2024 Image Processing
The crack detection model for transportation infrastructure based on deep learning relies on large-scale data for training. To address the problem of limited availability of diverse crack samples in specific transportation facility scenarios, this paper proposes a transportation infrastructure crack image generation method based on Pix2pixHD. Firstly, the Pix2pixHD model is used to establish a spatial mapping relationship between real crack images and annotated labels based on a small amount of collected crack image data. Secondly, the objects in the label domain are edited to generate crack contours representing various forms, using methods such as label transfer from other datasets, manual editing, morphological dilation operations, and random superimposition operations. Finally, the edited label domain is transformed back to the image domain using the Pix2pixHD model, achieving adaptive augmentation of the transportation infrastructure crack dataset. Experimental results on the GAPS384, Tunnel200, and DeepCrack datasets demonstrate that the U-Net model trained with augmented data achieves higher detection accuracy and is more likely to avoid local optima. Compared to the DCGAN method, this approach exhibits better visual effects and FID quantification metric, thereby improving the generalization capability of the crack detection model in specific transportation infrastructure scenarios.
Algorithm for Registration of Multiscale Residual Deformable Lung CT Images
#br#
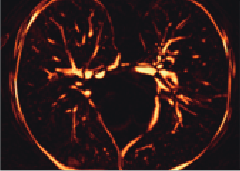
The 4D-CT image of the lungs is greatly deformed by breathing and heartbeat, and the motion scale within the lungs may be larger than the structures of interest (blood vessels, airways, etc.) used by the algorithm for optimization. This may lead to the registration algorithm aligning only obvious features such as blood vessels and airways. For the problem of large intensity differences in the registration of lung parenchyma contours, a multi-scale residual deformable image registration framework based on unsupervised end-to-end deep learning is proposed. A multi-scale deep residual network with encoder-decoder structure is used as the deformation field generation model in the proposed registration framework, which enhances feature representation ability, utilizes parameters more efficiently, and effectively improves the convergence ability of the network. The network's ability to perceive multi-scale information is improved through the multi-resolution self-attention fusion module, and a skip connection containing a feature correction extraction module is designed to selectively extract the feature maps output by the encoder and realign them for the decoder to learn alignment offsets. To evaluate the effectiveness of the proposed registration framework, the target registration error of the proposed method on the dir-lab public dataset was compared with traditional methods and current advanced unsupervised registration methods. The results show that the proposed registration framework achieves a target registration error of 1.44±1.24mm on the dir-lab public dataset, which is superior to traditional methods and mainstream unsupervised registration algorithms. In addition, with a controlled folding voxel of less than 0.1%, estimating the dense deformation vector field takes less than 2 seconds, demonstrating the great potential of this algorithm in time-sensitive lung research.
The integer transform methods are widely adopted in international image and video coding standards due to their fast computation strategies. Existing integer transform methods are generated from continuous orthogonal systems, which not only makes it difficult to obtain precise integer forms of original transforms, but also cannot overcome the Gibbs phenomenon in discontinuous signal representation, reducing the quality of reconstructed images. Thus, a new integer transform and its image compression method based on discontinuous U-system are proposed. Firstly, the piecewise integration and the Gram-Schmidt process are used to calculate the two-dimensional orthogonal matrix of the U-system, and the scaling factors of row vectors are extracted to obtain the integer matrix. Secondly, the reversible integer U transform is established, and the integer matrix is applied to concentrate the energy of images into a small amount of data sets, while merging scaling factors with quantization to reduce computational burden. Then, the fast integer U transform is achieved by using matrix decomposition and sparse matrices. Finally, the integer U transform module and inverse transform module are designed to alleviate the pressure of image storage and transmission. Experimental results show that the proposed method can reduce truncation errors of reversible image transform compared with related algorithms; the new method obtains higher compressed image quality in image and video compression experiments, and the fast transform algorithm effectively saves computational time.
Surface defect detection is an important part of the modern industrial production process. The existing visual defect detection methods generally achieve detection by analyzing a single RGB or grayscale image of the target object and using differential features between the defect and the background. They are suitable for objects with a large difference between the target and the background, such as the detection of metal surface oxidation and spot defects. However, the simple RGB image cannot effectively characterize the 3D defect features such as dents and bulges, which are mainly formed by depth changes, ultimately resulting in missed detection. To this end, this paper extracted the 3D geometric appearance information of the object surface to be tested according to multi-directional light imaging and photometric stereo principle. Next, the original multi-directional light images were effectively fused using the contrast pyramid fusion algorithm to obtain the enhanced 2D RGB fusion image features of the defects. Then, on the basis of the multi-target detection framework YOLOv5, with the above geometric appearance and RGB fusion images as inputs, a defect detection network model based on dual stream feature fusion detection network model was constructed. The model introduces the spatial channel attention residual module and the gated recurrent unit (GRU) feature fusion module and is able to organically fuse the different modal features at multiple levels to realize the effective extraction of the 2D RGB and 3D appearance information of the surface defects, so as to achieve the purpose of dealing with the detection of 2D and 3D defects at the same time. Finally, the detection experiments were conducted on the surface defects of several typical industrial products. The results show that mAP of the method in the paper is above 90% on several datasets, and it can simultaneously cope with the detection of 2D and 3D defects, so the detection performance is better than that of the current mainstream methods, and it can meet the detection requirements of different industrial products.
 2024 Image Processing
2024 Image Processing
