Journal of South China University of Technology(Natural Science Edition) ›› 2024, Vol. 52 ›› Issue (6): 128-137.doi: 10.12141/j.issn.1000-565X.230143
• Computer Science & Technology • Previous Articles Next Articles
Named Entity Recognition of Traditional Chinese Medicine Classics Based on SiKuBERT and Multivariate Data Embedding
ZHANG Wendong( ), WU Ziwei, SONG Guochang, HUO Qingao, WANG Bo
), WU Ziwei, SONG Guochang, HUO Qingao, WANG Bo
- College of Software,Xinjiang University,Urumqi 830008,Xinjiang,China
-
Received:2023-03-27Online:2024-06-25Published:2023-05-26 -
About author:张文东(1975—),男,博士,副教授,主要从事深度学习、物联网技术研究。E-mail: zwdxju@163.com -
Supported by:the Natural Science Foundation of Xinjiang Uygur Autonomous Region(2020D01C33);the Special Project of Xinjiang Uygur Autonomous Region Key R&D Task(2021B01002)
CLC Number:
Cite this article
ZHANG Wendong, WU Ziwei, SONG Guochang, HUO Qingao, WANG Bo. Named Entity Recognition of Traditional Chinese Medicine Classics Based on SiKuBERT and Multivariate Data Embedding[J]. Journal of South China University of Technology(Natural Science Edition), 2024, 52(6): 128-137.
share this article
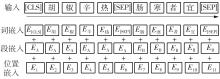
Fig.1
Example of the input representation of BERT[22]"
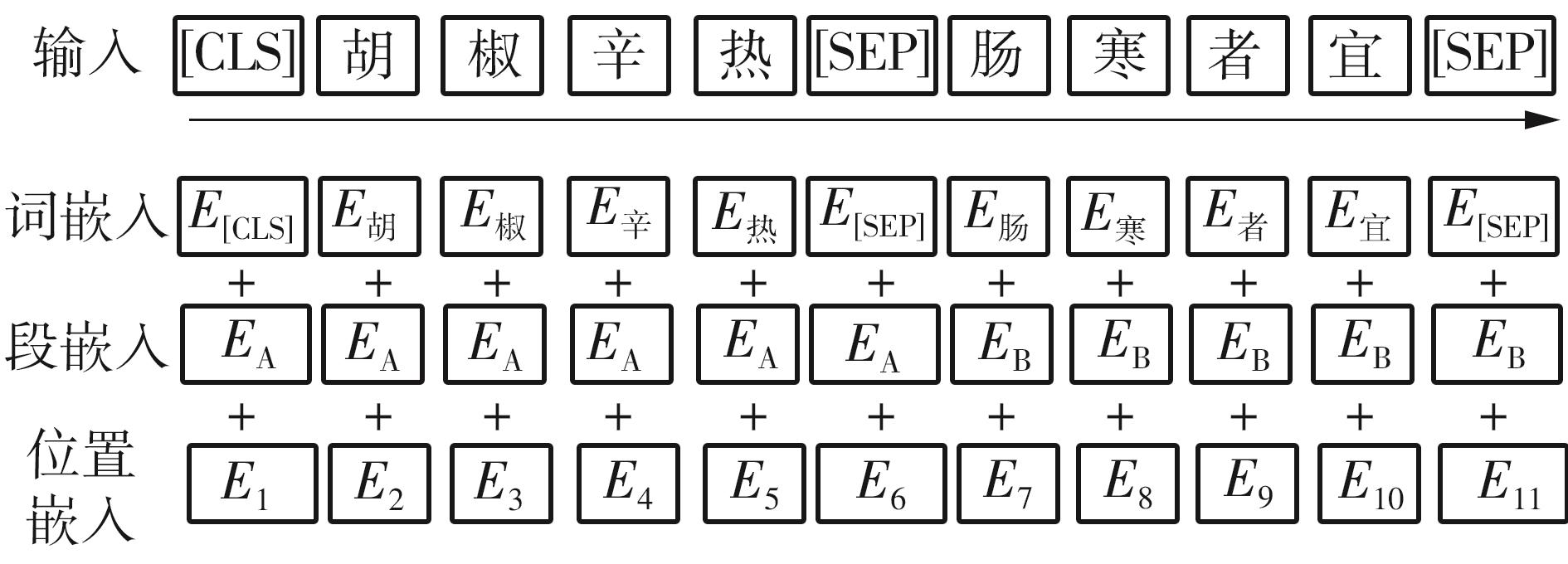
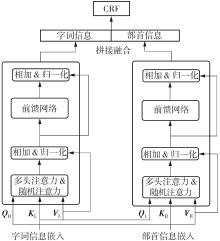
Fig.2
Model of Cross Transformer"
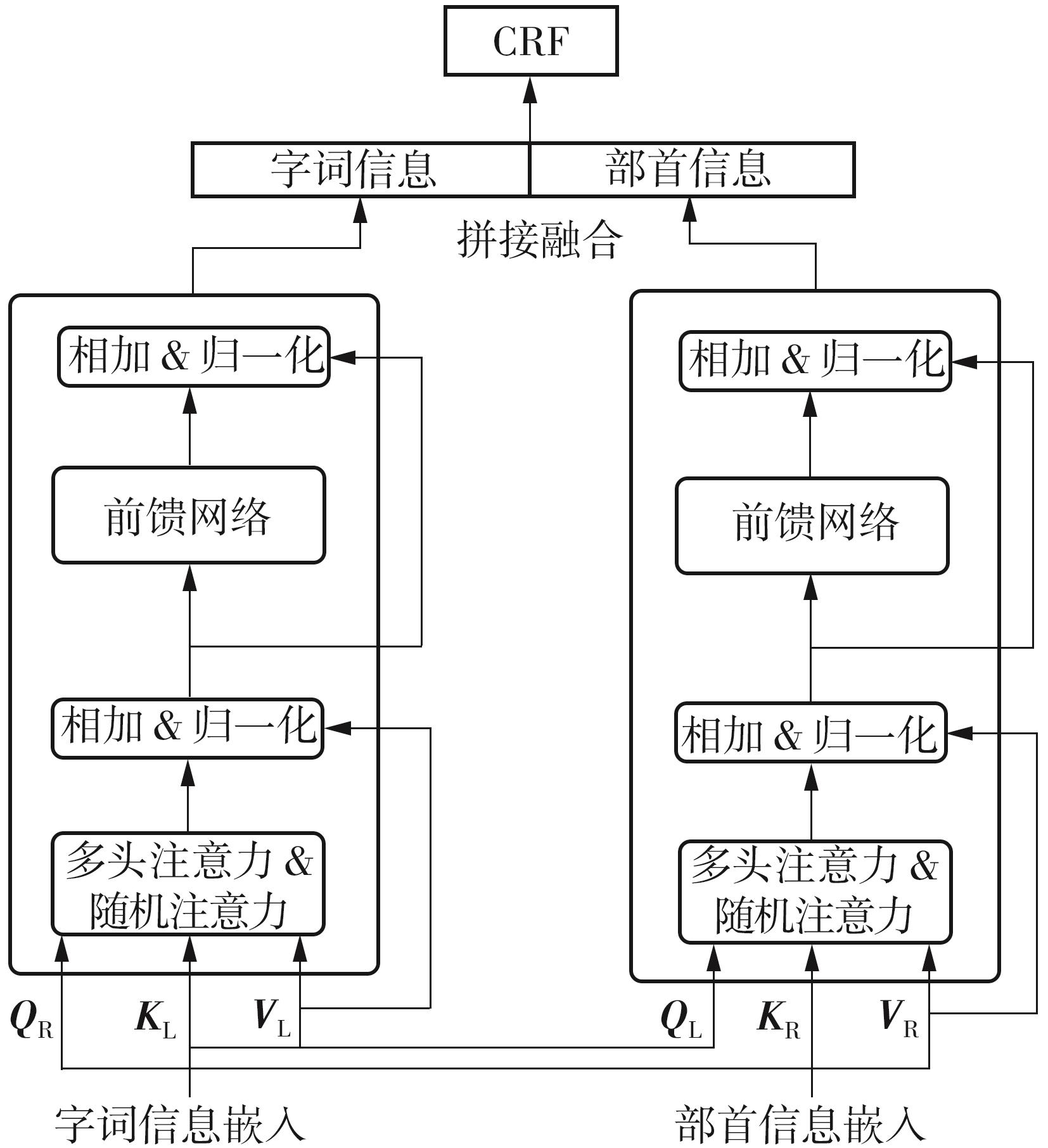
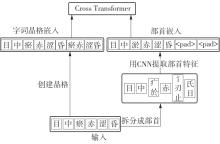
Fig.3
Structure of SiKuBERT-MECT model"
Table 1
Annotation examples of Bencao dataset"
| 字 | 含义 | 实体标签 | 字 | 含义 | 实体标签 | ||
|---|---|---|---|---|---|---|---|
| 时 | 人名 | B-NR | 用 | 非实体 | O | ||
| 珍 | 人名 | E-NR | 茵 | 中草药物名 | B-NZCYW | ||
| 曰 | 非实体 | O | 芋 | 中草药物名 | E-NZCYW | ||
| : | 非实体 | O | 、 | 非实体 | O | ||
| 治 | 非实体 | O | 天 | 中草药物名 | B-NZCYW | ||
