Journal of South China University of Technology(Natural Science Edition) ›› 2025, Vol. 53 ›› Issue (12): 1-16.doi: 10.12141/j.issn.1000-565X.240549
• Intelligent Transportation System • Previous Articles Next Articles
A Method for Joint Optimization of Signal Timing and Vehicle Trajectories at Intersections Based on Hierarchical Soft Actor-Critic Reinforcement Learning
MA Yingying1, LI Teng1, LIANG Yunyi2, TANG Meng1
- 1.School of Civil Engineering and Transportation,South China University of Technology,Guangzhou 510640,Guangdong,China
2.Business School,University of Shanghai for Science and Technology,Shanghai 200093,China
-
Received:2024-11-18Online:2025-12-25Published:2025-07-04 -
Contact:梁韵逸(1991—),男,博士,副教授,主要从事车路协同系统感知、优化和控制、强化学习、深度学习研究。 E-mail:liangyunyilyy@126.com -
About author:马莹莹(1983—),女,博士,教授,主要从事智能交通分析与管理、交通组织与设计、交通行为与绿色交通研究。E-mail: mayingying@scut.edu.cn -
Supported by:the National Natural Science Foundation of China(52072129);the Hunan Provincial Natural Science Foundation of China(2023JJ40731)
CLC Number:
Cite this article
MA Yingying, LI Teng, LIANG Yunyi, TANG Meng. A Method for Joint Optimization of Signal Timing and Vehicle Trajectories at Intersections Based on Hierarchical Soft Actor-Critic Reinforcement Learning[J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(12): 1-16.
share this article
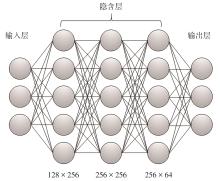
Fig.1
Architecture of the value network and policy network"
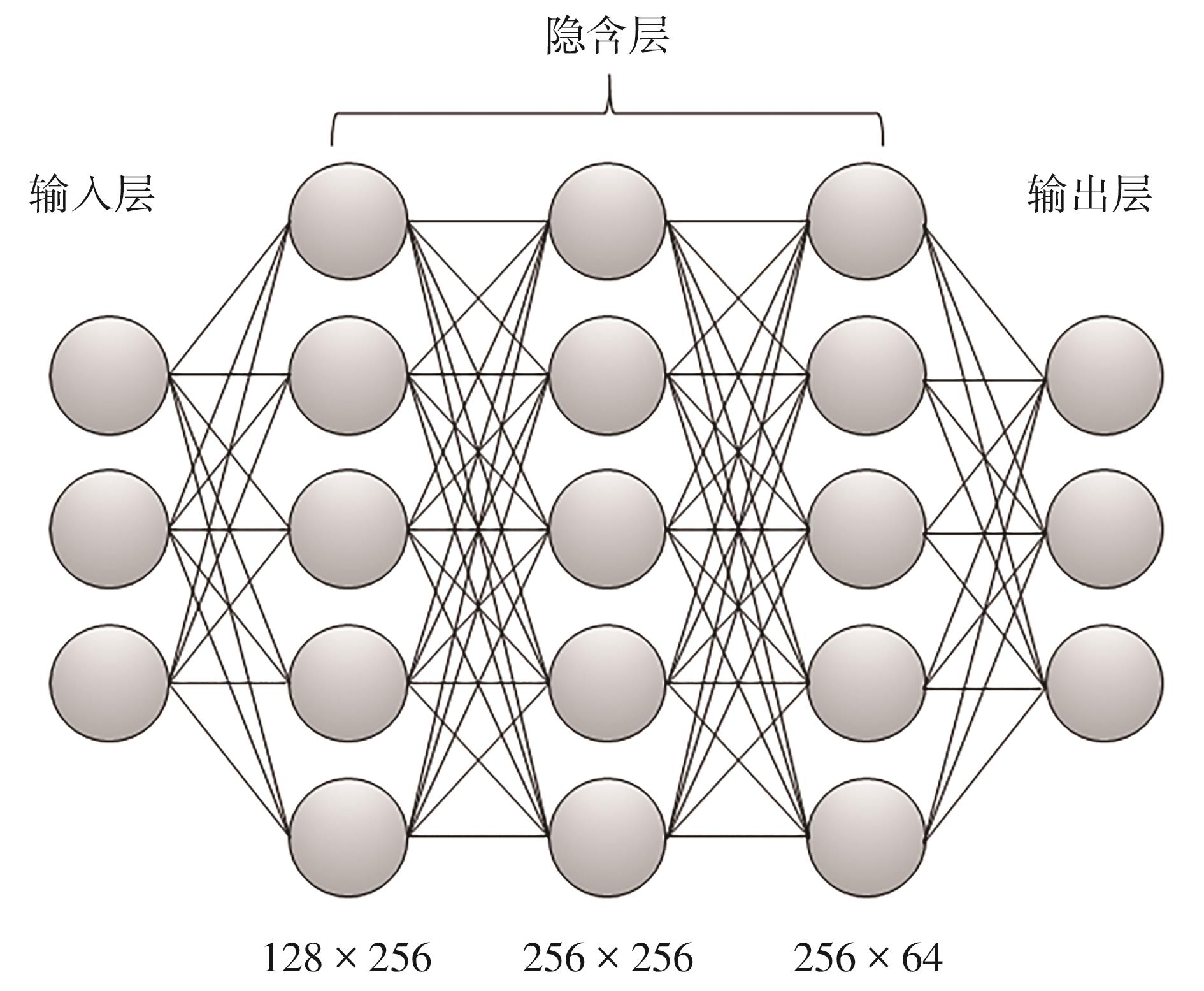
Fig.2
