
Journal of South China University of Technology(Natural Science) >
Semantic-Visual Consistency Constraint Network for Zero-Shot Image Semantic Segmentation
Received date: 2023-10-29
Online published: 2023-12-26
Supported by
the National Natural Science Foundation of China(62176095)
Zero-shot image semantic segmentation is one of the important tasks in the visual field of zero-shot learning, aiming to segment novel categories unseen during training. The current distribution of visual features based on pixel-level visual feature generation is inconsistent with real visual feature distribution. The synthesized visual features inadequately reflect class semantic information, leading to low discriminability in these features. Some existing generative methods consume significant computational resources to obtain the discriminative information conveyed by semantic features. In view of the above problems, this paper proposed a zero-shot image semantic segmentation network called SVCCNet, which is based on semantic-visual consistency constraints. SVCCNet uses a semantic-visual consistency constraint module to facilitate the mutual transformation between semantic features and visual features, enhancing their correlation and diminishing the disparity between the spatial structures of real and synthesized visual features, which mitigates the inconsistency problem between the distributions of synthesized and real visual features. The semantic-visual consistency constraint module achieves the correspondence between visual features and class semantics through two mutually constrained reconstruction mappings, while maintaining low model complexity. Experimental results on the PASCAL-VOC and PASCAL-Context datasets demonstrate that SVCCNet outperforms mainstream methods in terms of pixel accuracy, mean accuracy, mean intersection over union (IoU), and harmonic IoU.
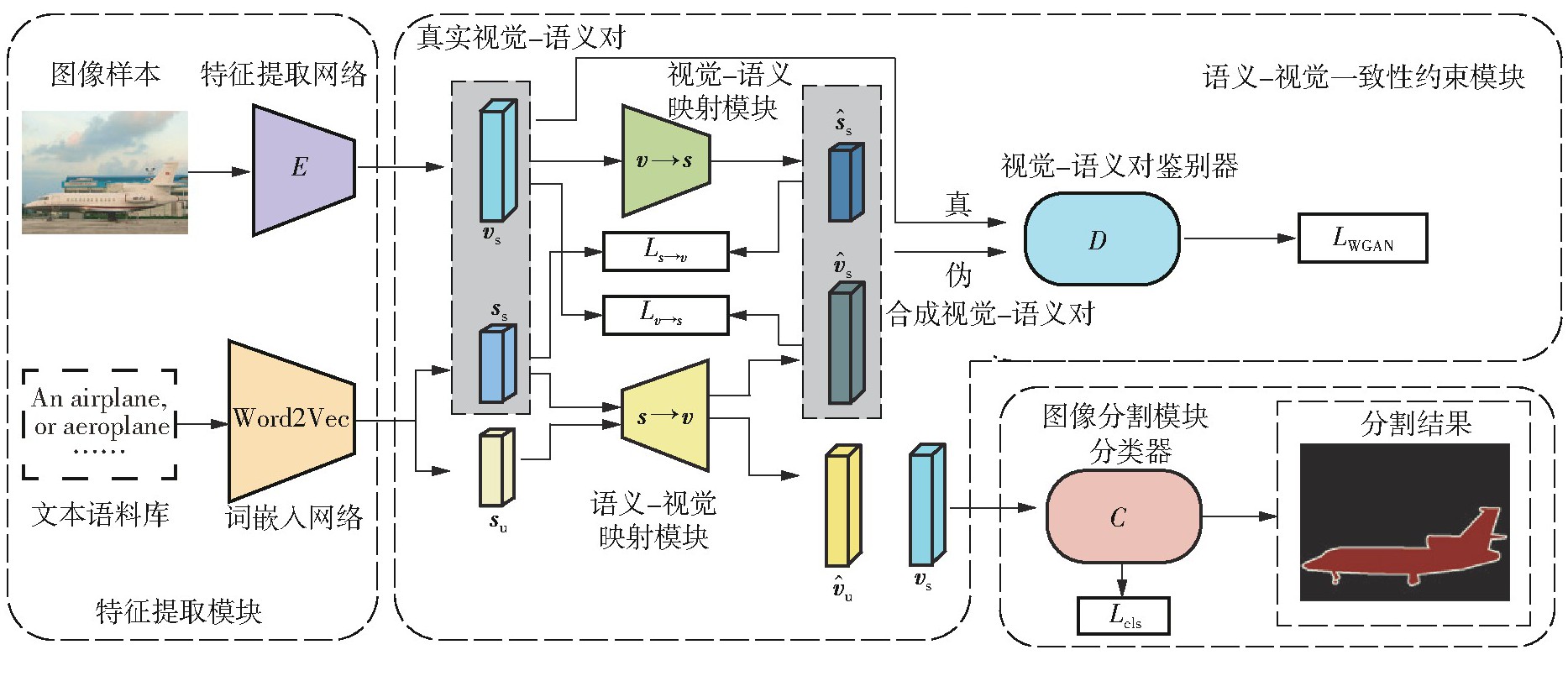
CHEN Qiong , FENG Yuan , LI Zhiqun , YANG Yong . Semantic-Visual Consistency Constraint Network for Zero-Shot Image Semantic Segmentation[J]. Journal of South China University of Technology(Natural Science), 2024 , 52(10) : 41 -50 . DOI: 10.12141/j.issn.1000-565X.230673
| 1 | RONNEBERGER O, FISCHER P, BROX T .U-Net:convolutional networks for biomedical image segmentation[C]∥ Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention.Munich:Springer,2015:234-241. |
| 2 | ZHAO H S, SHI J P, QI X J,et al .Pyramid scene parsing network[C]∥ Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu:IEEE,2017:2881-2890. |
| 3 | BUCHER M, VU T H, CORD M,et al .Zero-shot semantic segmentation[C]∥ Proceedings of the 32nd International Conference on Neural Information Processing Systems.Vancouver:Curran Associates Inc.,2019:468-479. |
| 4 | XIAN Y Q, CHOUDHURY S, HE Y,et al .Semantic projection network for zero-and few-label semantic segmentation[C]∥ Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach:IEEE,2019:8256-8265. |
| 5 | MIKOLOV T, SUTSKEVER I, CHEN K,et al .Distributed representations of words and phrases and their compositionality[C]∥ Proceedings of the 26th International Conference on Neural Information Processing Systems.Red Hook:Curran Associates Inc.,2013:3111-3119. |