| 賊 | 病症名 | B-NBZ | 雄 | 中草药物名 | E-NZCYW | ||
| 風 | 病症名 | E-NBZ | 、 | 非实体 | O | ||
| , | 非实体 | O | 烏 | 中草药物名 | B-NZCYW | ||
| 手 | 病症名 | B-NBZ | 頭 | 中草药物名 | E-NZCYW | ||
| 足 | 病症名 | M-NBZ | 、 | 非实体 | O | ||
| 枯 | 病症名 | M-NBZ | 秦 | 中草药物名 | B-NZCYW | ||
| 痹 | 病症名 | M-NBZ | 艽 | 中草药物名 | E-NZCYW | ||
| 拘 | 病症名 | M-NBZ | 各 | 非实体 | O | ||
| 攣 | 病症名 | E-NBZ | 一 | 非实体 | O | ||
| : | 非实体 | O | 兩 | 非实体 | O | ||
Table 2
Examples of entity types"
| 实体标记 | 含义 | 词例量 | 示例 |
|---|---|---|---|
| NR | 人名 | 6 713 | 时珍、仲景 |
| NZCYW | 中草药物名 | 16 572 | 硼砂、甘草 |
| NBZ | 病症名 | 7 439 | 心痛、身熱 |
| NBL | 病理名 | 1 062 | 腎虛、大腸内熱 |
| NJL | 经络名 | 83 | 足太陰、足陽明 |
Table 3
Overall performance of models"
| 模型 | P | R | F1值 |
|---|---|---|---|
| BiLSTM-CRF[ | 79.85 | 74.12 | 76.81 |
| SiKuBERT-BiLSTM-CRF | 82.75 | 84.61 | 83.66 |
| SiKuBERT-CRF | 85.51 | 82.26 | 83.83 |
| SiKuBERT-FLAT[ | 85.67 | 85.85 | 85.67 |
| BERT-MECT | 85.39 | 86.06 | 85.74 |
| SiKuBERT-MECT | 86.95 | 86.37 | 86.66 |
Table 4
Recognition results of models on detailed entities"
| 模型 | 评估指标 | 识别结果/% | 均值/% | ||||
|---|---|---|---|---|---|---|---|
| 人名 | 中草药物名 | 病症名 | 病理名 | 经络名 | |||
| BiLSTM-CRF | P | 89.09 | 81.12 | 73.08 | 46.15 | 81.82 | 79.85 |
| R | 83.43 | 71.84 | 73.97 | 50.00 | 62.07 | 74.12 | |
| F1值 | 86.16 | 76.19 | 73.52 | 48.00 | 70.59 | 76.81 | |
| SiKuBERT-BiLSTM-CRF | P | 92.96 | 84.97 | 79.20 | 72.73 | 96.00 | 82.75 |
| R | 90.91 | 87.02 | 80.51 | 66.67 | 82.76 | 84.61 | |
| F1值 | 91.92 | 85.98 | 79.85 | 69.57 | 88.89 | 83.66 | |
| SiKuBERT-CRF | P | 91.14 | 82.35 | 78.08 | 30.77 | 84.00 | 85.51 |
| R | 90.63 | 87.20 | 81.27 | 33.33 | 72.41 | 82.26 | |
| F1值 | 90.88 | 84.71 | 79.64 | 32.00 | 77.78 | 83.83 | |
| SiKuBERT-FLAT | P | 94.08 | 87.69 | 76.56 | 57.14 | 69.57 | 85.48 |
| R | 92.27 | 85.33 | 82.69 | 80.00 | 95.47 | 85.85 | |