Hierarchical SAC algorithm framework for the joint optimization of vehicle trajectories and signal control"
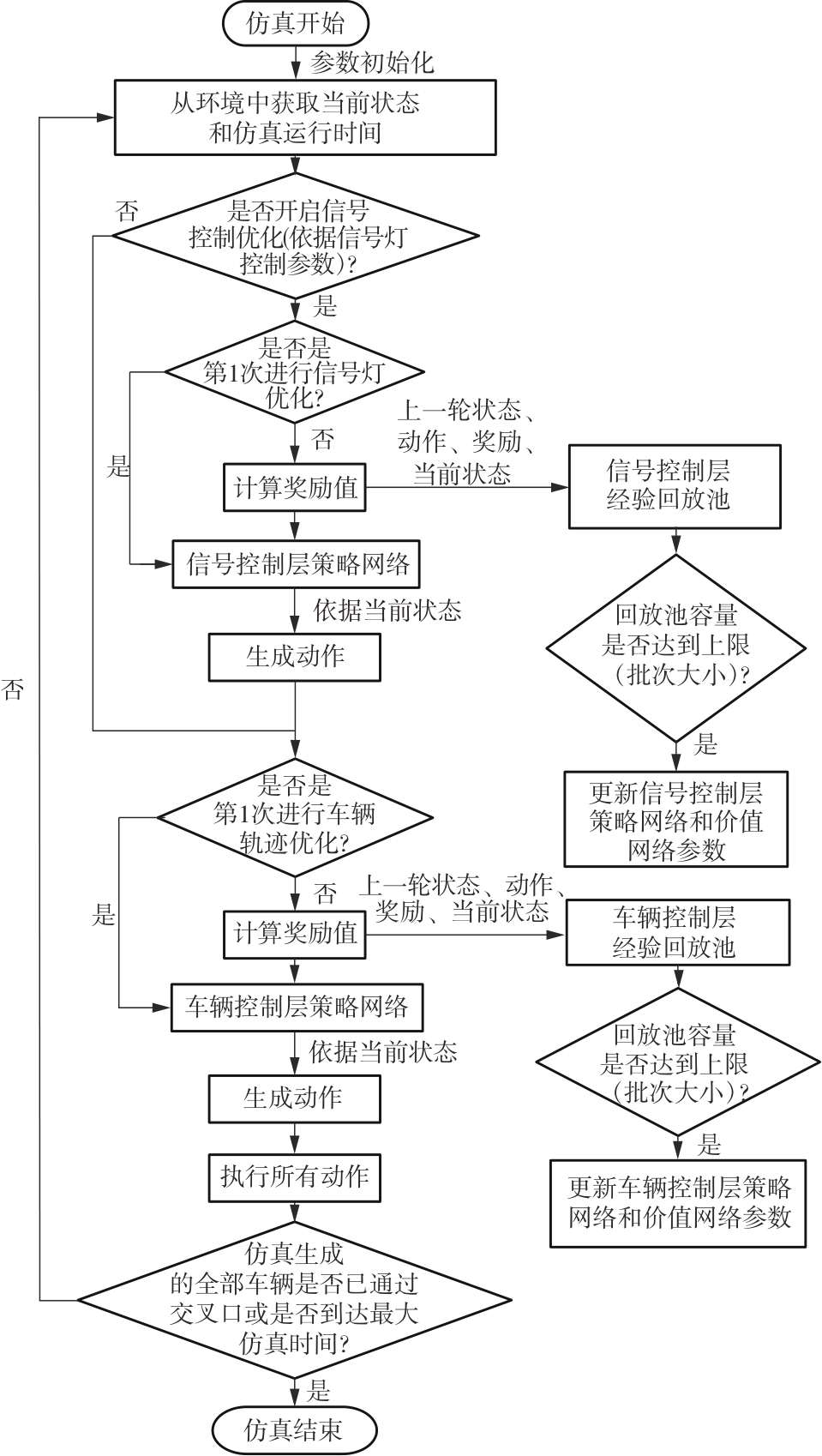

Fig.3
Schematic diagram of simulation environment"
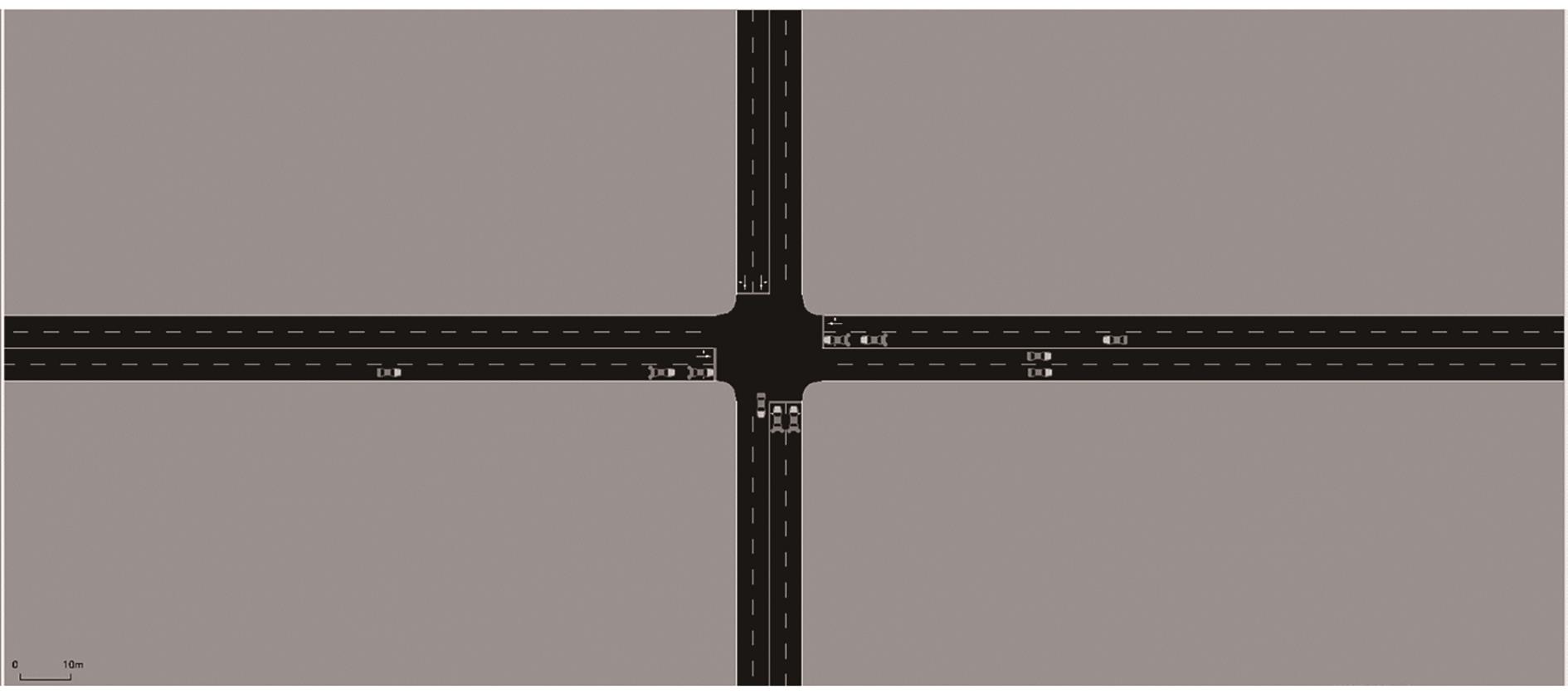
Table 1
Configuration of SUMO simulation environment parameters in various scenarios"
| 参数名称 | 单位 | 取值 | ||
|---|---|---|---|---|
| 场景1 | 场景2 | 场景3 | ||
| km/h | 60 | |||
| m/s2 | 2.5 | |||
| m/s2 | -4.5 | |||
| L | m | 400 | ||
| s | — | 5 | 5 | |
| — | 0.5 | 0.5 | ||
| 辆/h | 160 | 300 | 360 | |
| 辆/h | 160 | 300 | 360 | |
| 辆/h | 160 | 240 | 360 | |
| 辆/h | 160 | 240 | 360 | |
Table 2
Parameter configuration of the reinforcement learning algorithm in different scenarios"
| 参数 | 取值 |
|---|---|
| 温度系数 | 0.2 |
| 折扣因子 | 除场景3下模型4取0.93外,其余均取0.90 |
| 策略网络学习率 | 除场景2下模型4取1 |
| 价值网络学习率 | 1 |
| 批次大小 | 128 |
Table 3
Configuration of reward function weights across various scenarios"
| 场景 | 模型 | ||||
|---|---|---|---|---|---|
| 场景1 | 模型2 | 1.20 | 1.6 | 0.40 | 7.0 |
| 模型3 | 1.00 | 0.0 | 0.00 | 10.0 | |
| 模型4 | 1.00 | 1.0 | 0.05 | 0.0 | |
| 场景2 | 模型2 | 1.00 | 1.0 | 0.40 | 1.5 |
| 模型3 | 1.00 | 0.0 | 0.00 | 10.0 | |
| 模型4 | 1.20 | 1.0 | 0.05 | 0.0 | |
| 场景3 | 模型2 | 1.00 | 1.0 | 0.40 | 1.5 |
| 模型3 | 1.00 | 0.0 | 0.00 | 10.0 | |
| 模型4 | 1.25 | 1.0 | 0.05 | 0.0 |
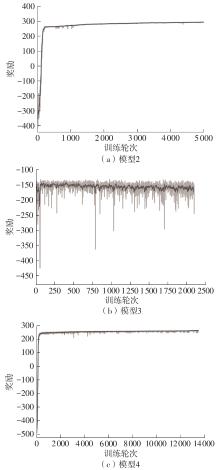
Fig.4
Reward curves of the joint optimization model 2,3 and 4 under scenario 2"
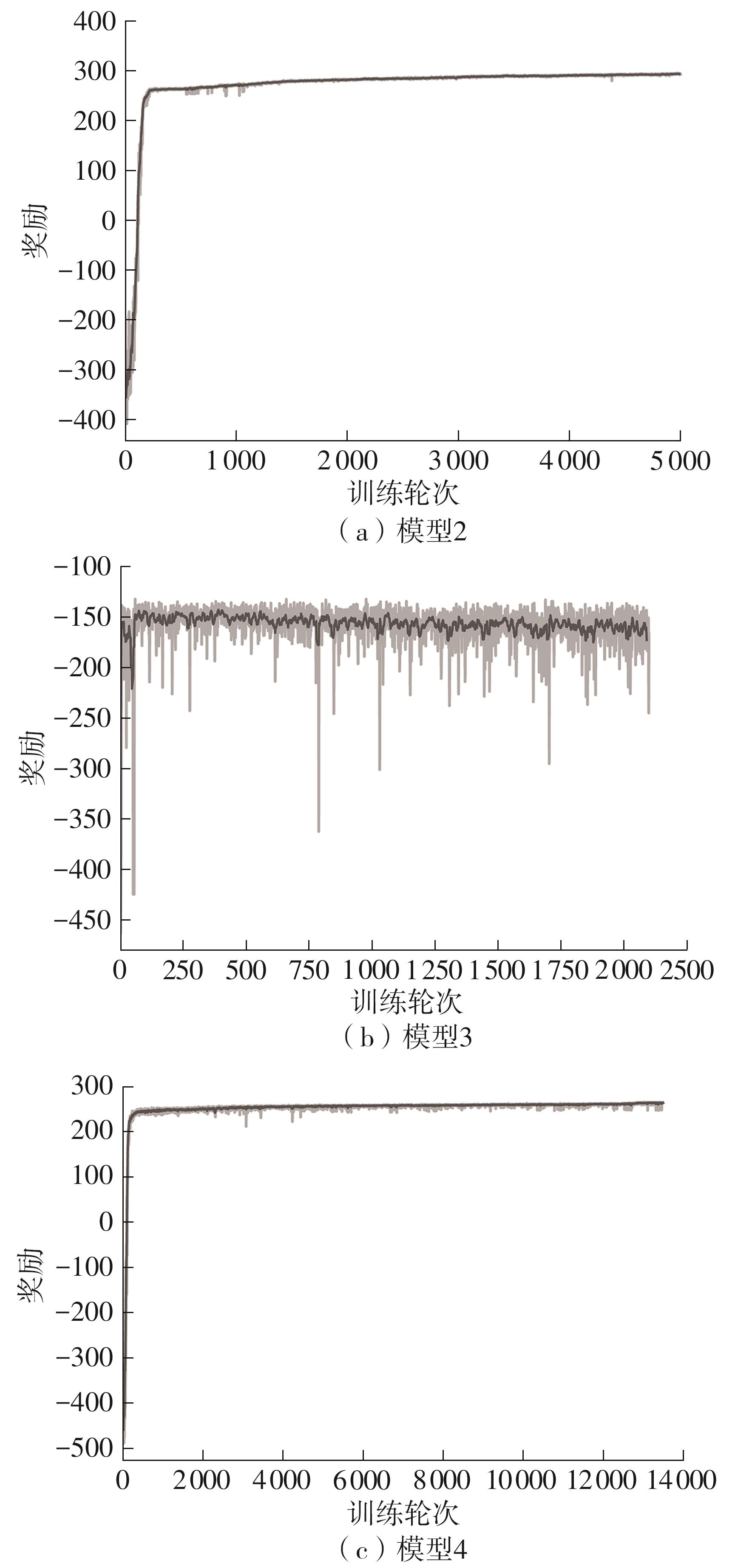
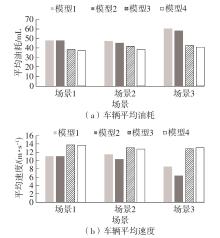
Fig.5
Comparison of average fuel consumption and speed across different models in test scenarios"
