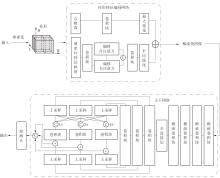
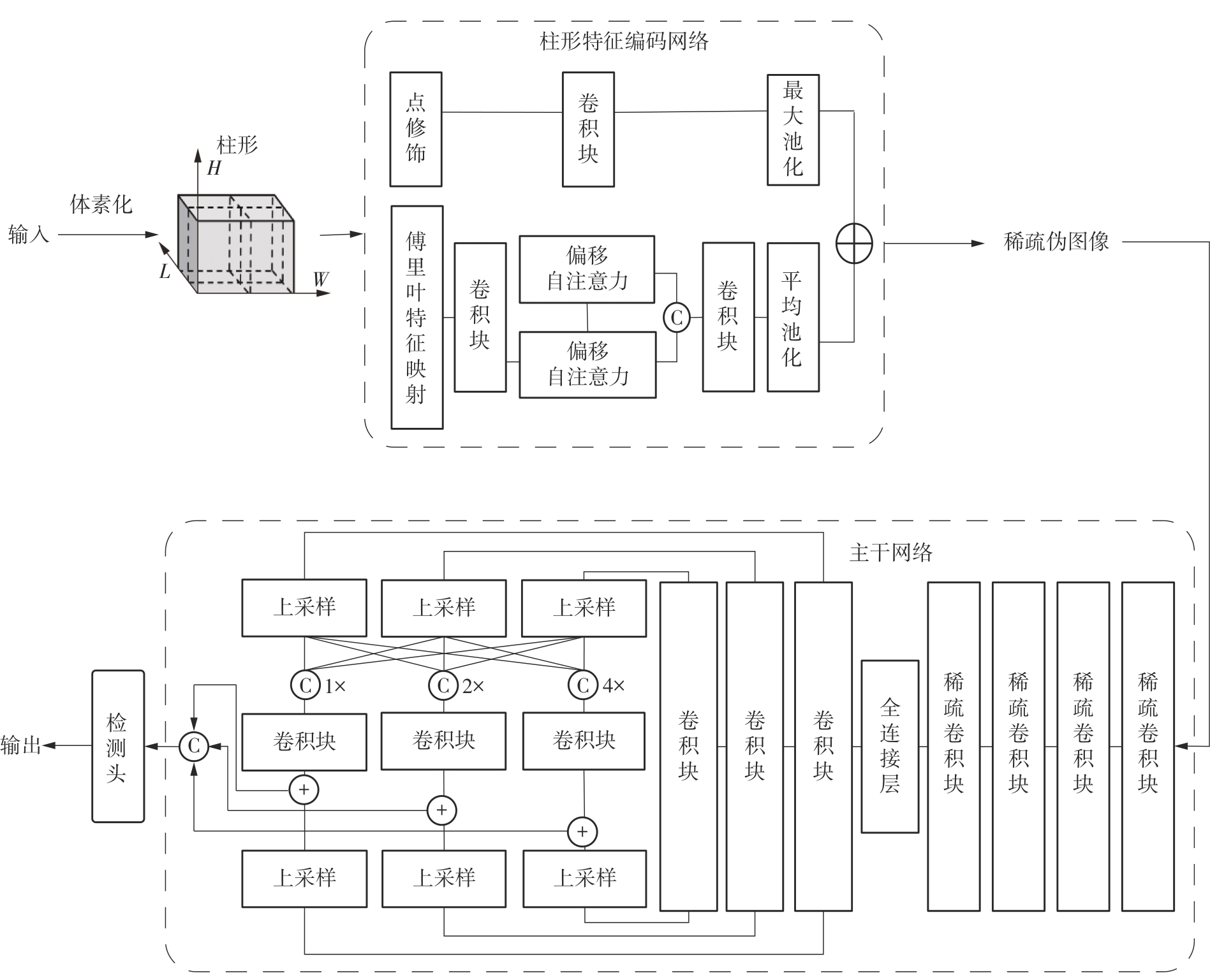
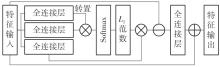
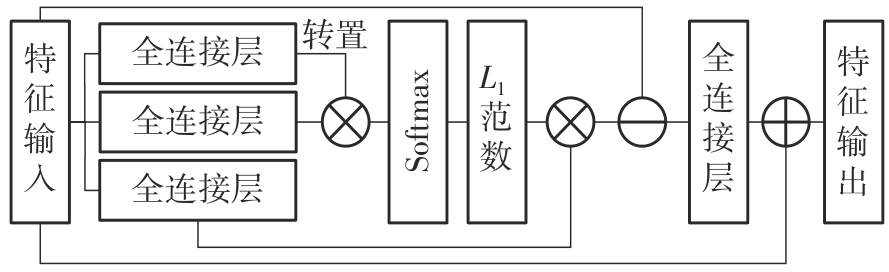
| 1 |
WU Y, WANG Y, ZHANG S,et al .Deep 3D object detection networks using LiDAR data:a review[J].IEEE Sensors Journal,2020,21(2):1152-1171.
|
| 2 |
田晟,宋霖,赵凯龙 .基于偏移注意力机制和多特征融合的点云分类[J].华南理工大学学报(自然科学版),2024,52(1):100-109.
|
|
TIAN Sheng, SONG Lin, ZHAO Kailong .Point cloud classification based on offset attention mechanism and multi-feature fusion[J].Journal of South China University of Technology (Natural Science Edition), 2024,52(1):100-109.