| F1值 | 93.17 | 86.50 | 79.51 | 66.67 | 80.49 | 85.67 | |
| BERT-MECT | P | 92.10 | 87.41 | 78.32 | 50.72 | 79.53 | 85.39 |
| R | 93.37 | 85.49 | 81.60 | 63.25 | 83.26 | 86.09 | |
| F1值 | 92.73 | 86.45 | 79.93 | 56.29 | 81.35 | 85.74 | |
| SiKuBERT-MECT | P | 93.79 | 88.87 | 78.16 | 57.14 | 84.37 | 86.95 |
| R | 91.71 | 87.52 | 83.23 | 80.23 | 82.61 | 86.37 | |
| F1值 | 92.74 | 88.19 | 80.61 | 66.74 | 83.48 | 86.66 | |
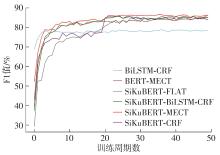
Fig.4
Change of F1 score with time"
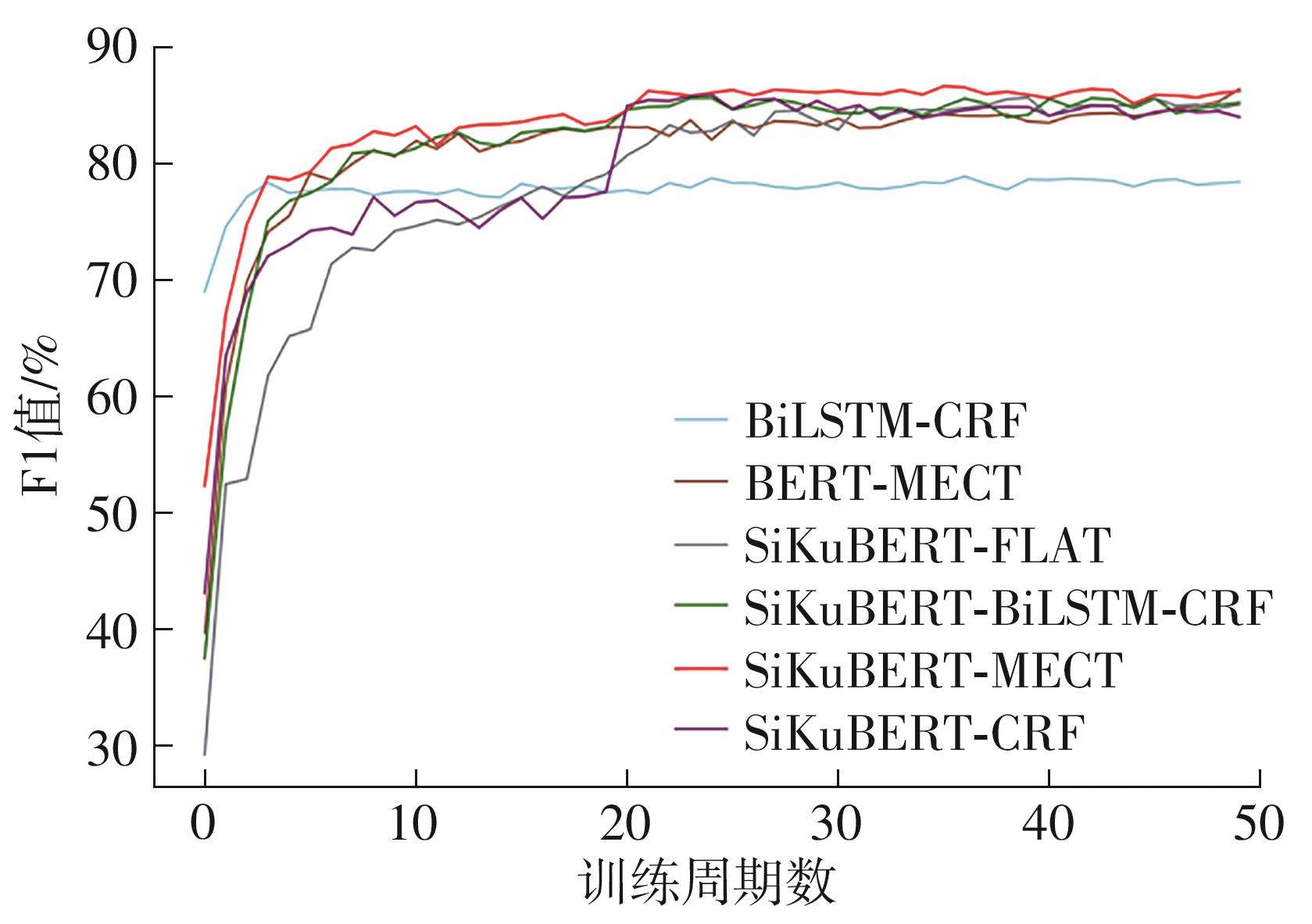
Table 5
Performance of SiKuBERT-MECT model under different learning rates"
| 学习率 | P/% | R/% | F1值/% | |
|---|---|---|---|---|
| BERT | MECT | |||
| 3×10-4 | 5×10-3 | 86.95 | 86.37 | 86.66 |
| 1×10-4 | 1×10-3 | 86.51 | 86.26 | 86.38 |
| 5×10-5 | 5×10-4 | 86.17 | 85.92 | 86.04 |
| 5×10-5 | 1×10-4 | 86.30 | 86.53 | 86.41 |
Table 6
Generalization experiment results in dataset C-CLUE"
| 模型 | P/% | R/% | F1值/% |
|---|---|---|---|
| BERT-base | 44.33 | 53.60 | 48.11 |
| BERT-wwm | 45.42 | 54.33 | 48.95 |
| Robert-zh | 45.40 | 53.00 | 48.61 |
| ZKY-BERT | 44.35 | 53.69 | 48.09 |
| SiKuBERT-MECT | 64.45 | 53.14 | 58.25 |
| 1 | 包振山,宋秉彦,张文博,等 .基于半监督学习和规则相结合的中医古籍命名实体识别研究[J].中文信息学报,2022,36(6):90-100. |
| BAO Zhenshan, SONG Bingyan, ZHANG Wenbo,et al .Named entity recognition in traditional Chinese medicine books combining semi-supervised learning and rule-based approach[J].Journal of Chinese Information Processing,2022,36(6):90-100. | |
| 2 | 高甦,陶浒,蒋彦钊,等 .中医文献的句子级联合事件抽取[J].情报工程,2021,7(5):15-29. |
| GAO Su, TAO Hu, JIANG Yanzhao,et al .Sentence-level joint event extraction of traditional Chinese medical literature[J].Technology Intelligence Engineering,2021,7(5):15-29. | |
| 3 | 李芊芊,付兴,杨凤,等 .基于“病脉证并治”诊疗思维的《伤寒论》知识图谱构建与应用[J].世界科学技术-中医药现代化,2022,24(9):3613-3621. |