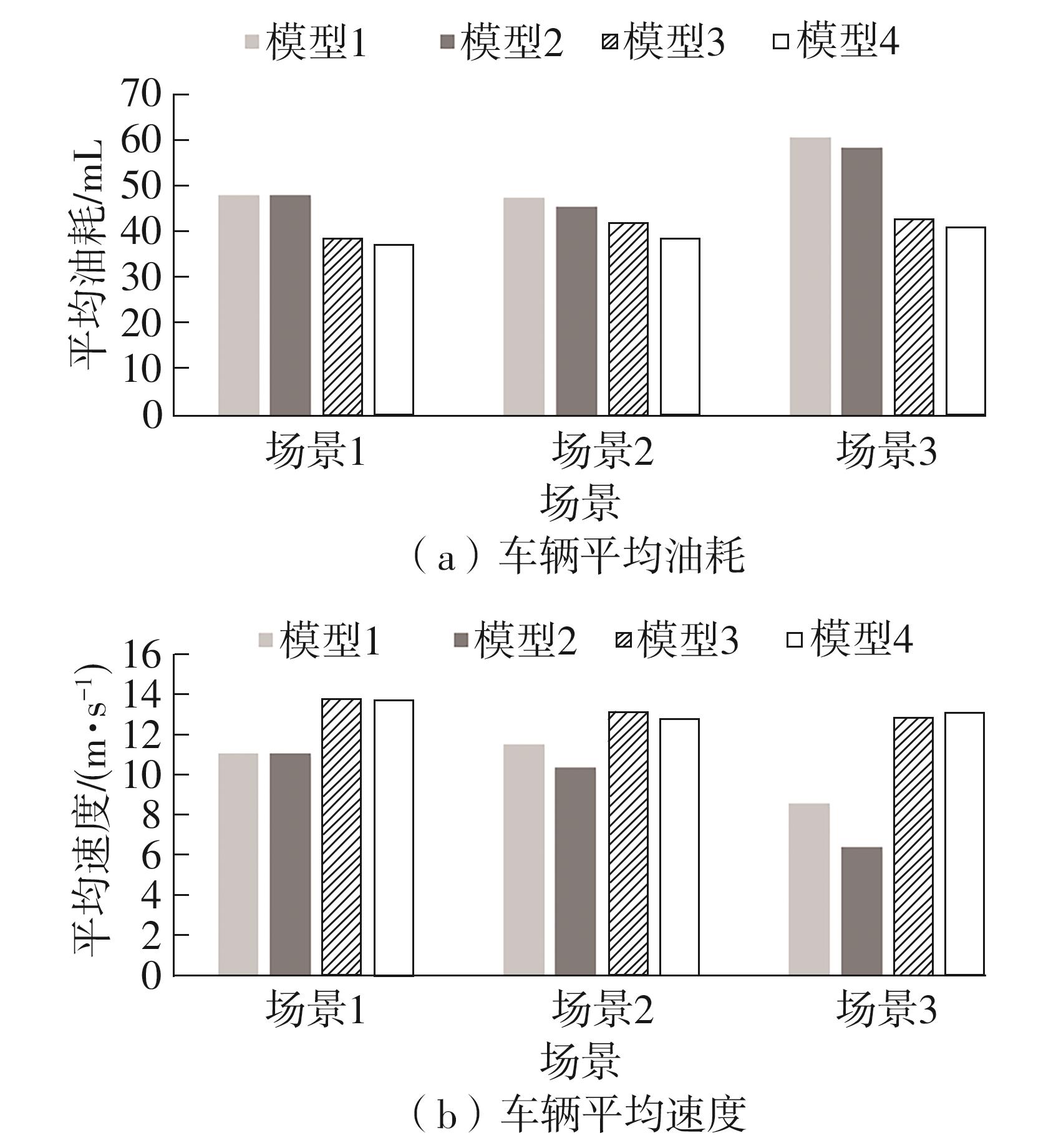

Fig.6
Vehicle trajectory comparison between the proposed dual joint optimization model and single optimization model under scenario 2"
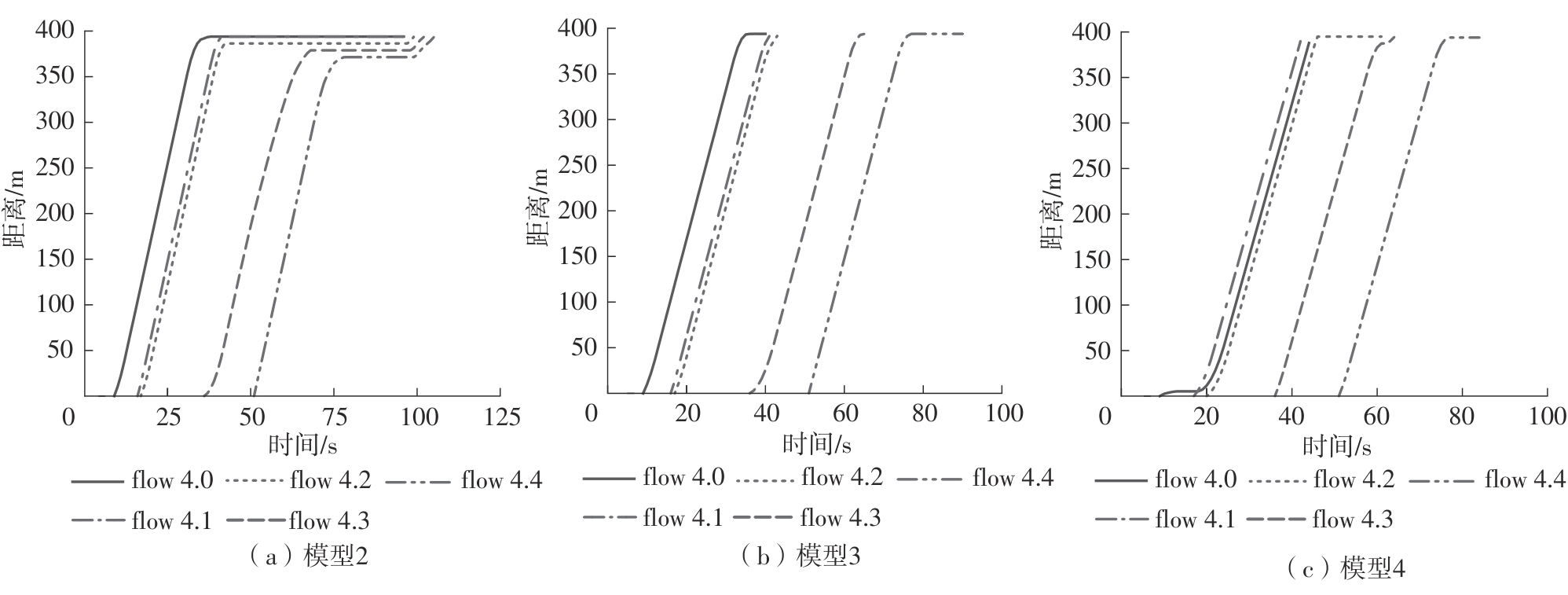

Fig.7
Vehicle speed comparison between the proposed dual joint optimization model and single optimization model under scenario 2"
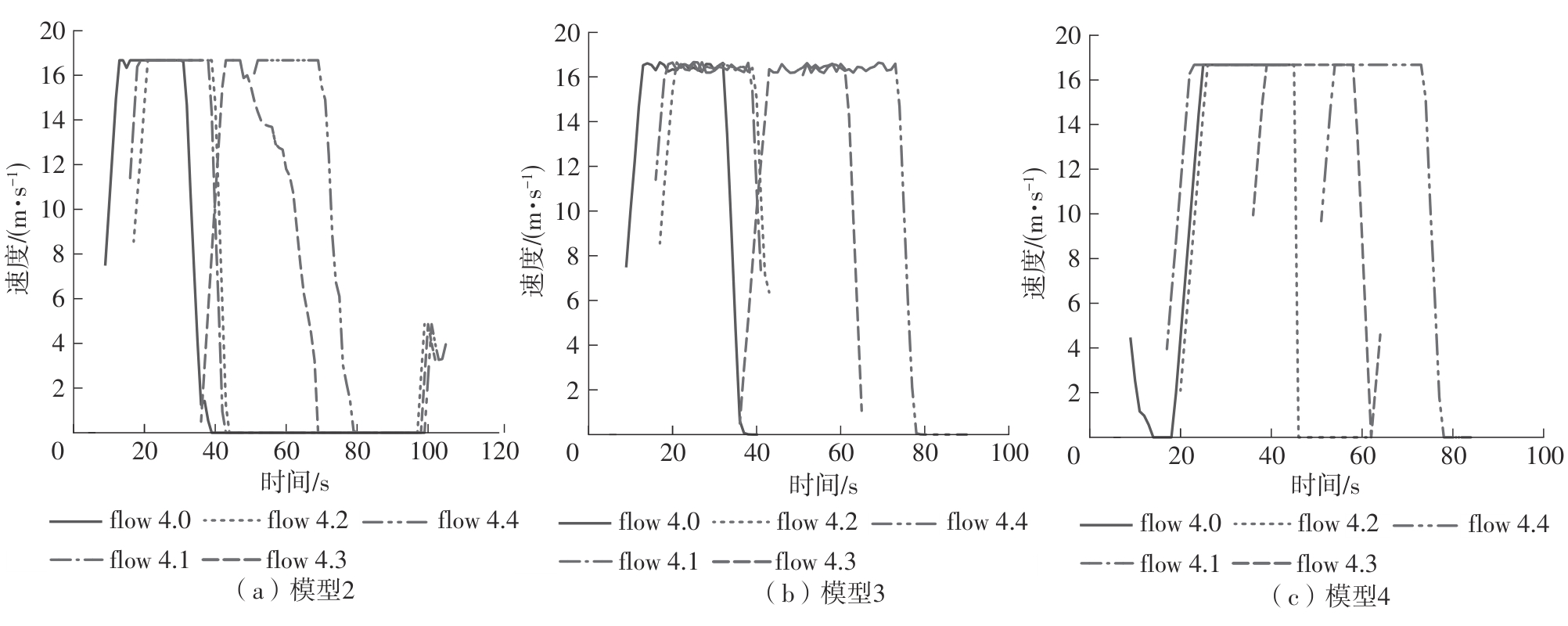
Table 4
Performance of model 4 under different Tsignal values in scenario 2"
| 车辆平均油耗/mL | 车辆平均速度/(m·s-1) | |
|---|---|---|
| 3 | 38.715 5 | 13.763 0 |
| 5 | 40.495 7 | 13.157 8 |
| 7 | 41.544 7 | 12.767 9 |
| 9 | 43.845 7 | 12.871 2 |
Table 5
Parameter values for reinforcement learning parameter testing experiments"
| 参数 | 取值 |
|---|---|
| 熵系数 | 0.1、0.2、0.3、0.4 |
| 折扣因子 | 0.90、0.92、0.94、0.96 |
| 策略网络学习率 | 1 |
| 价值网络学习率 | 1 |
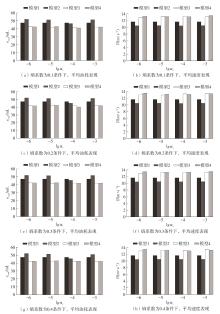
Fig.8
Model results under different entropy coefficients and policy network learning rates"
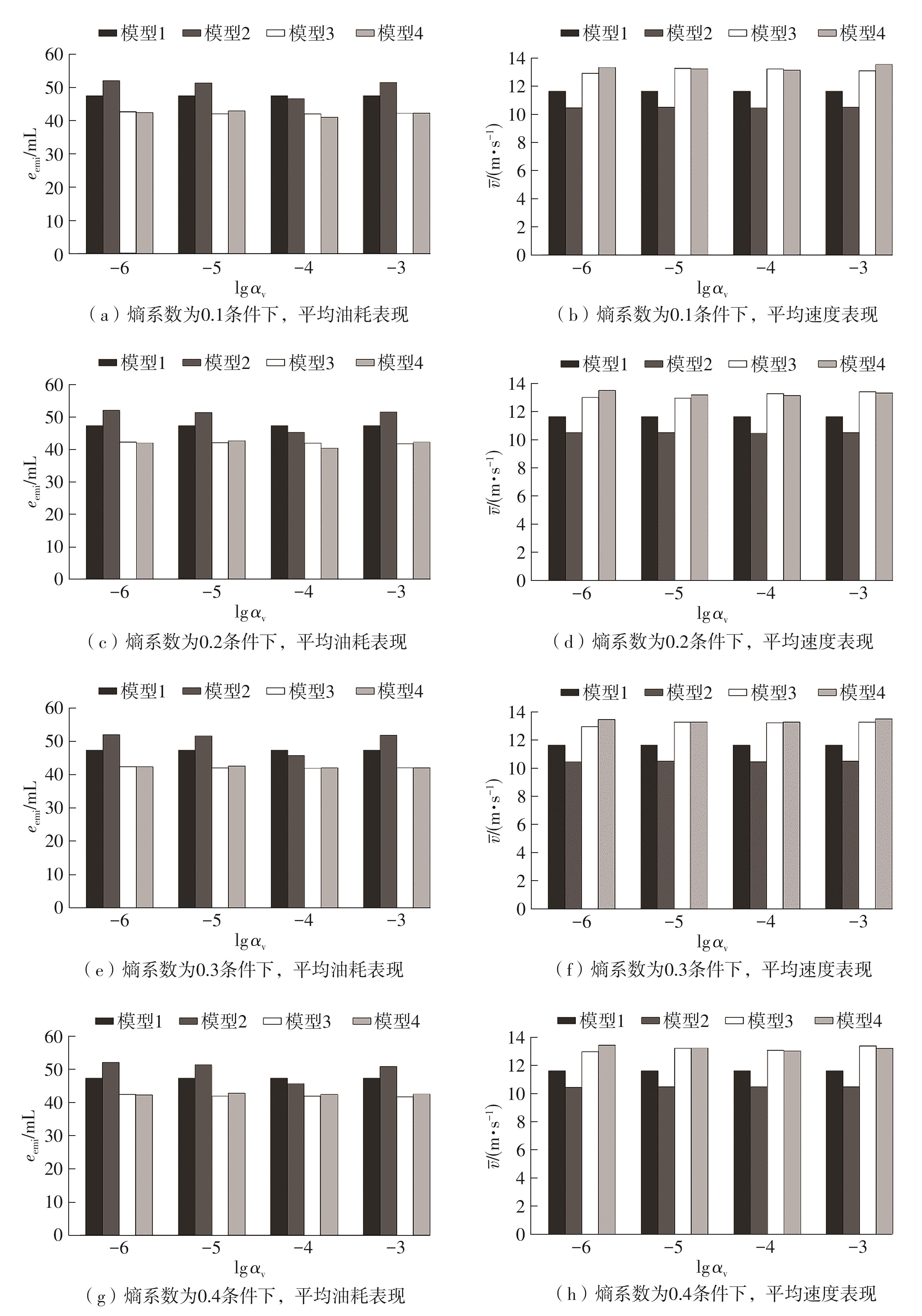
Fig.9
Model results under different discount factors and value network learning rates"
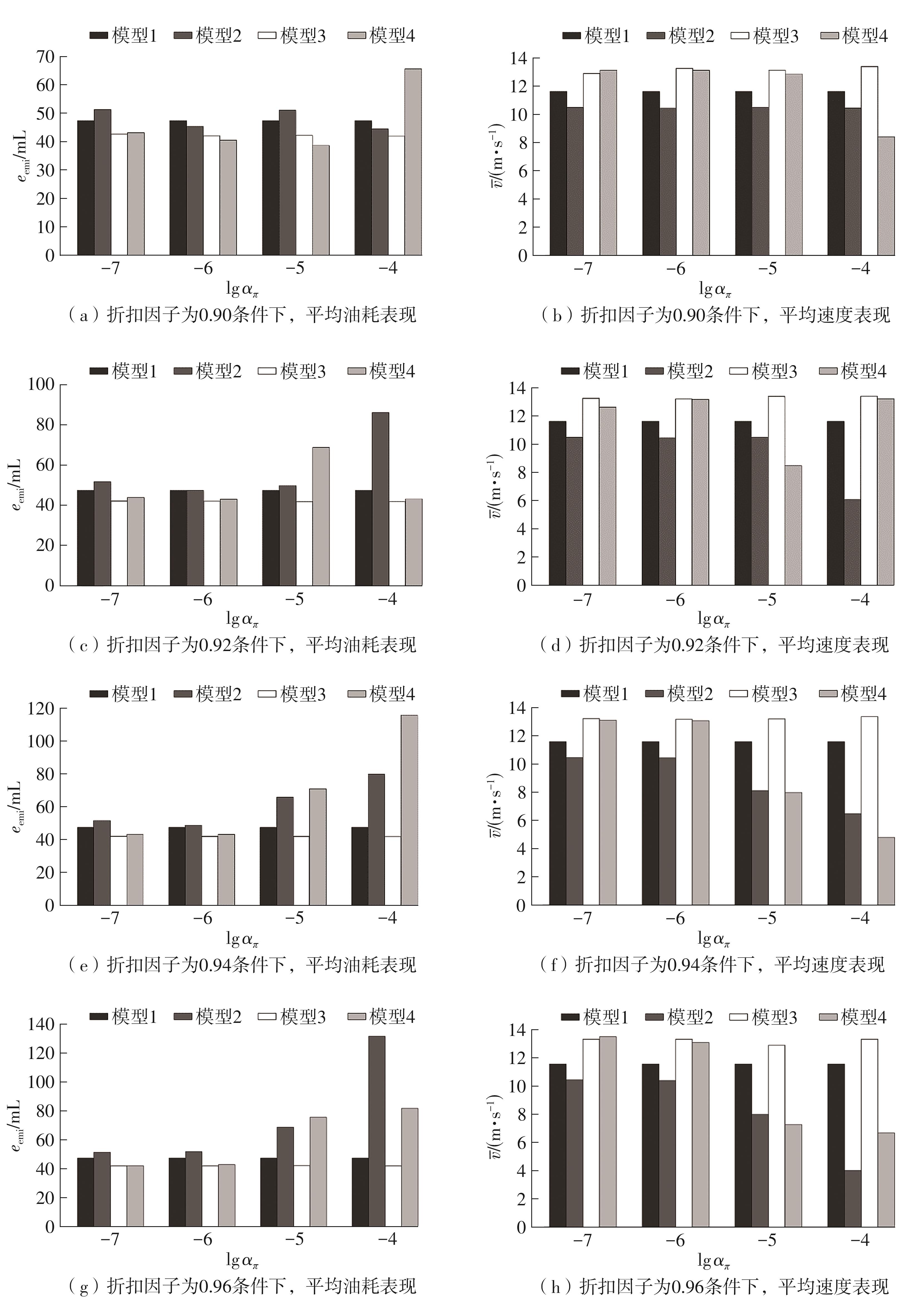
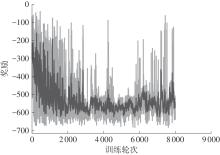
Fig.10
Example of a reward curve from a failed training"
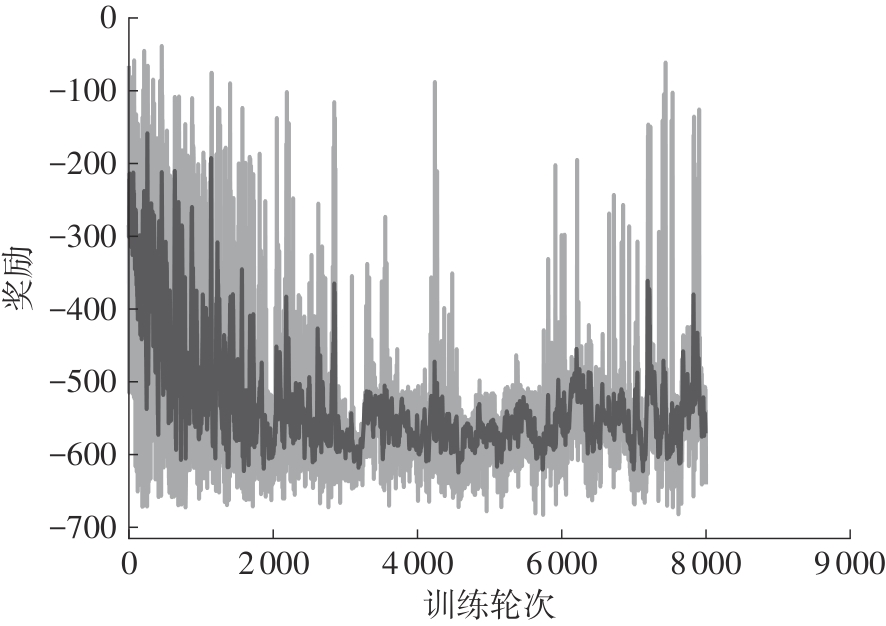
Table 6
Experimental results of robustness testing"
扰动 情况 | 场景 | 平均油耗/mL | 油耗相对偏差/% | 平均速度/(m·s-1) | 速度相对偏差/% |
|---|---|---|---|---|---|
| 无扰动 | 场景1 | 37.41 | 13.81 | ||
| 场景2 | 38.65 | 12.91 | |||
| 场景3 | 41.04 | 13.21 | |||
