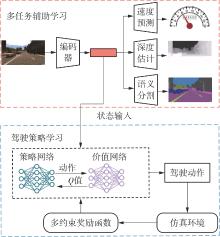
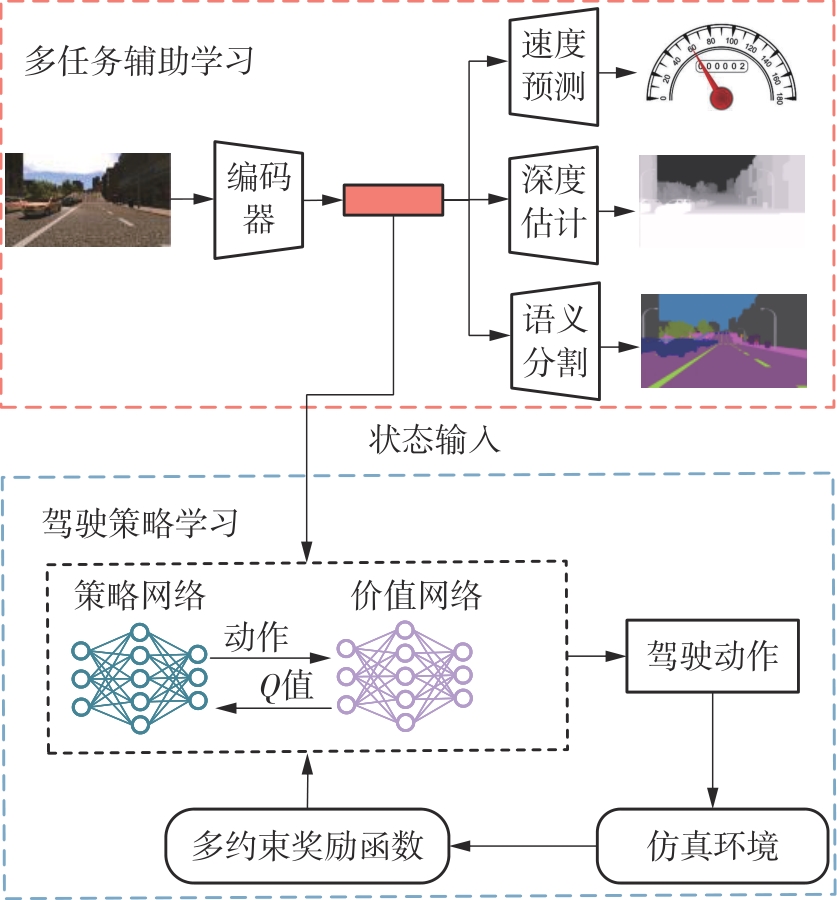
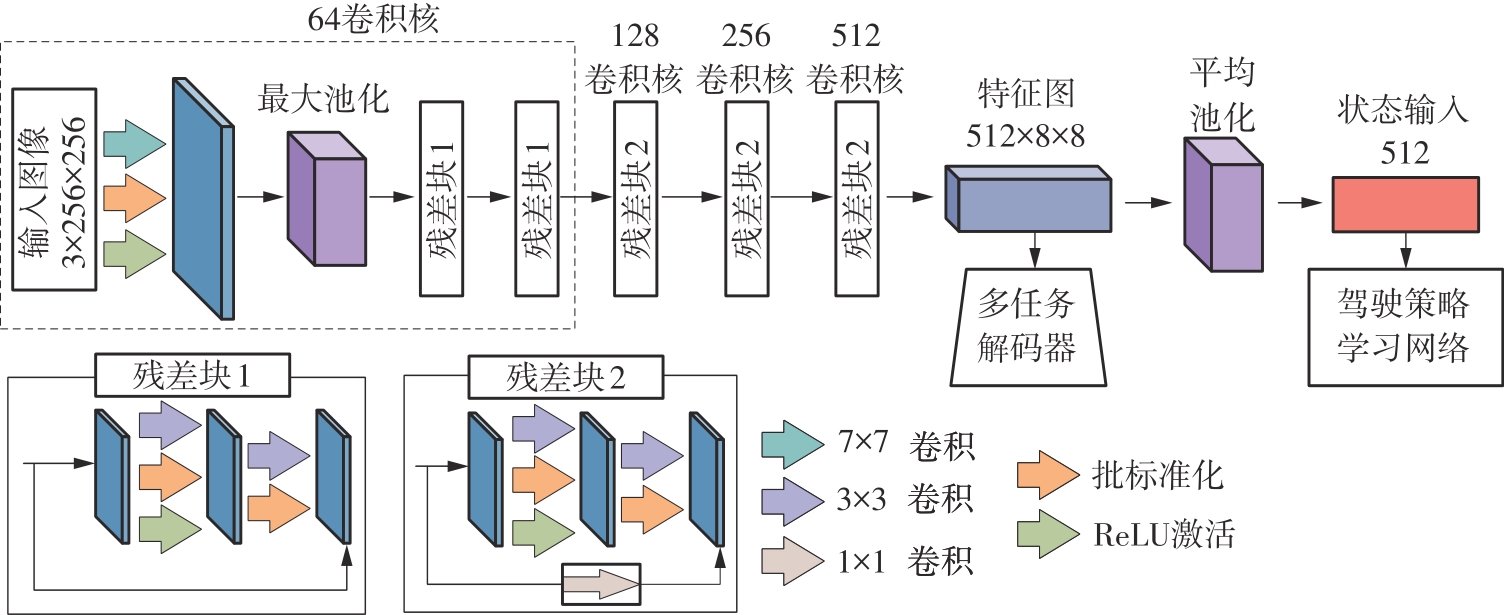
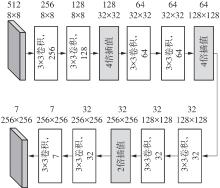
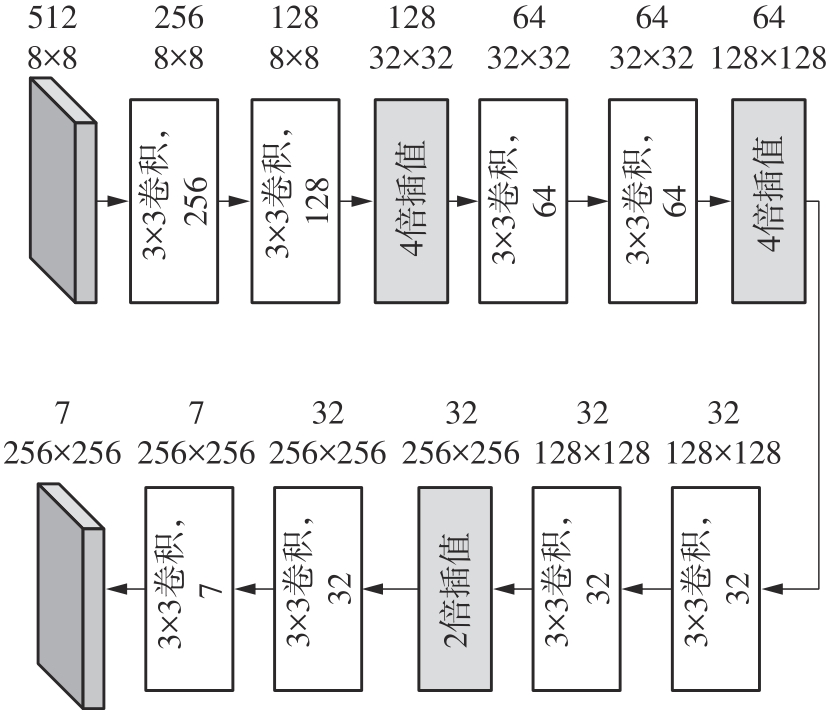
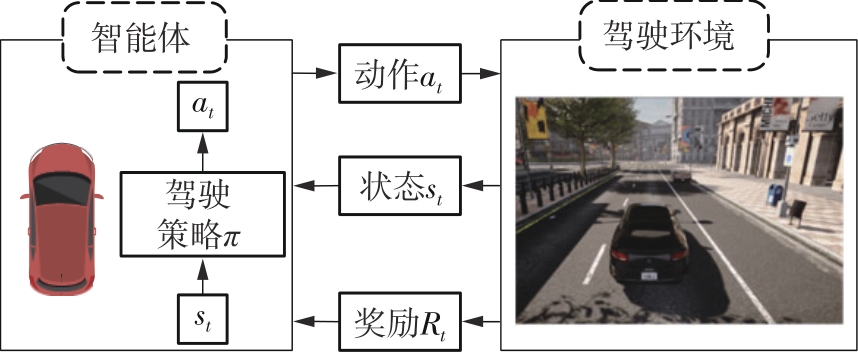
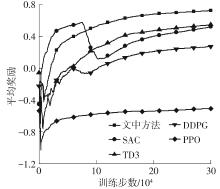
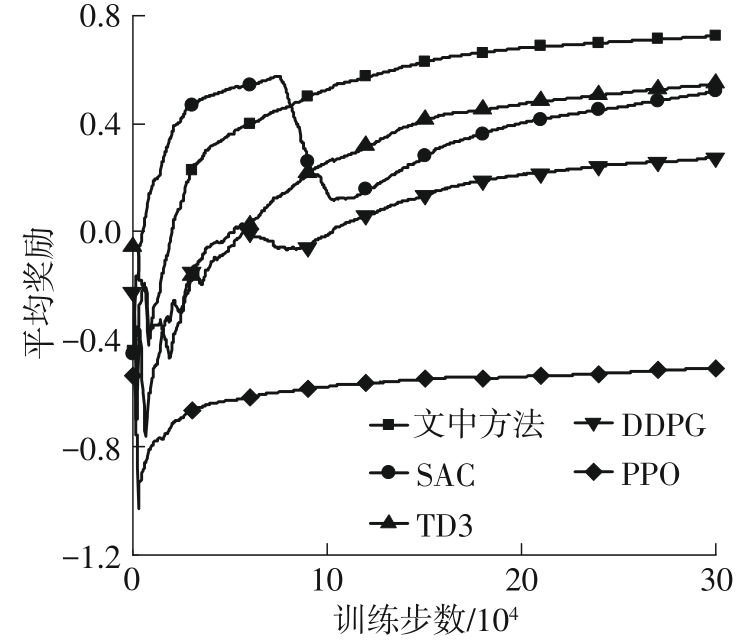
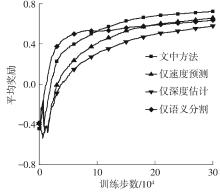
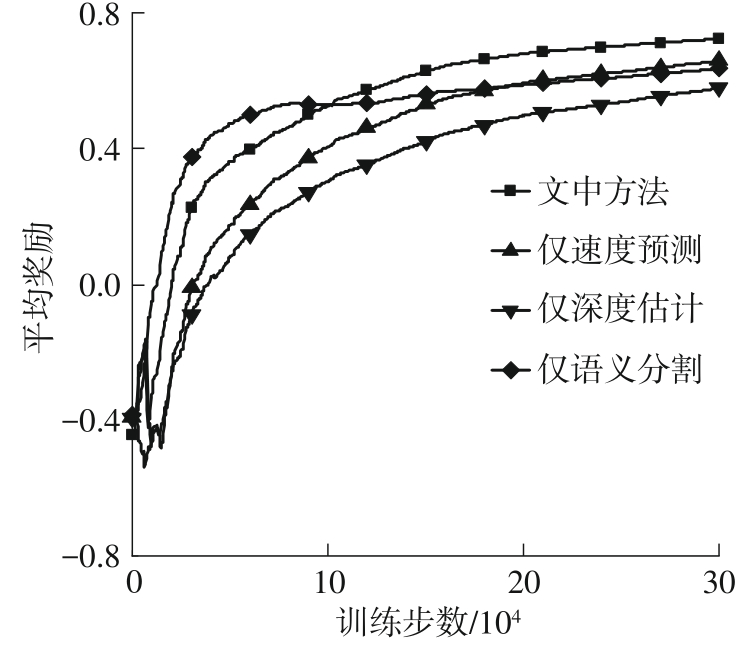
| 1 |
ELALLID B B, BENAMAR N, HAFID A S,et al .A comprehensive survey on the application of deep and reinforcement learning approaches in autonomous driving[J].Journal of King Saud University-Computer and Information Sciences,2022,34(9):7366-7390.
|
| 2 |
林泓熠,刘洋,李深,等 .车路协同系统关键技术研究进展[J].华南理工大学学报(自然科学版),2023,51(10):46-67.
|
|
LIN Hongyi, LIU Yang, LI Shen,et al .Research progress on key technologies in the cooperative vehicle infrastructure system[J].Journal of South China University of Technology (Natural Science Edition),2023,51(10):46-67.
|
| 3 |
HEJASE B, YURTSEVER E, HAN T,et al .Dynamic and interpretable state representation for deep reinforcement learning in automated driving[J].IFAC-PapersOnLine,2022,55(24):129-134.
|
| 4 |
HUANG C, ZHANG R, OUYANG M,et al .Deductive reinforcement learning for visual autonomous urban driving navigation[J].IEEE Transactions on Neural Networks and Learning Systems,2021,32(12):5379-5391.
|
| 5 |
ZHU M, WANG X, WANG Y .Human-like autonomous car-following model with deep reinforcement learning[J].Transportation Research Part C:Emerging Technologies,2018,97:348-368.