| LI Qianqian, FU Xing, YANG Feng,et al .Construction and application of Treatise on ColdPathogenic Diseases knowledge graph based on the diagnosis-treatment thinking of “Treatment Based on Disease and Pulse and Syndrome Together”[J].Modernization of Traditional Chinese Medicine and Materia Medica-World Science and Technology,2022,24(9):3613-3621. | |
| 4 | MA Y, LIU Y, ZHANG D,et al .A multigranularity text driven named entity recognition CGAN model for traditional Chinese medicine literatures[J].Computational Intelligence and Neuroscience,2022,2022(1),1495841/1-11. |
| 5 | 易钧汇,查青林 .中医症状信息抽取研究综述[J].计算机工程与应用,2023,59(17):35-47. |
| YI Junhui, ZHA Qinglin .Survey of TCM symptom information extraction[J].Computer Engineering and Applications,2023,59(17):35-47. | |
| 6 | FUKUDA K, TSUNODA T, TAMURA A,et al .Toward information extraction:identifying protein names from biological papers[J].Pacific Symposium on Biocomputing Pacific Symposium on Biocomputing,1997,98:707-718. |
| 7 | BIKEL D M, MILLER S, SCHWARTZ R,et al .Nymble:a high-performance learning name-finder[C]∥Proceedings of the Fifth Conference on Applied Natural Language Processing.Washington DC:Association for Computational Linguistics,1997:194-201. |
| 8 | JAYNESE T .Information theory and statistical mechanics[J].Physical Review,1957,106(4):620-630. |
| 9 | MCCALLUM A, LI W .Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons[C]∥Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003.Edmonton:Association for Computational Linguistics,2003:188-191. |
| 10 | ASAHARA M, MATSUMOTO Y .Japanese named entity extraction with redundant morphological analysis[C]∥Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology.Edmonton:Association for Computational Linguistics,2003:8-15. |
| 11 | 王世昆,李绍滋,陈彤生 .基于条件随机场的中医命名实体识别[J].厦门大学学报(自然科学版),2009,48(3):359-364. |