| 有扰动(均值=0,标准差=1 | 场景1 | 39.12 | 4.58 | 13.43 | 2.75 |
| 场景2 | 40.82 | 5.60 | 12.97 | 0.51 | |
| 场景3 | 43.17 | 5.21 | 12.56 | 4.92 | |
| 有扰动(均值=0,标准差=2) | 场景1 | 39.11 | 4.55 | 14.03 | 1.64 |
| 场景2 | 41.95 | 8.53 | 13.50 | 4.58 | |
| 场景3 | 42.77 | 4.23 | 12.81 | 3.02 |
| [1] | MA W J, WAN L, YU C,et al .Multi-objective optimization of traffic signals based on vehicle trajectory data at isolated intersections[J].Transportation Research Part C:Emerging Technologies,2020,120:102821/1-27. |
| [2] | LIANG X J, GULER S I, GAYAH V V .An equitable traffic signal control scheme at isolated signalized intersections using connected vehicle technology[J].Transportation Research Part C:Emerging Technologies,2020,110:81-97. |
| [3] | ZHANG Y, HAO R, ZHANG T,et al .A trajectory optimization-based intersection coordination framework for cooperative autonomous vehicles[J].IEEE Transactions on Intelligent Transportation Systems,2021,23(9):14674-14688. |
| [4] | HAN X, MA R, ZHANG H M .Energy-aware trajectory optimization of CAV platoons through a signalized intersection[J].Transportation Research Part C:Emer-ging Technologies,2020,118:102652/1-16. |
| [5] | YAO H, CUI J, LI X,et al .A trajectory smoothing method at signalized intersection based on individualized variable speed limits with location optimization[J].Transportation Research Part D:Transport and Environment,2018,62:456-473. |
| [6] | YAO H, LI X .Lane-change-aware connected automated vehicle trajectory optimization at a signalized intersection with multi-lane roads[J].Transportation Research Part C:Emerging Technologies,2021,129:103182/1-43. |