| 6 | LV F M, LIU H Y, WANG Y C,et al .Learning unbiased zero-shot semantic segmentation networks via transductive transfer[J].IEEE Signal Processing Letters,2020,27:1640-1644. |
| 7 | YANG S, SHI Y M, WANG Y W,et al .Attribute driven zero-shot classification and segmentation[C]∥ Proceedings of 2018 IEEE International Conference on Multimedia & Expo Workshops.San Diego:IEEE,2018:8551489/1-6. |
| 8 | KATO N, YAMASAKI T, AIZAWA K .Zero-shot semantic segmentation via variational mapping[C]∥ Proceedings of 2019 IEEE/CVF International Conference on Computer Vision Workshops.Seoul:IEEE,2019:1363-1370. |
| 9 | GU Z X, ZHOU S Y, NIU L,et al .Context-aware feature generation for zero-shot semantic segmentation[C]∥ Proceedings of the 28th ACM International Conference on Multimedia.Seattle:ACM,2020:1921-1929. |
| 10 | BAEK D,OH Y,HAM B .Exploiting a joint embedding space for generalized zero-shot semantic segmentation[C]∥ Proceedings of 2021 IEEE/CVF International Conference on Computer Vision.Montreal:IEEE,2021:9536-9545. |
| 11 | DING J, XUE N, XIA G S,et al .Decoupling zero-shot semantic segmentation[C]∥ Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition.New Orleans:IEEE,2022:11583-11592. |
| 12 | LI B Y, WEINBERGER K Q, BELONGIE S,et al .Language-driven semantic segmentation[EB/OL].(2022-01-10)[2023-07-17].. |
| 13 | RADFORD A, KIM J W, HALLACY C,et al .Learning transferable visual models from natural language supervision[C]∥ Proceedings of the 38th International Conference on Machine Learning.Vienna:ML Research Press,2021:8748-8763. |
| 14 | XIE G S, ZHANG Z, LIU G S,et al .Generalized zero-shot learning with multiple graph adaptive generative networks[J].IEEE Transactions on Neural Networks and Learning Systems,2022,33(7):2903-2915. |
| 15 | CHEN L C, ZHU Y K, PAPANDREOU G,et al .Encoder-decoder with atrous separable convolution for semantic image segmentation[C]∥ Proceedings of the 15th European Conference on Computer Vision.Munich:Springer,2018:833-851. |
| 16 | BAU D, ZHU J Y, WULFF J,et al .Seeing what a GAN cannot generate[C]∥ Proceedings of 2019 IEEE/CVF International Conference on Computer Vision.Seoul:IEEE,2019:4501-4510. |
| 17 | EVERINGHAM M, ESLAMI S M A, VAN GOOL L,et al .The PASCAL visual object classes challenge:a retrospective[J].International Journal of Computer Vision,2015,111:98-136. |
| 18 | MOTTAGHI R, CHEN X J, LIU X B,et al .The role of context for object detection and semantic segmentation in the wild[C]∥ Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014:891-898. |
| 19 | CACHEUX Y L, BORGNE H L, CRUCIANU M .Modeling inter and intra-class relations in the triplet loss for zero-shot learning[C]∥ Proceedings of 2019 IEEE/CVF International Conference on Computer Vision.Long Beach:IEEE,2019:10332-10341. |
| 20 | FU Y, HOSPEDALES T M, XIANG T,et al .Transductive multi-view embedding for zero-shot recognition and annotation[C]∥ Proceedings of the 13th European Conference on Computer Vision.Zurich:Springer,2014:584-599. |
/
| 〈 |
|
〉 |