| WANG Shikun, LI Shaozi, CHEN Tongsheng .Recognition of Chinese medicine named entity based on condition random field[J].Journal of Xiamen University (Natural Science),2009,48(3):359-364. | |
| 12 | 刘凯,周雪忠,于剑,等 .基于条件随机场的中医临床病历命名实体抽取[J].计算机工程,2014,40(9):312-316. |
| LIU Kai, ZHOU Xuezhong, YU Jian,et al .Named entity extraction of traditional Chinese medicine medical records based on conditional random field[J].Computer Engineering,2014,40(9):312-316. | |
| 13 | 孟洪宇,谢晴宇,常虹,等 .基于条件随机场的《伤寒论》中医术语自动识别[J].北京中医药大学学报,2015,38(9):587-590. |
| MENG Hongyu, XIE Qingyu, CHANG Hong,et al .Automatic identification of TCM terminology in Shanghan Lun based on conditional random field[J].Journal of Beijing University of Traditional Chinese Medicine,2015,38(9):587-590. | |
| 14 | LAMPLE G, BALLESTEROS M, SUBRAMANIAN S,et al .Neural architectures for named entity recognition[C]∥Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.San Diego:Association for Computational Linguistics,2016:260-270. |
| 15 | 高甦,金佩,张德政 .基于深度学习的中医典籍命名实体识别研究[J].情报工程,2019,5(1):113-123. |
| GAO Su, JIN Pei, ZHANG Dezheng .Research on named entity recognition of TCM classics based on deep learning[J].Technology Intelligence Engineering,2019,5(1):113-123. | |
| 16 | 李明浩,刘忠,姚远哲 .基于LSTM-CRF的中医医案症状术语识别[J].计算机应用,2018,38(S2):42-46. |
| LI Minghao, LIU Zhong, YAO Yuanzhe .LSTM-CRF based symptom term recognition on traditional Chinese medical case[J].Journal of Computer Applications,2018,38(S2):42-46. | |
| 17 | 崔丹丹,刘秀磊,陈若愚,等 .基于Lattice LSTM的古汉语命名实体识别[J].计算机科学,2020,47(S2):18-22. |
| CUI Dandan, LIU Xiulei, CHEN Ruoyu,et al .Named entity recognition in field of ancient Chinese based on Lattice LSTM[J].Computer Science,2020,47(S2):18-22. | |
| 18 | 屈倩倩,阚红星 .基于Bert-BiLSTM-CRF的中医文本命名实体识别[J].电子设计工程,2021,29(19):40-43,48. |