| [7] | MA M, LI Z .A time-independent trajectory optimization approach for connected and autonomous vehicles under reservation-based intersection control[J].Transportation Research Interdisciplinary Perspectives,2021,9:100312/1-11. |
| [8] | YU C, FENG Y, LIU H X,et al .Integrated optimization of traffic signals and vehicle trajectories at isolated urban intersections[J].Transportation Research Part B:Methodological,2018,112:89-112. |
| [9] | GUO Y, MA J, XIONG C,et al .Joint optimization of vehicle trajectories and intersection controllers with connected automated vehicles:combined dynamic programming and shooting heuristic approach[J].Transportation Research Part C:Emerging Technologies,2019,98:54-72. |
| [10] | JIANG X, SHANG Q .A dynamic CAV-dedicated lane allocation method with the joint optimization of signal timing parameters and smooth trajectory in a mixed traffic environment[J].IEEE Transactions on Intelligent Transportation Systems,2022,24(6):6436-6449. |
| [11] | TAJALLI M, HAJBABAIE A .Traffic signal timing and trajectory optimization in a mixed autonomy traffic stream[J].IEEE Transactions on Intelligent Transportation Systems,2021,23(7):6525-6538. |
| [12] | GUAN Y, REN Y, MA H,et al .Learn collision-free self-driving skills at urban intersections with model-based reinforcement learning[C]∥ Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC).Indianapolis,IN:IEEE,2021:3462-3469. |
