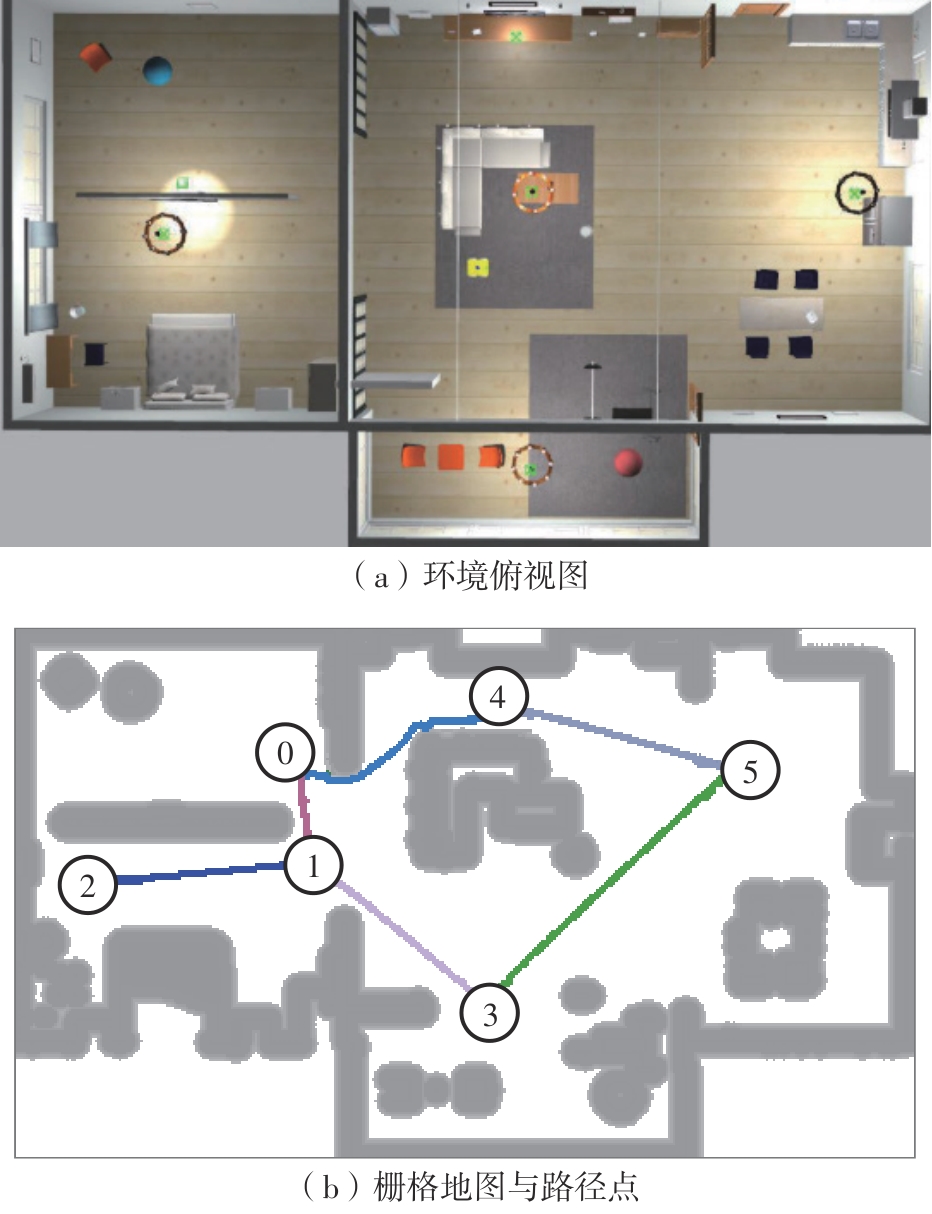
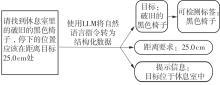
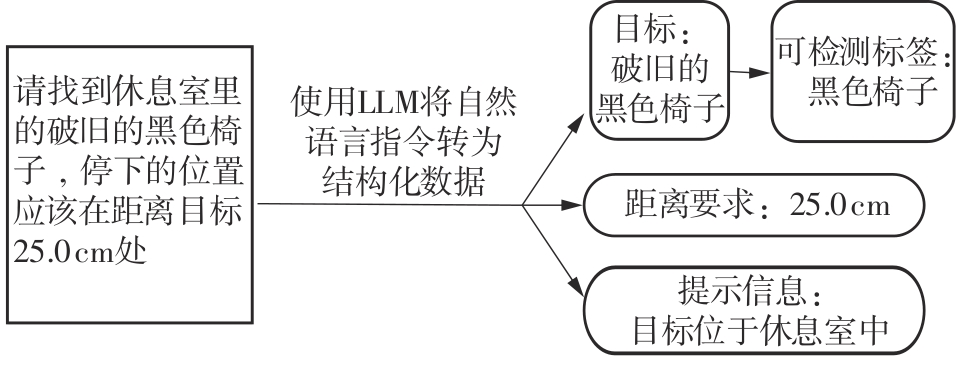
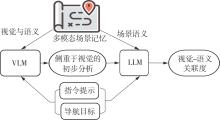
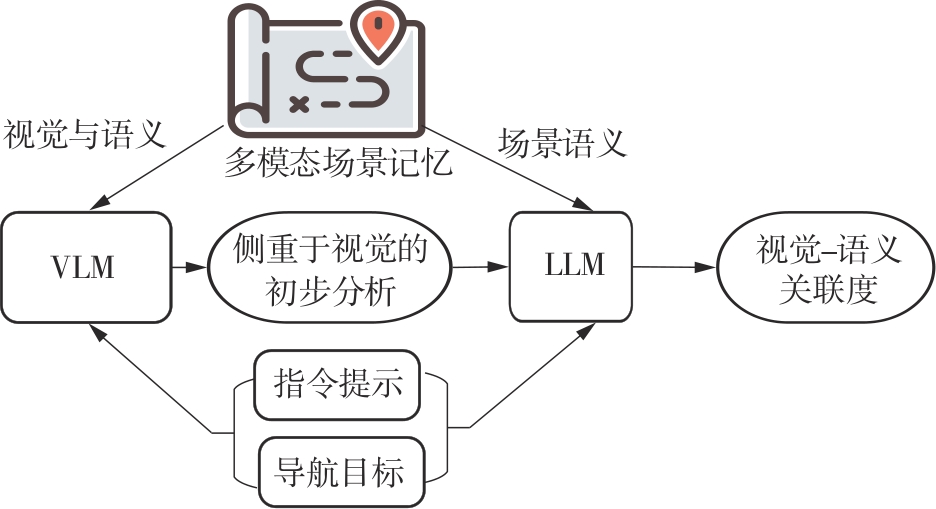
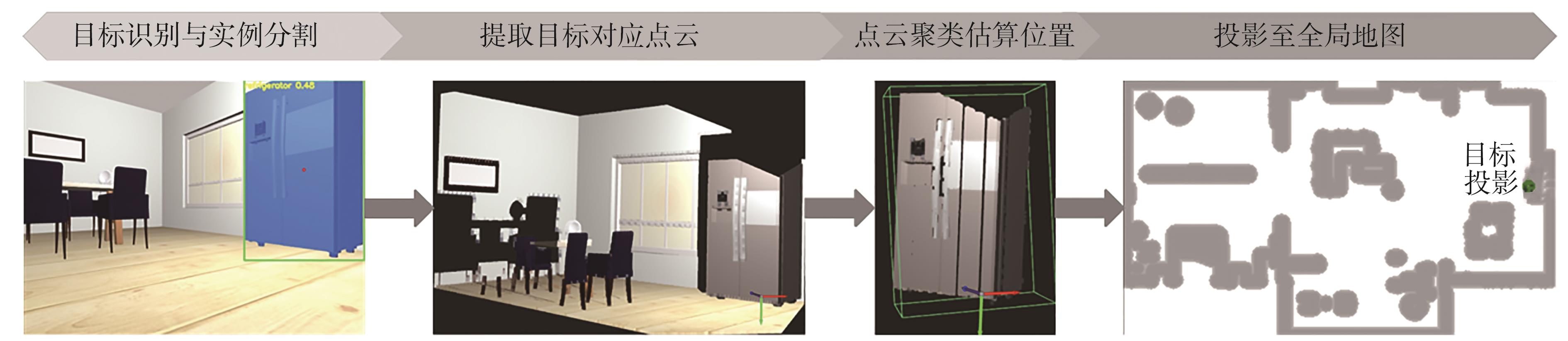
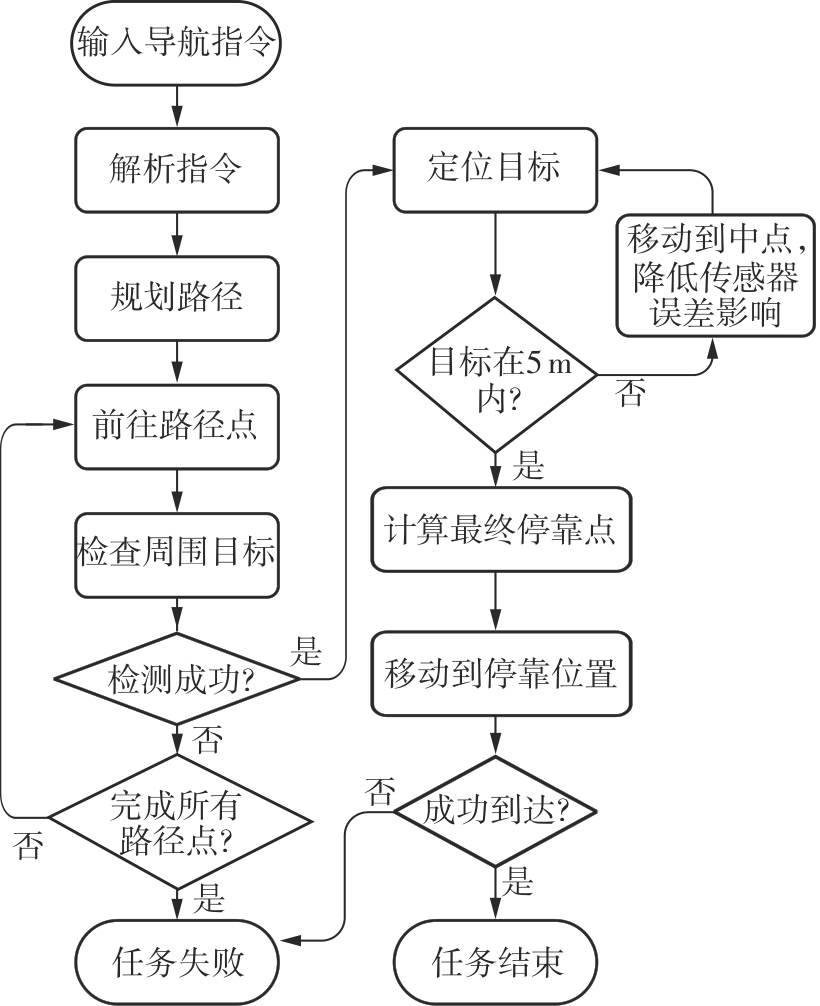
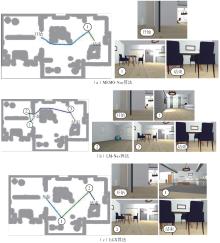
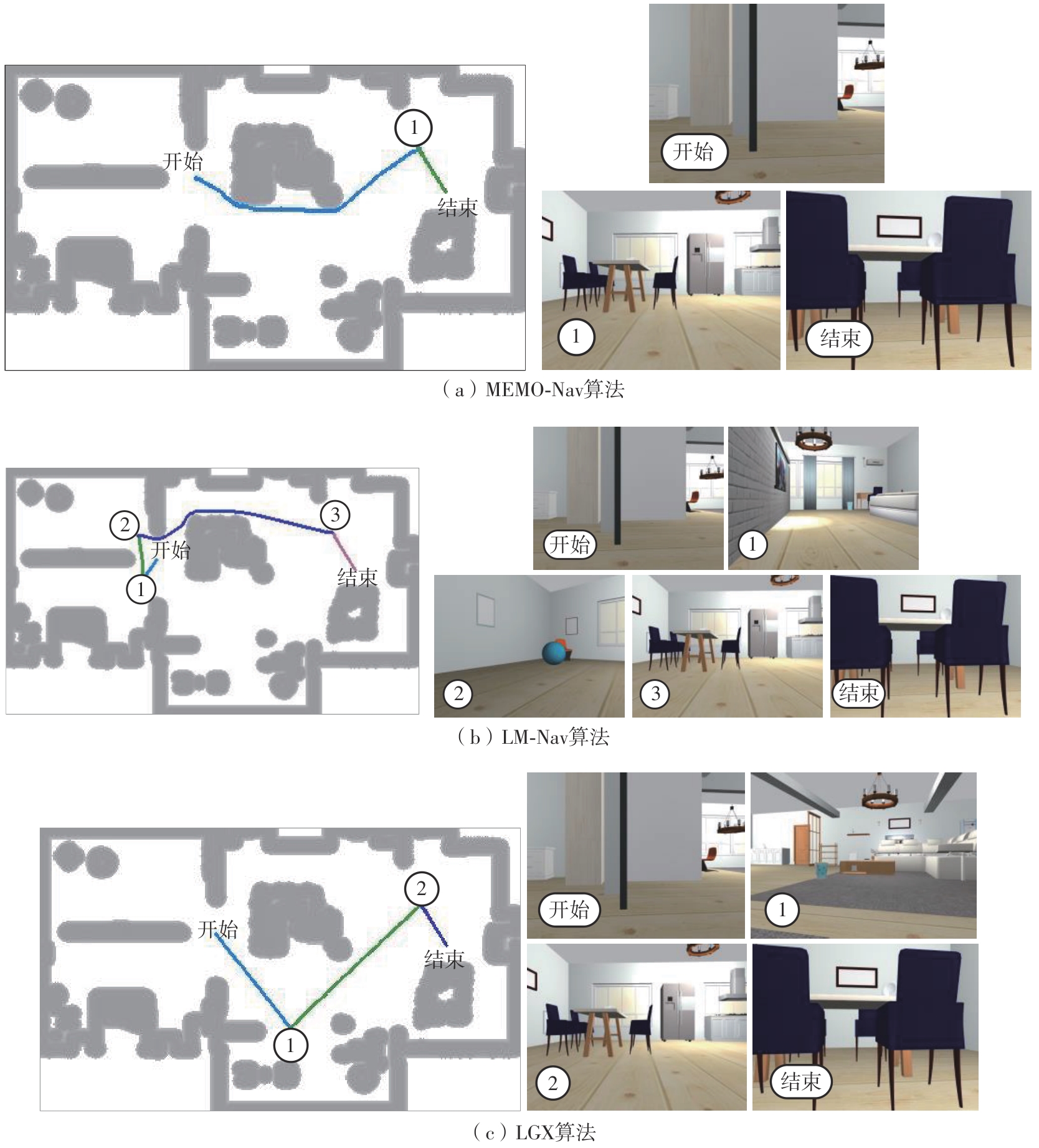
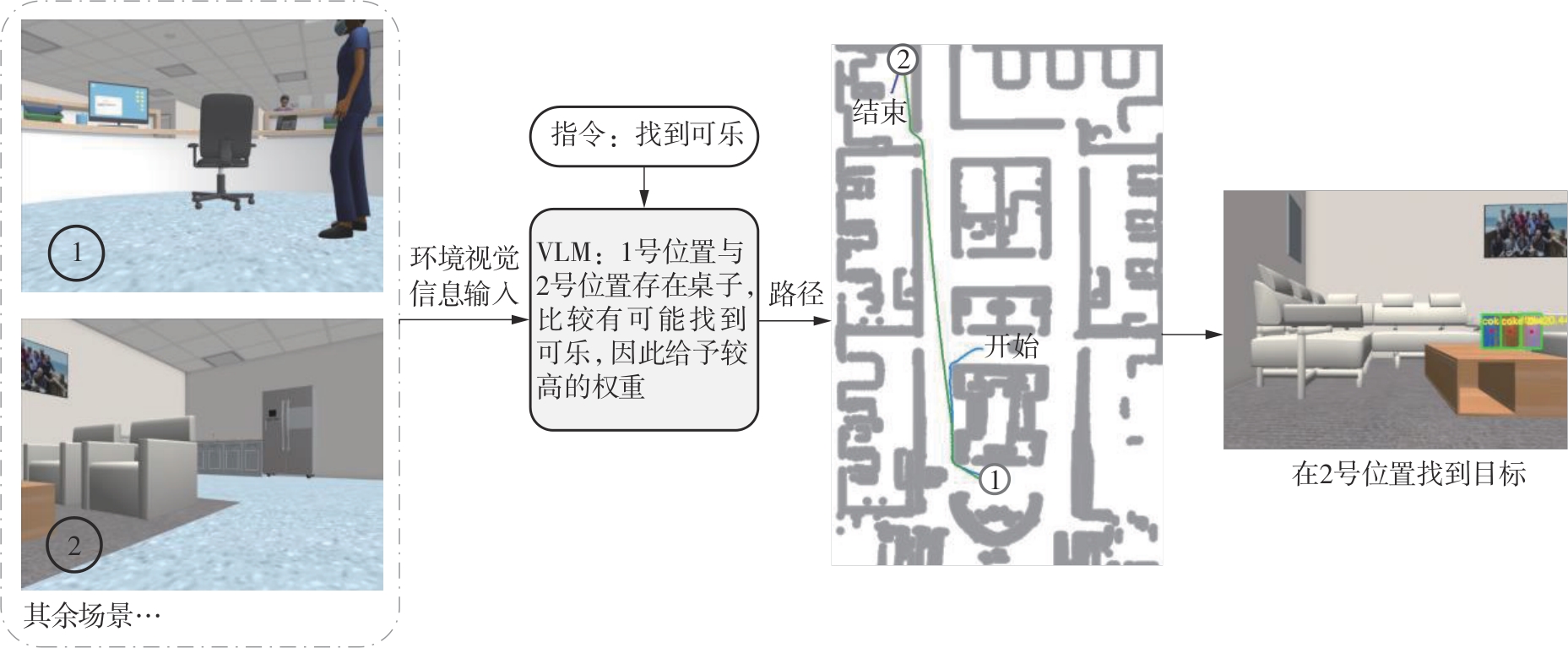
| [1] |