| QU Qianqian, KAN Hongxing .Named entity recognition of Chinese medical text based on Bert-BiLSTM-CRF[J].Electronic Design Engineering,2021,29(19):40-43,48. | |
| 19 | 谢靖,刘江峰,王东波 .古代中国医学文献的命名实体识别研究——以Flat-lattice增强的SikuBERT预训练模型为例[J].图书馆论坛.2022,42(10):51-60. |
| XIE Jing, LIU Jiangfeng, WANG Dongbo .Study on named entity recognition of traditional Chinese medicine classics:taking SikuBERT pre-training model enhanced by the Flat-lattice transformer for example[J].Library Tribune,2022,42(10):51-60. | |
| 20 | ZHAO J, ZHU W, CHEN C .Chinese named entity recognition based on character level multi feature fusion[C]∥Proceedings of the 2022 7th International Conference on Intelligent Computing and Signal Processing (ICSP).Xi’an:IEEE,2022:1471-1475. |
| 21 | MIKOLOV T, CHEN K, CORRADO G,et al .Efficient estimation of word representations in vector space[EB/OL].(2013-09-07)[2023-01-29].. |
| 22 | ASHISH V, NOSM S, NIKI P,et al .Attention is all you need[C]∥Proceedings of the 31st International Conference on Neural Information Processing Systems.Red Hook:Curran Associates Inc,2017:6000-6010. |
| 23 | JACOB D, CHANG MV, KENTON L,et al .BERT:pre-training of deep bidirectional transformers for language understanding[C]∥Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Minneapolis:Association for Computational Linguistics,2019:4171-4186. |
| 24 | LEE J, YOON W, KIM S,et al .BioBERT:a pre-trained biomedical language representation model for biomedical text mining[J].Bioinformatics,2020,36(4):1234-1240. |
| 25 | LEE J S, HSIANG J .Patentbert:patent classification with finetuning a pretrained bert model[EB/OL].(2019-07-01)[2023-02-24].. |
| 26 | ZHANG Y, YANG J .Chinese NER using lattice LSTM[C]∥Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics.Melbourne:Association for Computational Linguistics,2018:1554-1564, |