| [13] | GUTIÉRREZ-MORENO R, BAREA R, LÓPEZ-GUILLÉN E,et al .Reinforcement learning-based autonomous driving at intersections in CARLA simulator[J].Sensors,2022,22(21):8373/1-16. |
| [14] | SILVA V A S, GRASSI V .Addressing lane keeping and intersections using deep conditional reinforcement learning[C]∥ Proceedings of the 2021 Latin American Robotics Symposium (LARS),2021 Brazilian Symposium on Robotics (SBR),and 2021 Workshop on Robotics in Education (WRE).Natal:IEEE,2021:330-335. |
| [15] | REN Y, JIANG J, ZHAN G,et al .Self-learned intelligence for integrated decision and control of automated vehicles at signalized intersections[J].IEEE Transactions on Intelligent Transportation Systems,2022,23(12):24145-24156. |
| [16] | BERNHARD J, POLLOK S, KNOLL A .Addressing inherent uncertainty:risk-sensitive behavior generation for automated driving using distributional reinforcement learning[C]∥ Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (Ⅳ).Paris:IEEE,2019:2148-2155. |
| [17] | BORGES D F, LEITE J P R R, MOREIRA E M,et al .Traffic light control using hierarchical reinforcement learning and options framework[J].IEEE Access,2021,9:99155-99165. |
| [18] | LIANG X, DU X, WANG G,et al .A deep reinforcement learning network for traffic light cycle control [J].IEEE Transactions on Vehicular Technology,2019,68(2):1243-1253. |
| [19] | MO Z, LI W, FU Y,et al .CVLight:decentralized learning for adaptive traffic signal control with connected vehicles[J].Transportation Research Part C:Emerging Technologies,2022,141:103728/1-9. |
