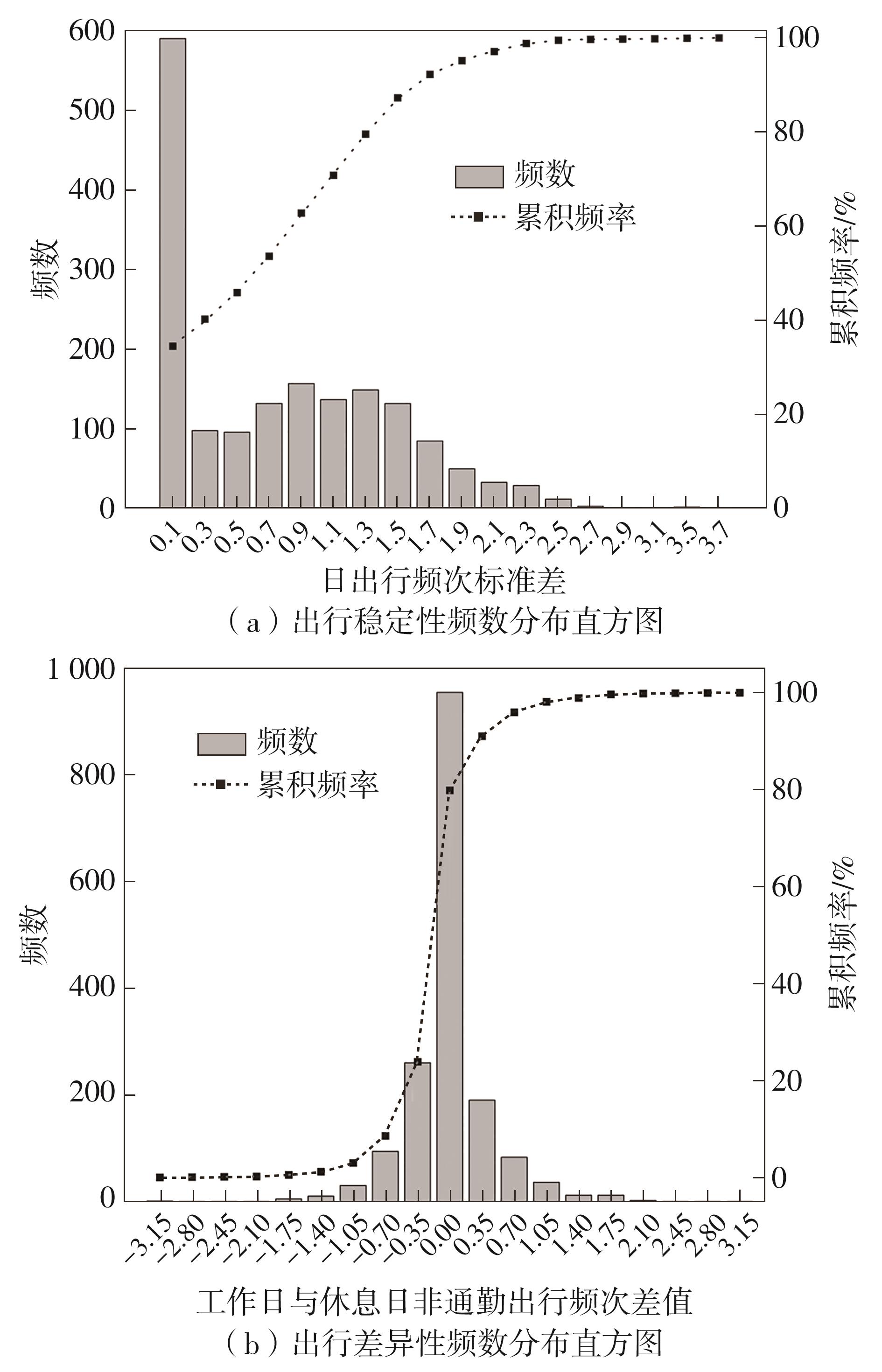
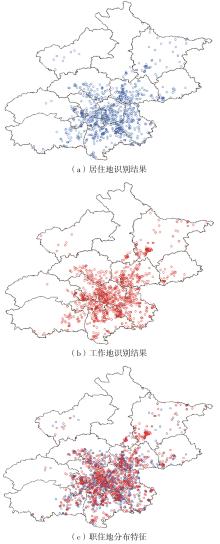
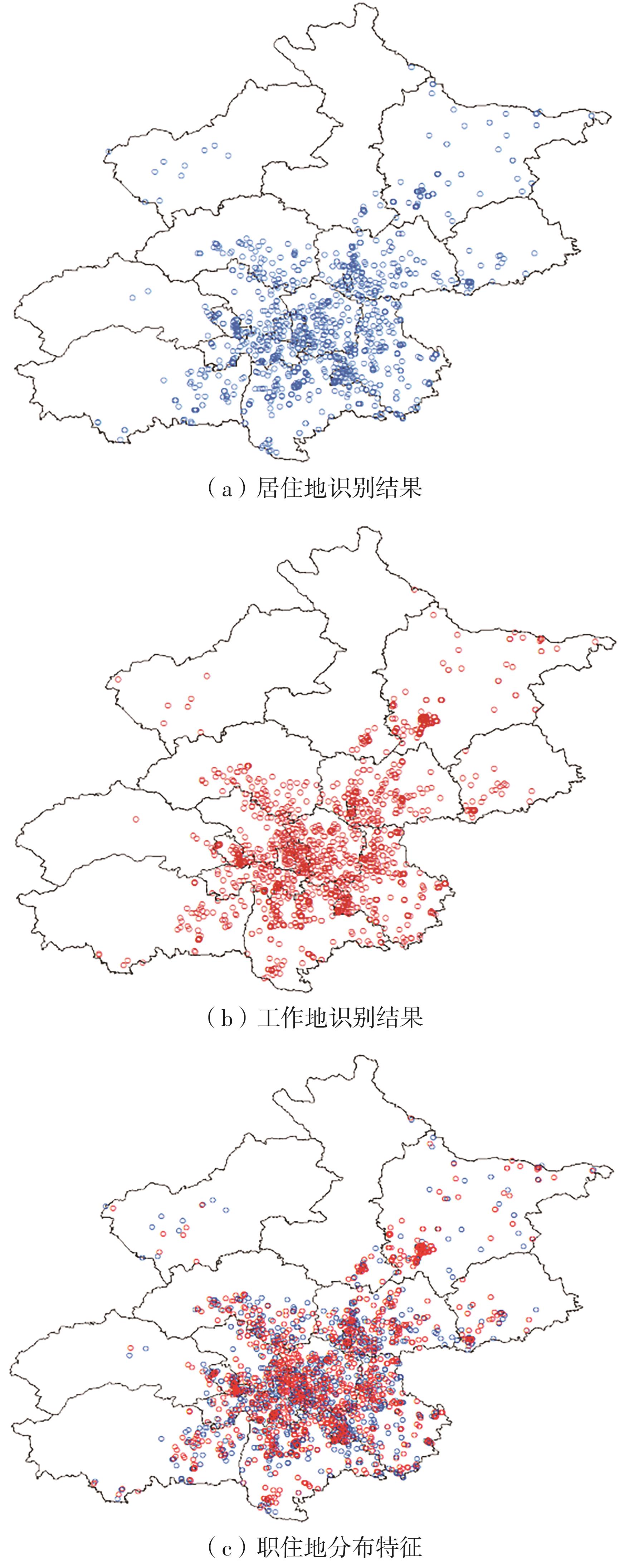
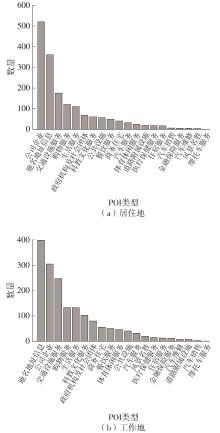