SUN J, WU J, JI Z,et al .A survey of object goal navigation[J].IEEE Transactions on Automation Science and Engineering,2024,22:2292-2308.
|
| [2] |
LI B, HAN J, CHENG Y,et al .Object goal navigation in embodied AI:a survey[C]∥ Proceedings of 2022 the 4th International Conference on Video,Signal and Image Processing.Shanghai:ACM,2022:87-92.
|
| [3] |
ZHU Y, MOTTAGHI R, KOLVE E,et al .Target-driven visual navigation in indoor scenes using deep reinforcement learning [C]∥ Proceedings of 2017 IEEE International Conference on Robotics and Automation.Singapore:IEEE,2017:3357-3364.
|
| [4] |
CHAPLOT D S, GANDHI D P, GUPTA A,et al .Object goal navigation using goal-oriented semantic exploration[C]∥ Proceedings of the 34th Conference on Advances in Neural Information Processing Systems.[S.l.]:Curran Associates,2020:4247-4258.
|
| [5] |
VASWANI A, SHAZEER N, PARMAR N,et al .Attention is all you need [C]∥ Proceedings of the 31st Conference on Neural Information Processing Systems.Long Beach:Curran Associates,2017:5998-6008.
|
| [6] |
DU H, YU X, ZHENG L .VTNet:visual transformer network for object goal navigation[C]∥ Proceedings of the 9th International Conference on Learning Representations.[S.l.]:OpenReview,2021:1-16.
|
| [7] |
FUKUSHIMA R,OTA K, KANEZAKI A,et al .Object memory transformer for object goal navigation [C]∥ Proceedings of 2022 International Conference on Robotics and Automation.Philadelphia:IEEE,2022:11288-11294.
|
| [8] |
ZHOU K, GUO C, ZHANG H,et al .Optimal graph transformer Viterbi knowledge inference network for more successful visual navigation[J].Advanced Engineering Informatics,2023,55,101889/ 1-11.
|
| [9] |
DU H, LI L, HUANG Z,et al .Object-goal visual navigation via effective exploration of relations among historical navigation states[C]∥ Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Vancouver:IEEE,2023:2563-2573.