| [20] | YANG S, YANG B, KANG Z,et al .IHG-MA:inductive heterogeneous graph multi-agent reinforcement learning for multi-intersection traffic signal control [J].Neural Networks,2021,139:265-277. |
| [21] | ZHANG Y, ZHOU Y, LU H,et al .Cooperative multi-agent actor-critic control of traffic network flow based on edge computing[J].Future Generation Computer Systems,2021,123:128-141. |
| [22] | ABDOOS M, BAZZAN A L C .Hierarchical traffic signal optimization using reinforcement learning and traffic prediction with long-short term memory[J].Expert Systems with Applications,2021,171:114580/1-9. |
| [23] | LEE J, CHUNG J, SOHN K .Reinforcement learning for joint control of traffic signals in a transportation network[J].IEEE Transactions on Vehicular Techno-logy,2020,69(2):1375-1387. |
| [24] | GUO Y, MA J .DRL-TP3:a learning and control framework for signalized intersections with mixed connected automated traffic[J].Transportation Research Part C:Emerging Technologies,2021,132:103416/1-54. |
| [25] | DUAN J, EBEN LI S, GUAN Y,et al .Hierarchical reinforcement learning for self‐driving decision‐making without reliance on labelled driving data[J].IET Intelligent Transport Systems,2020,14(5):297-305. |
| [26] | LIAO J, LIU T, TANG X,et al .Decision-making strategy on highway for autonomous vehicles using deep reinforcement learning[J].IEEE Access,2020,8:177804-177814. |
| [27] | de JESUS J C, KICH V A, KOLLING A H,et al .Soft actor-critic for navigation of mobile robots[J].Journal of Intelligent & Robotic Systems,2021,102(2):1-31. |
