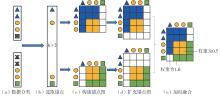
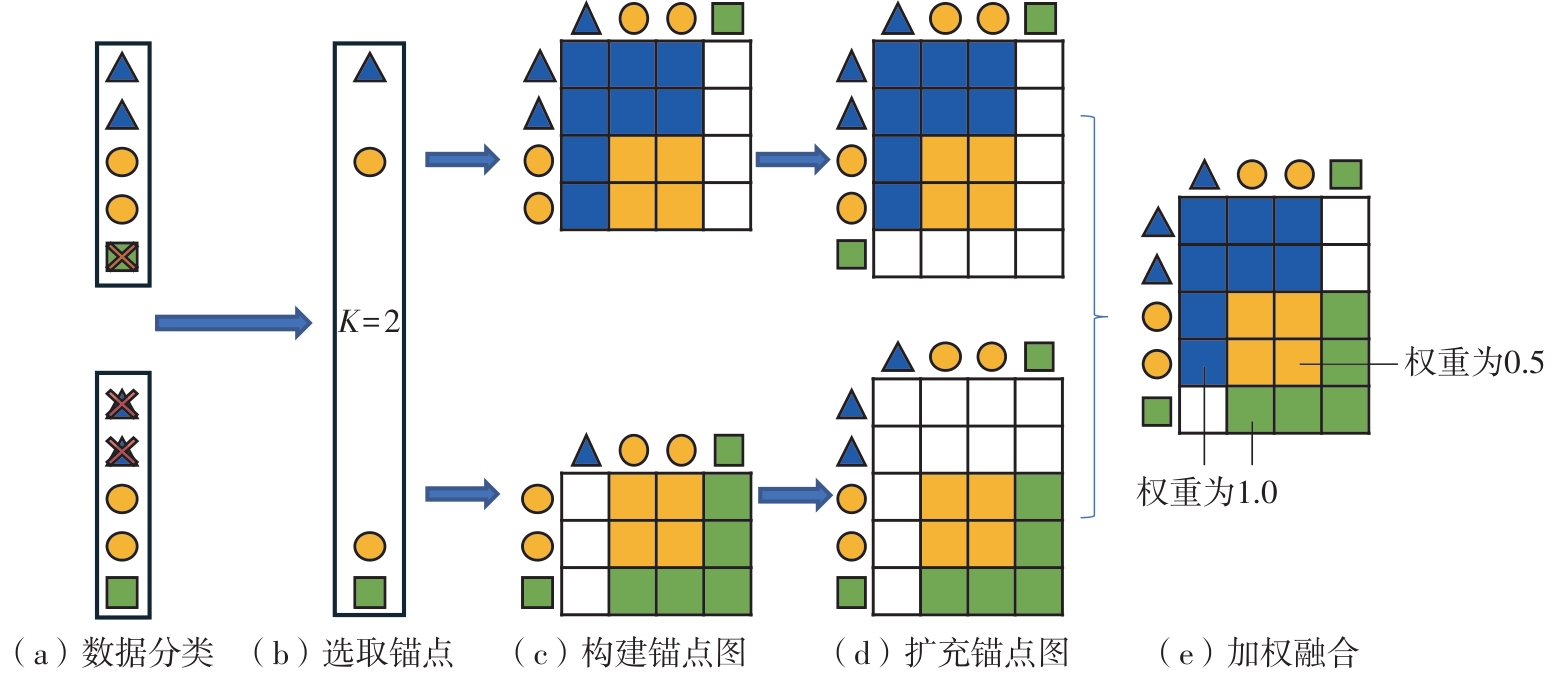
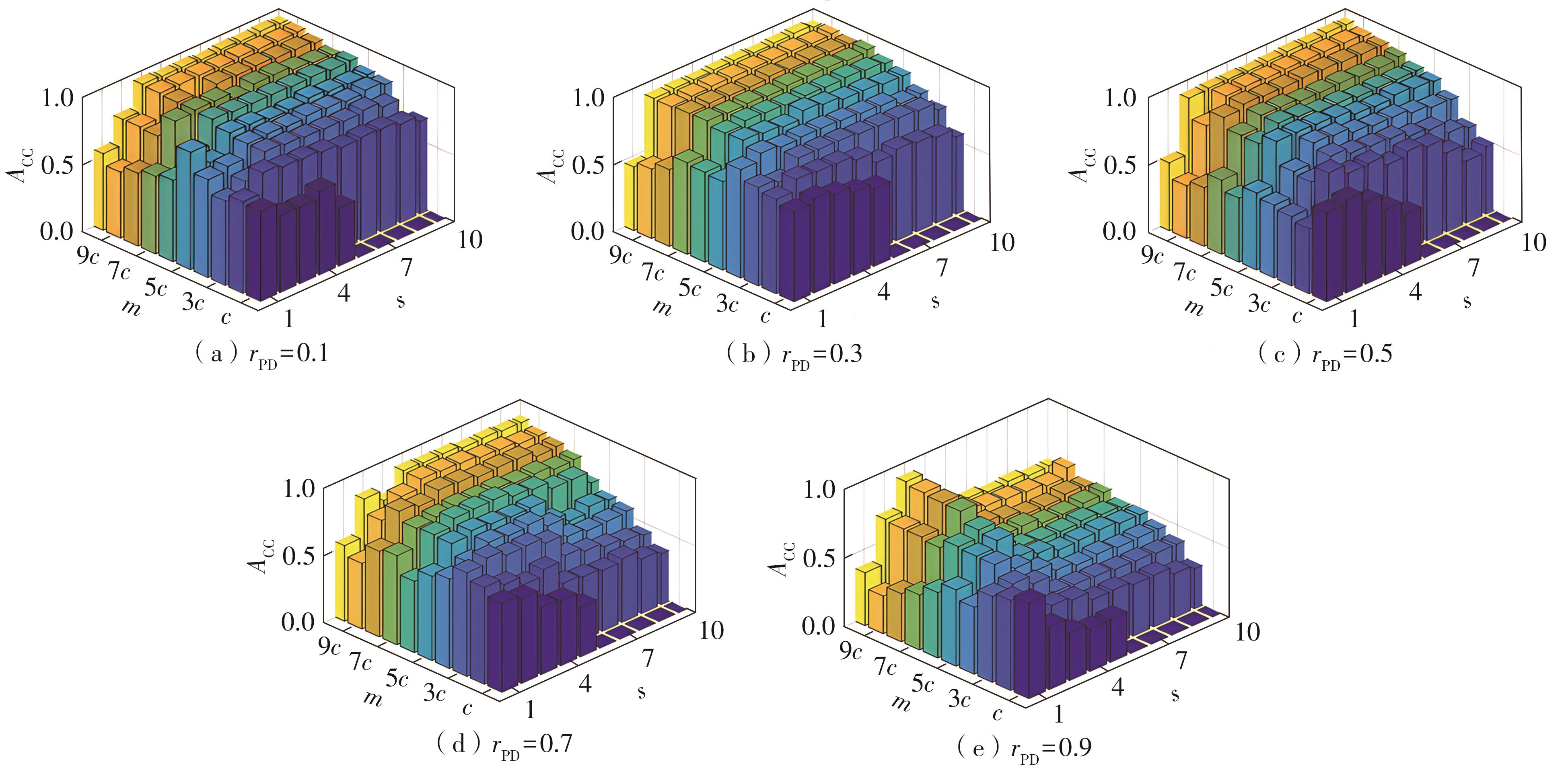
| [1] |
WANG Z, LI L, NING X,et al .Incomplete multi-view clustering via structure exploration and missing-view infe-rence[J].Information Fusion,2024,103:102123/1-12.
|
| [2] |
LI S Y, JIANG Y, ZHOU Z H .Partial multi-view clustering[C]∥ Proceedings of the 28th AAAI Conference on Artificial Intelligence.Québec City:AAAI,2014:1968-1974.
|
| [3] |
SHAO W, HE L, YU P S .Multiple incomplete views clustering via weighted nonnegative matrix factorization with regularization[C]∥ Proceedings of 2015 European Conference on Machine Learning and Knowledge Disco-very in Databases.Porto:Springer,2015:318-334.
|
| [4] |
WEN J, XU Y, LIU H .Incomplete multiview spectral clustering with adaptive graph learning[J].IEEE Tran-sactions on Cybernetics,2018,50(4):1418-1429.
|
| [5] |
WEN J, SUN H, FEI L,et al .Consensus guided incomplete multi-view spectral clustering[J].Neural Networks,2021,133:207-219.
|
| [6] |
GUO J, YE J .Anchors bring ease:an embarrassingly simple approach to partial multi-view clustering[C]∥ Proceedings of the 33rd AAAI Conference on Artificial Intelligence.Honolulu:AAAI,2019:118-125.
|
| [7] |
YU X, JIANG Y, CHAO G,et al .Deep contrastive multi-view subspace clustering with representation and cluster interactive learning[J].IEEE Transactions on Knowledge and Data Engineering,2024,37(1):188-199.
|
| [8] |
CHAO G, XU K, XIE X,et al .Global graph propagation with hierarchical information transfer for incomplete contrastive multi-view clustering[C]∥ Proceedings of the 39th AAAI Conference on Artificial Intelligence.Philadelphia:AAAI,2025:15713-15721.