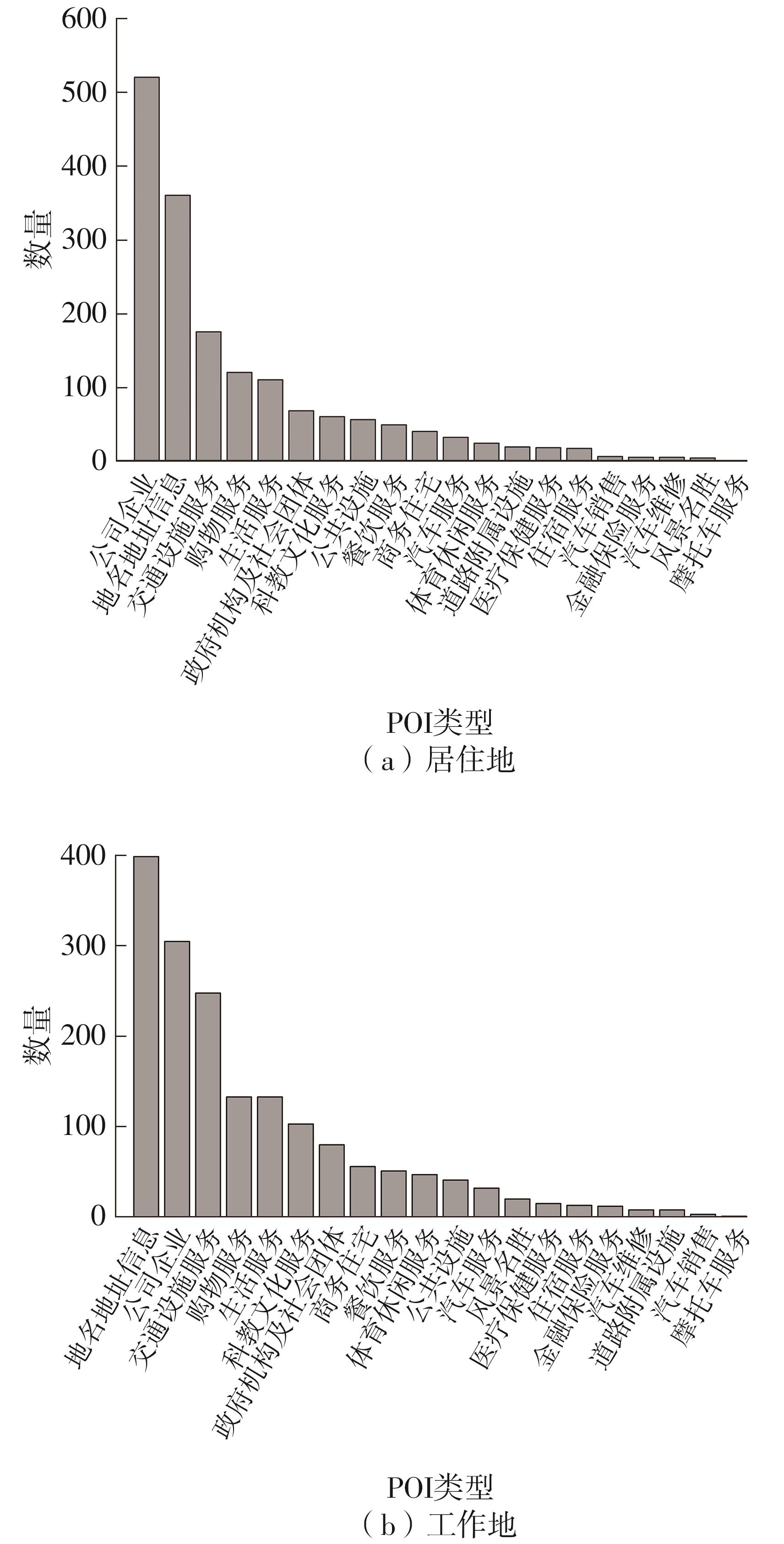
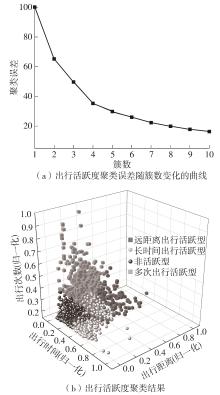
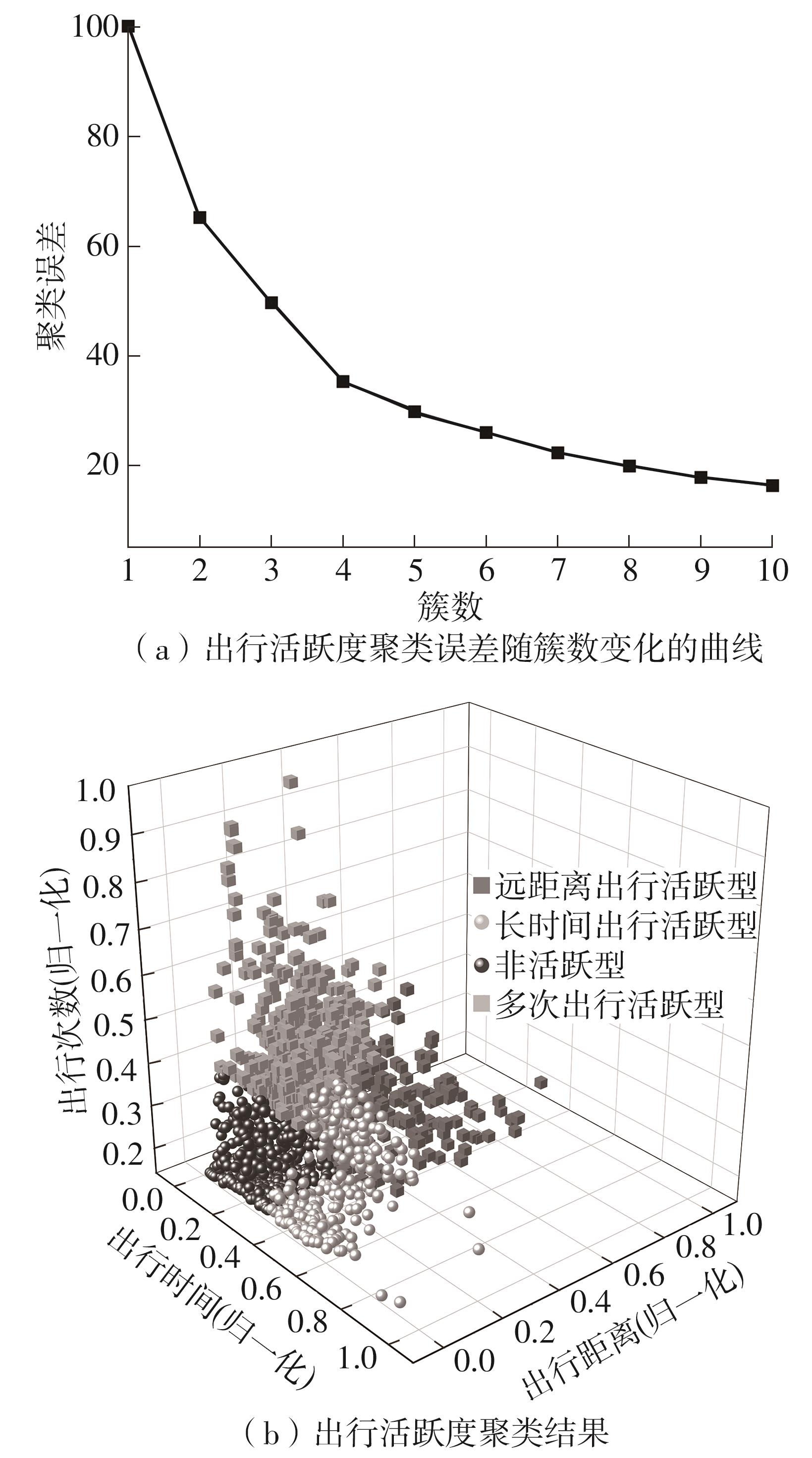
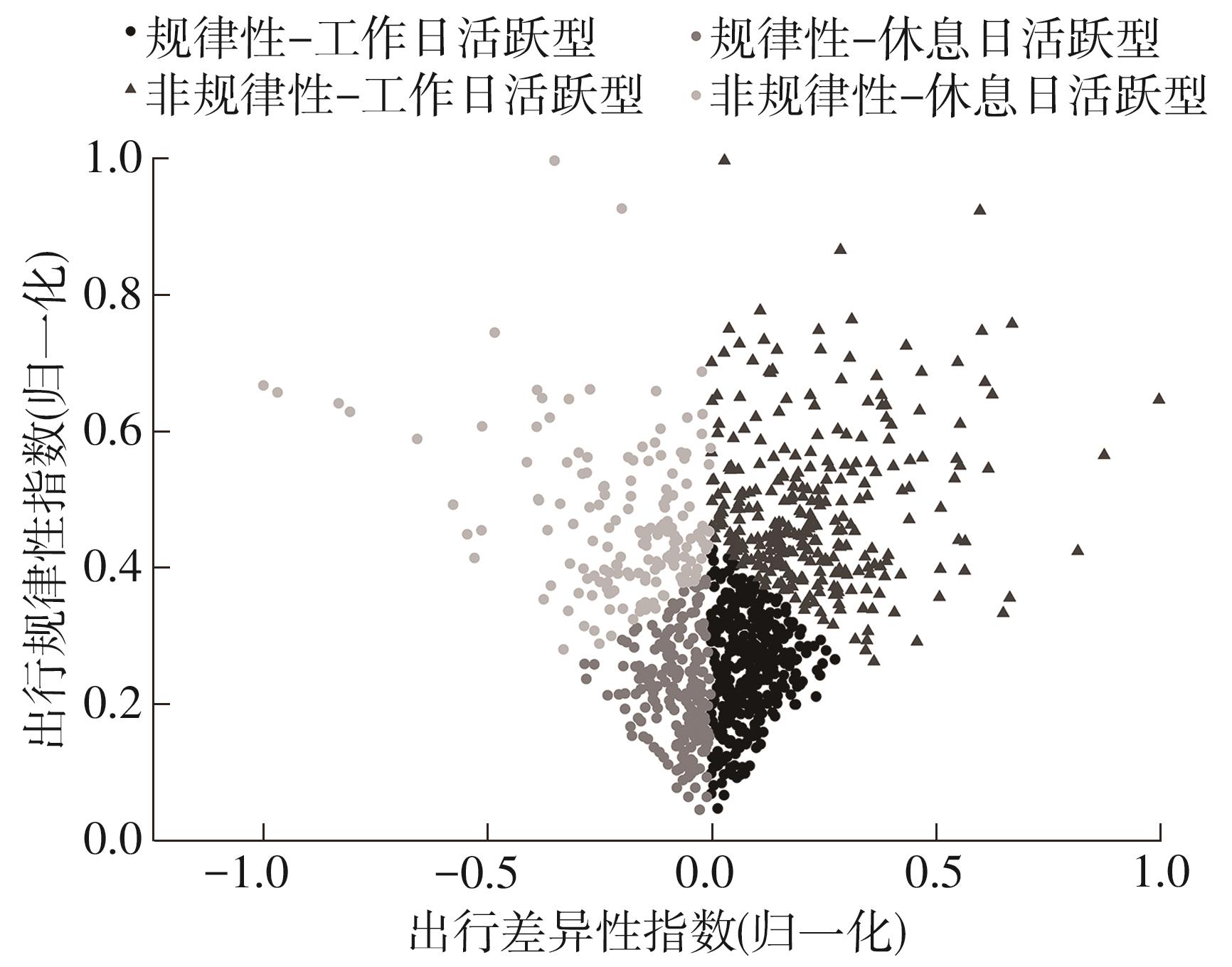