|
| 3 |
ZENG Y, HU Y, LIU S,et al .RT3D:real-time 3-D vehicle detection in LiDAR point cloud for autonomous driving[J].IEEE Robotics and Automation Letters,2018,3(4):3434-3440.
|
| 4 |
MEYER G P, LADDHA A,KEE E,et al .LaserNet:an efficient probabilistic 3D object detector for autonomous driving[C]∥ Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach:IEEE,2019:12669-12678.
|
| 5 |
YUE Y, CAI Y, WANG D .GridNet-3D:a novel real-time 3D object detection algorithm based on point cloud[J].Chinese Journal of Electronics,2021,30(5):931-939.
|
| 6 |
SHI S, WANG X, LI H .PointRCNN:3D object proposal generation and detection from point cloud[C]∥ Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach:IEEE,2019:770-779.
|
| 7 |
YANG Z, SUN Y, LIU S,et al .STD:sparse-to-dense 3D object detector for point cloud[C]∥ Proceedings of 2019 IEEE/CVF International Conference on Computer Vision.Seoul:IEEE,2019:1951-1960.
|
| 8 |
YANG Z, SUN Y, LIU S,et al .3DSSD:point-based 3D single stage object detector[C]∥ Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle:IEEE,2020:11037-11045.
|
| 9 |
ZAMANAKOS G, TSOCHATZIDIS L, AMANATIADIS A,et al .A comprehensive survey of LiDAR-based 3D object detection methods with deep learning for autonomous driving[J].Computers & Graphics,2021,99:153-181.
|
| 10 |
ZHANG Y F, HU Q Y, XU G Q,et al .Not all points are equal:learning highly efficient point-based detectors for 3D LiDAR point clouds[C]∥ Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition.New Orlean:IEEE,2022:18931-18940.
|
| 11 |
ZHOU Y, TUZEL O .VoxelNet:end-to-end learning for point cloud based 3D object detection[C]∥ Procee-dings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:4490-4499.
|
| 12 |
YAN Y, MAO Y, LI B .SECOND:sparsely embedded convolutional detection[J].Sensors,2018,18:3337/1-17.
|
| 13 |
龚章鹏,王国业,于是 .基于体素网络的道路场景多类目标识别算法[J].汽车工程,2021,43(4):469-477.
|
|
GONG Zhangpeng, WANG Guoye, YU Shi .The algorithm of multi-category object recognition in road scene based on voxel network[J].Automotive Engineering,2021,43(4):469-477.
|
| 14 |
LI Z.LiDAR-based 3D object detection for autonomous driving[C]∥ Proceedings of 2022 International Confe-rence on Image Processing,Computer Vision and Machine Learning.Xi’an:IEEE,2022:507-512.
|
| 15 |
LANG A H, VORA S, CAESAR H,et al .PointPi-llars:fast encoders for object detection from point clouds[C]∥ Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach:IEEE,2019:12689-12697.
|
| 16 |
LIU Z, ZHAO X, HUANG T,et al .TANet:robust 3D object detection from point clouds with triple attention[C]∥ Proceedings of the 34th AAAI Conference on Artificial Intelligence.New York:AAAI,2020:11677-11684.
|
| 17 |
YE M, XU S, CAO T .HVNet:hybrid voxel network for LiDAR based 3D object detection[C]∥ Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle:IEEE,2020:1628-1637.
|
| 18 |
LE D T, SHI H, REZATOFIGHI H,et al .Accurate and real-time 3D pedestrian detection using an efficient attentive pillar network[J].IEEE Robotics and Automation Letters,2023,8(2):1159-1166.
|
| 19 |
SHI G, LI R, MA C .PillarNet:real-time and high-performance pillar-based 3D object detection[C]∥ Proceedings of the 17th European Conference on Computer Vision.Tel Aviv:Springer,2022:35-52.
|
| 20 |
ZHOU S, TIAN Z, CHU X,et al .FastPillars:a deployment-friendly pillar-based 3D detector[EB/OL].(2023-02-05)[2024-03-20]..
|
| 21 |
程鑫,王宏飞,周经美,等 .基于体素柱形的激光雷达点云车辆目标检测算法[J].中国公路学报,2023,36(3):247-260.
|
|
CHENG Xin, WANG Hong-fei, ZHOU Jing-mei,et al .Vehicle detection algorithm based on voxel pillars from LiDAR point cloud[J].China Journal of Highway and Transport,2023,36(3):247-260.
|
| 22 |
TANCIK M, SRINIVASAN P P, MILDENHALL B,et al .Fourier features let networks learn high frequency functions in low dimensional domains[C]∥ Advances in Neural Information Processing Systems 33:34 th Confe-rence on Neural Information Processing Systems.San Diego:Neural Information Processing Systems Foundation,Inc.,2020:7537-7547.
|
| 23 |
VASWANI A, SHAZEER N, PARMAR N,et al .Attention is all you need[C]∥ Advances in Neural Information Processing Systems 30:31st Conference on Neural Information Processing Systems.San Diego:Neural Information Processing Systems Foundation, Inc.,2017:5999-6009.
|
| 24 |
GUO M H, CAI J X, LIU Z N,et al .PCT:point cloud transformer[J].Computational Visual Media,2021,7:187-199.
|
| 25 |
SHI S, WANG Z, SHI J,et al .From points to parts:3D object detection from point cloud with part-aware and part-aggregation network[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,43(8):2647-2664.
|
 ), 毛浩杰
), 毛浩杰