|
| [9] |
SHEN Q, GUO Z, WANG H,et al .Reliable entropy-induced anchor learning for incomplete multi-view subspace clustering[J].IEEE Transactions on Circuits and Systems for Video Technology,2025,35(6):5293-5306.
|
| [10] |
WEI K, LI H, LIU Q,et al .Self-supervised,multi-view,semantics-aware anchor clustering[J].Electronics,2024,13(23):4782/1-18.
|
| [11] |
YU S, WANG S, ZHANG P,et al .DVSAI:diverse view-shared anchors based incomplete multi-view clustering[C]∥ Proceedings of the 38th AAAI Conference on Artificial Intelligence.Vancouver:AAAI,2024:16568-16577.
|
| [12] |
MI Y, CHEN H, YUAN Z,et al .Fast multi-view subspace clustering with balance anchors guidance[J].Pattern Recognition,2024,145:109895/1-11.
|
| [13] |
YANG B, WU J, ZHANG X,et al .Discrete correntropy-based multi-view anchor-graph clustering[J].Information Fusion,2024,103:102097/1-11.
|
| [14] |
XIA W, GAO Q, WANG Q,et al .Tensorized bipartite graph learning for multi-view clustering[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2022,45(4):5187-5202.
|
| [15] |
HUANG D, WANG C D, LAI J H .Fast multi-view clustering via ensembles:towards scalability,superio-rity,and simplicity[J].IEEE Transactions on Know-ledge and Data Engineering,2023,35(11):11388-11402.
|
| [16] |
赵兴旺,王淑君,刘晓琳,等 .基于二部图的联合谱嵌入多视图聚类算法[J].软件学报,2024,35(9):4408-4424.
|
|
ZHAO Xing-wang, WANG Shu-jun, LIU Xiao-lin,et al .Joint spectral embedding multi-view clustering algorithm based on bipartite graphs[J].Journal of Software,2024,35(9):4408-4424.
|
| [17] |
LIU W, HE J, CHANG S F .Large graph construction for scalable semi-supervised learning[C]∥ Proceedings of the 27th International Conference on Machine Learning.Haifa:Omni Press,2010:679-686.
|
| [18] |
WANG S, LIU X, LIU L,et al .Highly-efficient incomplete large-scale multi-view clustering with consensus bipartite graph[C]∥ Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition.New Orleans:IEEE,2022:9776-9785.
|
| [19] |
ZHANG R, HANG S, SUN Z,et al .Anchor-based fast spectral ensemble clustering[J].Information Fusion,2025,113:102587/1-13.
|
| [20] |
LI Z, TANG C, ZHENG X,et al .High-order correlation preserved incomplete multi-view subspace cluste-ring[J].IEEE Transactions on Image Processing,2022,31:2067-2080.
|
| [21] |
HU M, CHEN S .One-pass incomplete multi-view clustering[C]∥ Proceedings of the 33rd AAAI Confe-rence on Artificial Intelligence.Honolulu:AAAI,2019:3838-3845.
|
| [22] |
WEN J, ZHANG Z, ZHANG Z,et al .Generalized incomplete multiview clustering with flexible locality structure diffusion[J].IEEE Transactions on Cybernetics,2020,51(1):101-114.
|
| [23] |
GREENE D, CUNNINGHAM P .A matrix factorization approach for integrating multiple data views[C]∥ Proceedings of 2009 European Conference on Machine Learning and Knowledge Discovery in Databases.Bled:Springer,2009:423-438.
|
| [24] |
JAIN A K, DUIN R P W, MAO J .Statistical pattern recognition:a review[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22(1):4-37.
|
| [25] |
XIA R, PAN Y, DU L,et al .Robust multi-view spectral clustering via low-rank and sparse decomposition[C]∥ Proceedings of the 28th AAAI Conference on Artificial Intelligence.Palo Alto:AAAI,2014:2149-2155.
|
| [26] |
LI F-F, ANDREETO M, RANZATO M,et al .Caltech 101(Version 1.0)[DB/OL].(2022-04-06)[2025-05-10]..
|
| [27] |
刘小兰,叶泽慧 .基于StarGAN和子空间学习的缺失多视图聚类[J].华南理工大学学报(自然科学版),2020,48(11):87-98.
|
|
LIU Xiaolan, YE Zehui .Partial multi-view clustering based on StarGAN and subspace learning[J].Journal of South China University of Technology (Natural Science Edition),2020,48(11):87-98.
|
| [28] |
ZHU J, WAN M, YANG G,et al .INCOMPLETE multi-view clustering based on low-rank adaptive graph learning[J].Knowledge-Based Systems,2024,305:112562/1-13.
|