| 27 | LI X, YAN P, QIU X,et al .FLAT:Chinese NER using flat-lattice transformer[C]∥Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.[S.l.]:Association for Computational Linguistics,2020:6836-6842. |
| 28 | LIU T, GAO J, NI W,et al .A multi-granularity word fusion method for Chinese NER[J].Applied Sciences,2023,13(5):2789/1-15. |
| 29 | ASUDANI D, NAGWANI N, SINGH P .Impact of word embedding models on text analytics in deep learning environment:a review[J].Artificial Intelligence Review,2023,56(9):10345-10425. |
| 30 | LI M, YANG H, LIU ,Y. Biomedical named entity recognition based on fusion multi-features embedding[J].Technology and Health Care,2023,31(S1):111-121. |
| 31 | DONG C, ZHANG J, ZONG C,et al .Character-based LSTM-CRF with radical-level features for Chinese named entity recognition[C]∥Proceedings of the International Conference on Computer Processing of Oriental Languages & the National CCF Conference on Natural Language Processing and Chinese Computing.Kunming:Springer,2016:239-250. |
| 32 | WU S, SONG X, FENG Z .MECT:multi-metadata embedding based cross transformer for Chinese named entity recognition[C]∥Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing.[S. l.]:Association for Computational Linguistics,2021:1529-1539. |
| 33 | 中医研究院 .中医名词术语选释[M].北京:人民卫生出版社,1973. |
| 34 | LIU X, YANG N, JIANG Y,et al .A parallel computing-based deep attention model for named entity recognition[J].The Journal of Supercomputing,2020:76:814-830. |
| [1] | WANG Jie, XIA Xiaoming . BiLSTM-BiDAF Named Entity Recognition Based on Machine Reading Comprehension [J]. Journal of South China University of Technology(Natural Science Edition), 2022, 50(12): 80-88. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||