车辆行驶轨迹蕴含丰富的出行特征信息,通过研判轨迹中的职住地及出行兴趣点(POI),可以深度分析出行活动特征和规律。该文以每日出行活动第1个起点和最后1个讫点构成的点集作为居住地的可能点集,其余起讫点构成工作地与兴趣地可能点集。在可能点集的基础上,提出了基于均值偏移聚类和时空双重约束的职住地识别方法,结合簇密度、簇内点平均停留时间和出行时间范围3个条件,识别居住地、工作地和兴趣地坐标。基于KD-Tree算法为每一类地点坐标匹配邻近POI数据,得到职住地具体位置与名称。在职住地和出行兴趣点识别的基础上,结合出行次数、出行距离和出行时间表征出行活跃度,以稳定性和差异指标表征出行规律性,采用K-means++聚类分析算法,研判出行活动特征类别。以北京市连续34 d均有出行活动的1 708辆私家车行驶轨迹数据为例进行实证研究,结果表明:构建的职住地识别方法研判的职住地分布特征与现实规律相符,具有较高的精度和可靠性;基于K-means++算法的出行活动特征分类表明特大城市的出行活动以活跃型为主,占比达59.84%,其中多次出行活跃型占比最大,为31.09%;活跃型的出行活动在工作日以规律性出行为主、在非工作日以非规律性出行为主。该研究可为交通基础设施布局优化提供理论支撑。
中图分类号: