
Journal of South China University of Technology(Natural Science) >
A Robot Grasping Policy Based on Viewpoint Selection Experience Enhancement Algorithm
Received date: 2021-12-06
Online published: 2022-02-10
Supported by
the National Natural Science Foundation of China(62172188)
To solve the problem of the low success rate of robot vision grasping using fixed environment camera in the scene of cluttered and stacked objects, an eye-hand follow-up camera viewpoint selection policy based on deep reinforcement learning is proposed to improve the accuracy and speed of vision-based grasping. Firstly, a Markov decision process model is constructed for robot active vision-based grasping task, then the problem of viewpoint selection is transformed into a problem of solving the viewpoint value function. A deconvolution network with encoder-decoder structure is used to approximate the viewpoint action value function, and the reinforcement learning is carried out based on the deep Q-network framework. Then, to resolve the problem of sparse reward existing in reinforcement learning, a novel viewpoint experience enhancement algorithm is proposed. The different enhancement methods between the successful and failed grasping process are designed respectively. And the reward region can be expanded from a single point to a circular region for improving the convergence speed of the approximation network. The preliminary experiment is deployed on the simulation platform, and the robot model and the grasping environment are simultaneously built in the simulation platform to implement the offline reinforcement learning. In the process, the proposed viewpoint experience enhancement algorithm can effectively improve the sample utilization rate and speed up the convergence of training. Based on the proposed viewpoint experience enhancement algorithm, the viewpoint action value function approximation network can converge within 2 h. To obtain the results from the verification with application, the proposed viewpoint selection policy is applied to the real-world scenes with robot for grasping experiments. The result shows that the viewpoint optimization based on this policy can effectively promote the accuracy and speed of robot grasping. Compared with the general grasping methods, the proposed viewpoint selection policy needs only one viewpoint selection in real-world robot grasping to find the focus region with high grasping success rate. And the method can also promote the processing efficiency of the best viewpoint selection. The grasping success rate in cluttered scenes is increased by 22.8% against the single-view method, and the mean picks per hour can reach 294 units. As whole, it shows that the proposed policy has the capacity of industrial application.
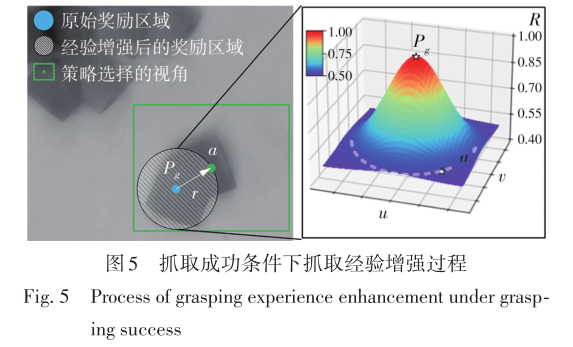
WANG Gao, CHEN Xiaohong, LIU Ning, et al . A Robot Grasping Policy Based on Viewpoint Selection Experience Enhancement Algorithm[J]. Journal of South China University of Technology(Natural Science), 2022 , 50(9) : 126 -137 . DOI: 10.12141/j.issn.1000-565X.210769
| 1 | DU G, WANG K, LIAN S,et al .Vision-based robotic grasping from object localization,object pose estimation to grasp estimation for parallel grippers:a review[J].Artificial Intelligence Review,2021,54:1677-1734 |
| 2 | LOWE D G .Object recognition from local scale-invariant features[C]∥ Proceedings of the seventh IEEE International Conference on Computer Vision.Corfu:IEEE,1999:1150-1157. |
| 3 | DROST B, ULRICH M, NAVAB N,et al .Model globally,match locally:efficient and robust 3d object recognition[C]∥ 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.San Francisco:IEEE,2010:998-1005. |
| 4 | HINTERSTOISSER S, HOLZER S, CAGNIART C,et al .Multimodal templates for real-time detection of texture-less objects in heavily cluttered scenes[C]∥ 2011 International Conference on Computer Vision.Barcelona:IEEE,2011:858-865. |
| 5 | XIANG Y, SCHMIDT T, NARAYANAN V,et al .Posecnn:a convolutional neural network for 6d object pose estimation in cluttered scenes[J].Robotics:Science and Systems,2017,14:233-244 |
| 6 | WANG C, XU D, ZHU Y,et al .Densefusion:6d object pose estimation by iterative dense fusion[C]∥ Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.New York:IEEE,2019:3343-3352. |
| 7 | LENZ I, LEE H, SAXENA A .Deep learning for detecting robotic grasps[J].The International Journal of Robotics Research,2015,34(4-5):705-724. |
| 8 | PARK D, CHUN S Y .Classification based grasp detection using spatial transformer network[J/OL].[2018-03-04].. |
| 9 | MORRISON D, CORKE P, LEITNER J .Closing the loop for robotic grasping:A real-time,generative grasp synthesis approach[J/OL].[2018-05-15]. |
| 10 | GUALTIERI M, PLATT R .Viewpoint selection for grasp detection[C]∥ 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems,IROS. Vancouver:IEEE,2017:258-264. |
| 11 | TEN P A, GUALTIERI M, SAENKO K,et al .Grasp pose detection in point clouds[J].The International Journal of Robotics Research,2017,36(13-14):1455-1473. |
| 12 | MORRISON D, CORKE P, LEITNER J .Multi-view picking:Next-best-view reaching for improved grasping in clutter[C]∥ 2019 International Conference on Robotics and Automation,ICRA. Singapore:IEEE,2019:8762-8768. |
| 13 | ZENG A, SONG S, WELKER S,et al .Learning synergies between pushing and grasping with self-supervised deep reinforcement learning[C]∥ 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems,IROS. Madrid:IEEE,2018:4238-4245. |
| 14 | DENG Y, GUO X, WEI Y,et al .Deep reinforcement learning for robotic pushing and picking in cluttered environment[C]∥ 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems,IROS. Macau:IEEE,2019:619-626. |
| 15 | KALASHNIKOV D, IRPAN A, PASTOR P,et al .Scalable deep reinforcement learning for vision-based robotic manipulation[C]∥ Conference on Robot Learning.Zurich:PMLR,2018:651-673. |
| 16 | MNIH V, KAVUKCUOGLU K, SILVER D,et al .Human-level control through deep reinforcement learning[J].Nature,2015,518(7540):529-533. |
| 17 | NOH H, HONG S, HAN B .Learning deconvolution network for semantic segmentation[C]∥ Proceedings of the IEEE International Conference on Computer Vision.Santiago:IEEE,2015:1520-1528. |
| 18 | SCHAUL T, QUAN J, ANTONOGLOU I,et al .Prioritized experience replay[J/OL].[2016-02-25]. |
| 19 | KROEMER O, NIEKUM S, KONIDARIS G D .A review of robot learning for manipulation:challenges,representations,and algorithms[J].Journal of Machine Learning Research,2021,22(30):1-82. |
| 20 | 王高,柳宁,叶文生,等 .一种视觉智能数控系统的数据融合方法:CN104200469A[P].2014-12-10. |
| 21 | VAN HASSELT H, GUEZ A, SILVER D .Deep reinforcement learning with double q-learning[C]∥ Proceedings of the AAAI conference on artificial intelligence.Arizona:AAAI,2016. |
| 22 | QI C R, SU H, MO K,et al .Pointnet:deep learning on point sets for 3d classification and segmentation[C]∥ Proceedings of the IEEE conference on computer vision and pattern recognition.Hawaii:IEEE,2017:652-660. |
| 23 | CHEN X, YE Z, SUN J,et al .Transferable active grasping and real embodied dataset[C]∥ 2020 IEEE International Conference on Robotics and Automation,ICRA. Paris:IEEE,2020:3611-3618. |
/
| 〈 |
|
〉 |