|
| 6 |
KENDALL A, HAWKE J, JANZ D,et al .Learning to drive in a day[C]∥ Proceedings of 2019 International Conference on Robotics and Automation.Montreal:IEEE,2019:8248-8254.
|
| 7 |
DOSOVITSKIY A,ROS G, CODEVILLA F,et al .CARLA:an open urban driving simulator[C]∥ Proceedings of the 1st Conference on Robot Learning.New York:ML Research Press,2017:1-16.
|
| 8 |
SAXENA D M,BAE S, NAKHAEI A,et al .Driving in dense traffic with model-free reinforcement learning[C]∥ Proceedings of 2020 IEEE International Conference on Robotics and Automation.Paris:IEEE,2020:5385-5392.
|
| 9 |
邓小豪,侯进,谭光鸿,等 .基于强化学习的多目标车辆跟随决策算法[J].控制与决策,2021,36(10):2497-2503.
|
|
DEND Xiaohao, HOU Jin, TAN Guanghong,et al .Multi-objective vehicle following decision algorithm based on reinforcement learning[J].Control and Decision,2021,36(10):2497-2503.
|
| 10 |
TOROMANOFF M, WIRBEL E, MOUTARDE F .End-to-end model-free reinforcement learning for urban driving using implicit affordances[C]∥ Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle:IEEE,2020:7153-7162.
|
| 11 |
CAI P, WANG H, SUN Y,et al .DiGNet:learning scalable self-driving policies for generic traffic scenarios with graph neural networks[C]∥ Proceedings of 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems.Prague:IEEE,2021:8979-8984.
|
| 12 |
CHEN J, YUAN B, TOMIZUKA M .Model-free deep reinforcement learning for urban autonomous driving[C]∥ Proceedings of 2019 IEEE Intelligent Transportation Systems Conference.Auckland:IEEE,2019:2765-2771.
|
| 13 |
AGARWAL T, ARORA H, SCHNEIDER J .Learning urban driving policies using deep reinforcement learning[C]∥ Proceedings of 2021 IEEE International Intelligent Transportation Systems Conference.Indianapolis:IEEE,2021:607-614.
|
| 14 |
KARGAR E, KYRKI V .Increasing the efficiency of policy learning for autonomous vehicles by multi-task representation learning[J].IEEE Transactions on Intelligent Vehicles,2022,7(3):701-710.
|
| 15 |
ZHANG Z, LINIGER A, DAI D,et al .End-to-end urban driving by imitating a reinforcement learning coach[C]∥ Proceedings of 2021 IEEE/CVF International Conference on Computer Vision.Montreal:IEEE,2021:15222-15232.
|
| 16 |
HAN Y, YILMAZ A .Learning to drive using sparse imitation reinforcement learning[C]∥ Proceedings of 2022 the 26th International Conference on Pattern Recognition.Montreal:IEEE,2022:3736-3742.
|
| 17 |
CODEVILLA F, SANTANA E, LÓPEZ A M,et al .Exploring the limitations of behavior cloning for autonomous driving[C]∥ Proceedings of 2019 IEEE/CVF International Conference on Computer Vision.Seoul:IEEE,2019:9328-9337.
|
| 18 |
CHITTA K, PRAKASH A, JAEGER B,et al .Transfuser:imitation with transformer-based sensor fusion for autonomous driving[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2023,45(11):12878-12895.
|
| 19 |
CHITTA K, PRAKASH A, GEIGER A .NEAT:neural attention fields for end-to-end autonomous driving[C]∥ Proceedings of IEEE/CVF International Conference on Computer Vision.Montreal:IEEE,2021:15793-15803.
|
| 20 |
LILLICRAP T P, HUNT J J, PRITZEL A,et al .Continuous control with deep reinforcement learning [EB/OL].(2019-07-05)[2023-07-28]..
|
| 21 |
FUJIMOTO S, VAN HOOF H, MEGER D .Addressing function approximation error in actor-critic methods[C]∥ Proceedings of the 35th International Conference on Machine Learning.New York:ML Research Press,2018:1587-1596.
|
| 22 |
SCHULMAN J, WOLSKI F, DHARIWAL P,et al .Proximal policy optimization algorithms[EB/OL].(2017-08-28)[2023-07-28]..
|
| 23 |
HAARNOJA T, ZHOU A, ABBEEL P,et al .Soft actor-critic:off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]∥ Proceedings of the 35th International Conference on Machine Learning.New York:ML Research Press,2018:1861-1870.
|
 ), 薛志成
), 薛志成