| [28] | HAARNOJA T, ZHOU A, HARTIKAINEN K,et al .Soft actor-critic algorithms and applications[EB/OL].(2019-01-29)[2024-11-18].. |
| [29] | WONG C C, CHIEN S Y, FENG H M,et al .Motion planning for dual-arm robot based on soft actor-critic[J].IEEE Access,2021,9:26871-26885. |
| [30] | HE Z, DONG L, SONG C,et al .Multiagent soft actor-critic based hybrid motion planner for mobile robots[J].IEEE Transactions on Neural Networks and Learning Systems,2022,34(12):10980-10992. |
| [31] | TANG H, WANG A, XUE F,et al .A novel hierarchical soft actor-critic algorithm for multi-logistics robots task allocation[J].IEEE Access,2021,9:42568-42582. |
| [32] | KRAUSS S .Microscopic modeling of traffic flow:investigation of collision-free vehicle dynamics[D].Köln:DLR,1998. |
| [33] | KRAUSS S, WAGNER P, GAWRON C .Metastable states in a microscopic model of traffic flow[J].Physical Review E,1997,55(5):5597/1-6. |
| [34] | VINITSKY E, KREIDIEH A, LE FLEM L,et al .Benchmarks for reinforcement learning in mixed-autonomy traffic[C]∥ Proceedings of the Conference on Robot Learning.Zürich:PMLR,2018:399-409. |
| [1] | . A Study on the Impact Mechanism of Human-Machine Mixed DrivingTraffic Flow Under Occasional Accident [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(8): 61-72. |
| [2] | ZHOU Xuan, MO Haohua, YAN Junwei. Investigating an Enhanced H-AC Algorithm-Based Strategy for Energy-Saving Optimization Control in Cold Source System [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(1): 21-31. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||