|
| [10] |
SHAH D, EYSENBACH B, KAHN G,et al .ViNG:learning open-world navigation with visual goals[C]∥ Proceedings of 2021 IEEE International Conference on Robotics and Automation.Xi’ an:IEEE,2021:13215-13222.
|
| [11] |
SHAH D, SRIDHAR A, DASHORA N,et al .ViNT:a foundation model for visual navigation[C]∥ Procee-dings of the 7th Conference on Robot Learning.Atlanta:OpenReview,2023:711-733.
|
| [12] |
SHAH D, OSINSKI B, LEVINE S,et al .LM-Nav:robotic navigation with large pre-trained models of language,vision,and action[C]∥ Proceedings of the 6th Conference on Robot Learning.Auckland:OpenReview,2022:492-504.
|
| [13] |
RADFORD A, KIM J W, HALLACY C,et al .Learning transferable visual models from natural language supervision[C]∥ Proceedings of the 38th International Conference on Machine Learning.[S.l.]:ML Research Press,2021:8748-8763.
|
| [14] |
DORBALA V S, MULLEN J F, MANOCHA D .Can an embodied agent find your “cat-shaped mug”?LLM-based zero-shot object navigation[J].IEEE Robotics and Automation Letters,2024,9(5):4083-4090.
|
| [15] |
SHAH D, EQUI M R, OSINSKI B,et al .Navigation with large language models:semantic guesswork as a heuristic for planning[C]∥ Proceedings of the 7th Conference on Robot Learning.Atlanta:OpenReview,2023:2683-2699.
|
| [16] |
ZHOU G, HONG Y, WU Q .NavGPT:explicit reasoning in vision-and-language navigation with large language models[C]∥ Proceedings of the 38th AAAI Conference on Artificial Intelligence.Vancouver:AAAI,2024:7641-7649.
|
| [17] |
HUANG W, XIA F, SHAH D,et al .Grounded decoding:guiding text generation with grounded models for embodied agents[C]∥ Proceedings of the 37th Conference on Neural Information Processing Systems.New Orleans:Curran Associates,2023:59636-59661.
|
| [18] |
LONG Y, CAI W, WANG H,et al .InstructNav:zero-shot system for generic instruction navigation in unexplored environment[C]∥ Proceedings of the 8th Conference on Robot Learning.Munich:OpenReview,2024:2049-2060.
|
| [19] |
MACENSKI S, FOOTE T, GERKEY B,et al .Robot operating system 2:design,architecture,and uses in the wild[J].Science Robotics,2022,7:eabm6074/1-12.
|
| [20] |
MACENSKI S, SORAGNA A, CARROLL M,et al .Impact of ROS 2 node composition in robotic systems [J].IEEE Robotics and Automation Letters,2023,8(7):3996-4003.
|
| [21] |
丛明,温旭,王明昊,等 .基于迭代卡尔曼滤波器的GPS-激光-IMU融合建图算法[J].华南理工大学学报(自然科学版),2024,52(3):75-83.
|
|
CONG Ming, WEN Xu, WANG Minghao,et al .A GPS-laser-IMU fusion mapping algorithm based on ite-rated Kalman filter[J].Journal of South China University of Technology (Natural Science Edition),2024,52(3):75-83.
|
| [22] |
KHANAM R, HUSSAIN M .YOLOv11:an overview of the key architectural enhancements[EB/OL].(2024-10-23)[2025-01-10]..
|
| [23] |
MINDERER M, GRITSENKO A, HOULSBY N .Scaling open-vocabulary object detection[C]∥ Proceedings of the 37th Conference on Neural Information Processing Systems.New Orleans:Curran Associates,2023:72983-73007.
|
| [24] |
KIRILLOV A, MINTUN E, RAVI N,et al .Segment anything[C]∥ Proceedings of 2023 IEEE/CVF International Conference on Computer Vision.Paris:IEEE,2023:3992-4003.
|
| [25] |
SCHUBERT E, SANDER J, ESTER M,et al .DBSCAN revisited,revisited:why and how you should (still) use DBSCAN[J].ACM Transactions on Database Systems,2017,42(3):1-21.
|