华南理工大学学报(自然科学版) ›› 2024, Vol. 52 ›› Issue (6): 1-11.doi: 10.12141/j.issn.1000-565X.230262
所属专题: 2024年绿色智慧交通
基于记忆泊车场景的视觉SLAM算法
胡习之( ), 崔博非(), 王琴, 刘鸿
), 崔博非(), 王琴, 刘鸿
- 华南理工大学 机械与汽车工程学院,广东 广州 510640
Visual SLAM Algorithm Based on Memory Parking Scene
HU Xizhi(), CUI Bofei(), WANG Qin, LIU Hong
- School of Mechanical and Automotive Engineering,South China University of Technology,Guangzhou 510640,Guangdong,China
摘要:
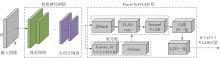
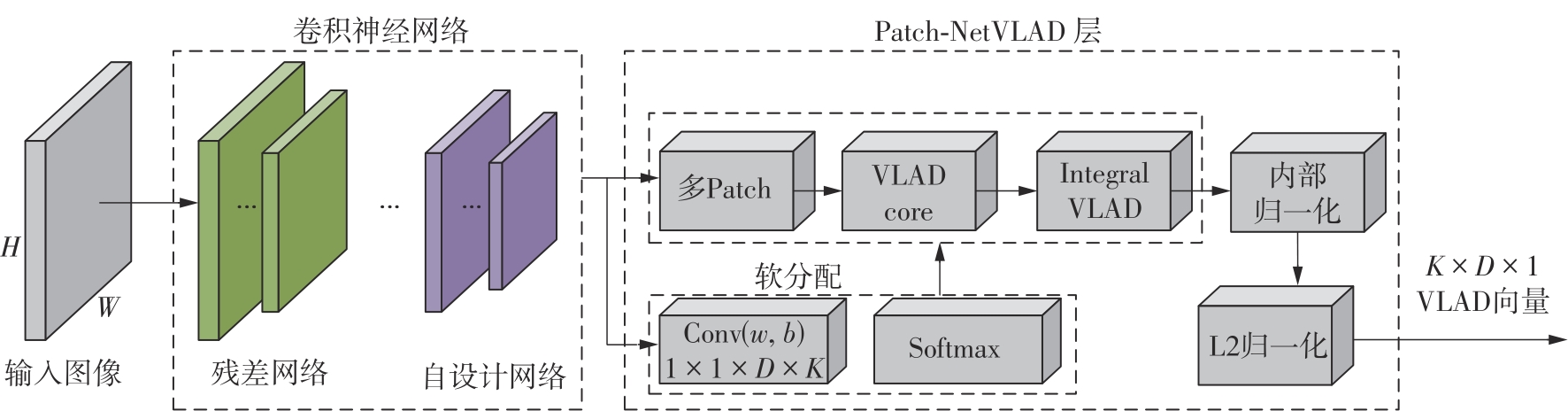
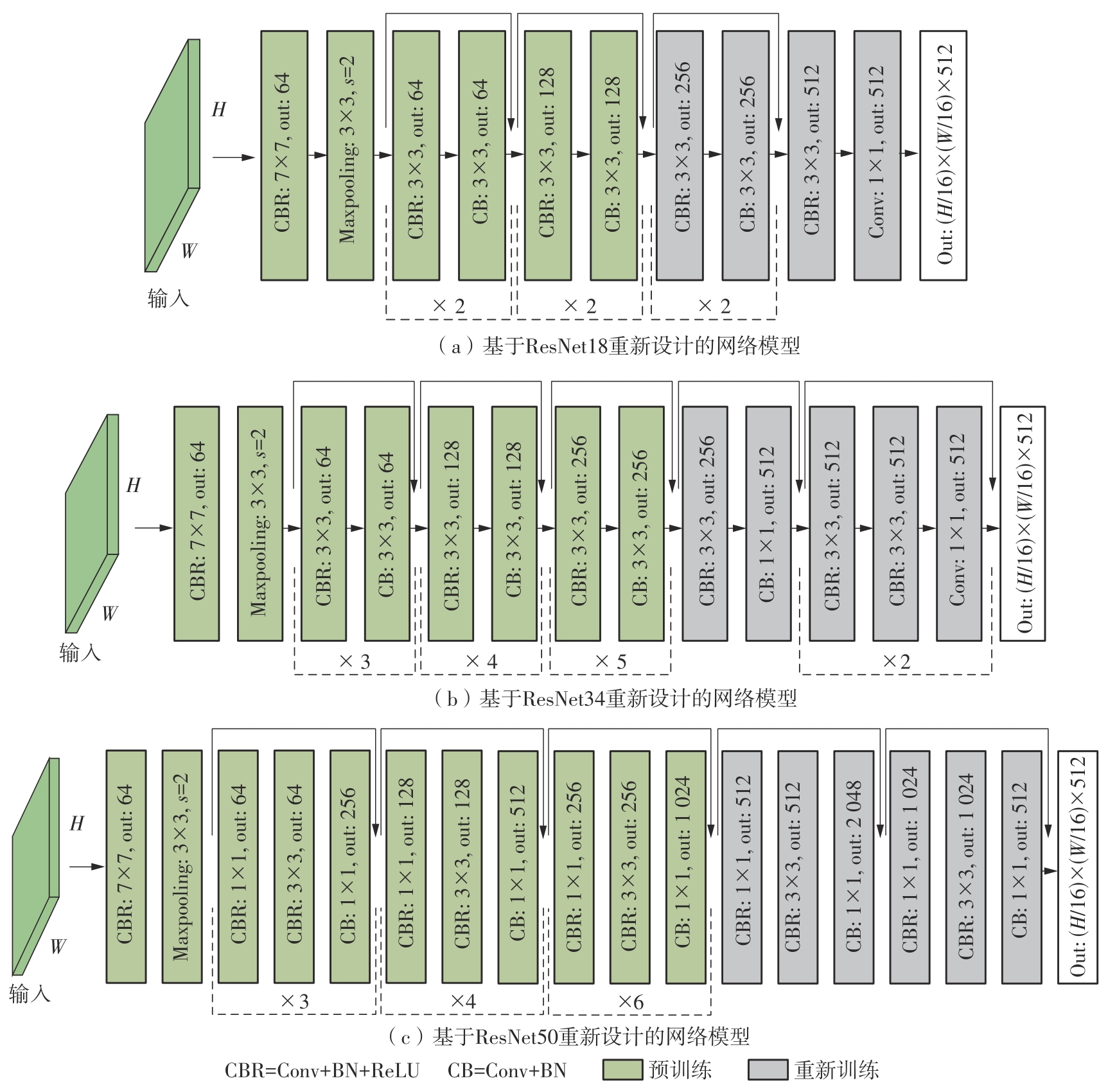
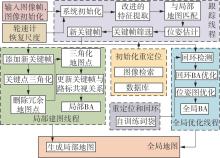
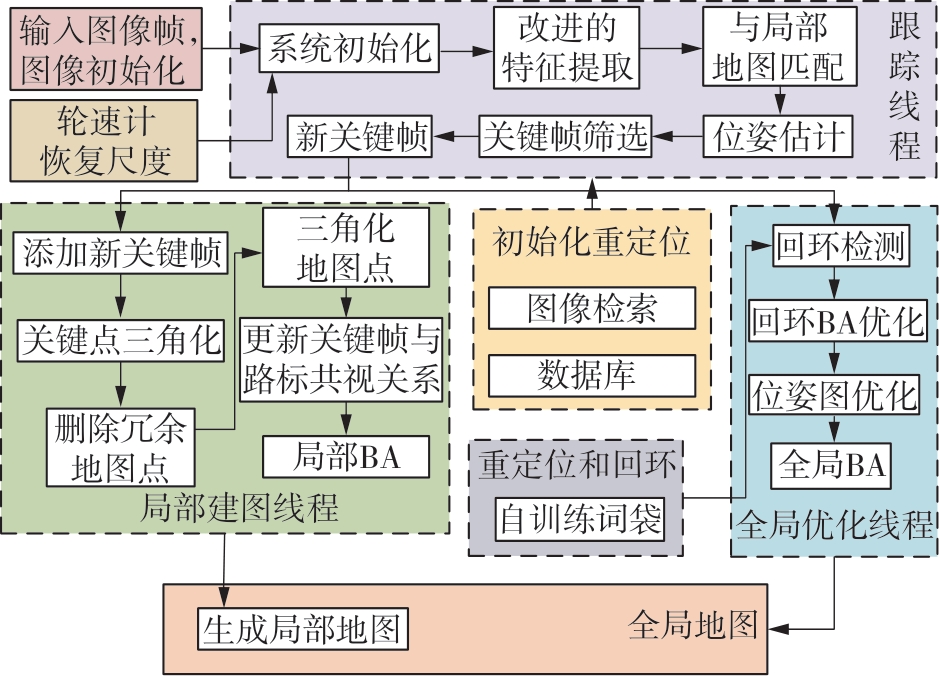
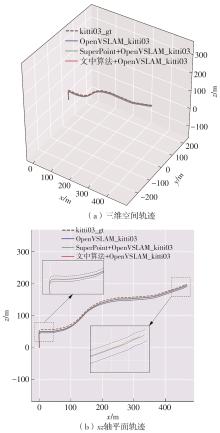
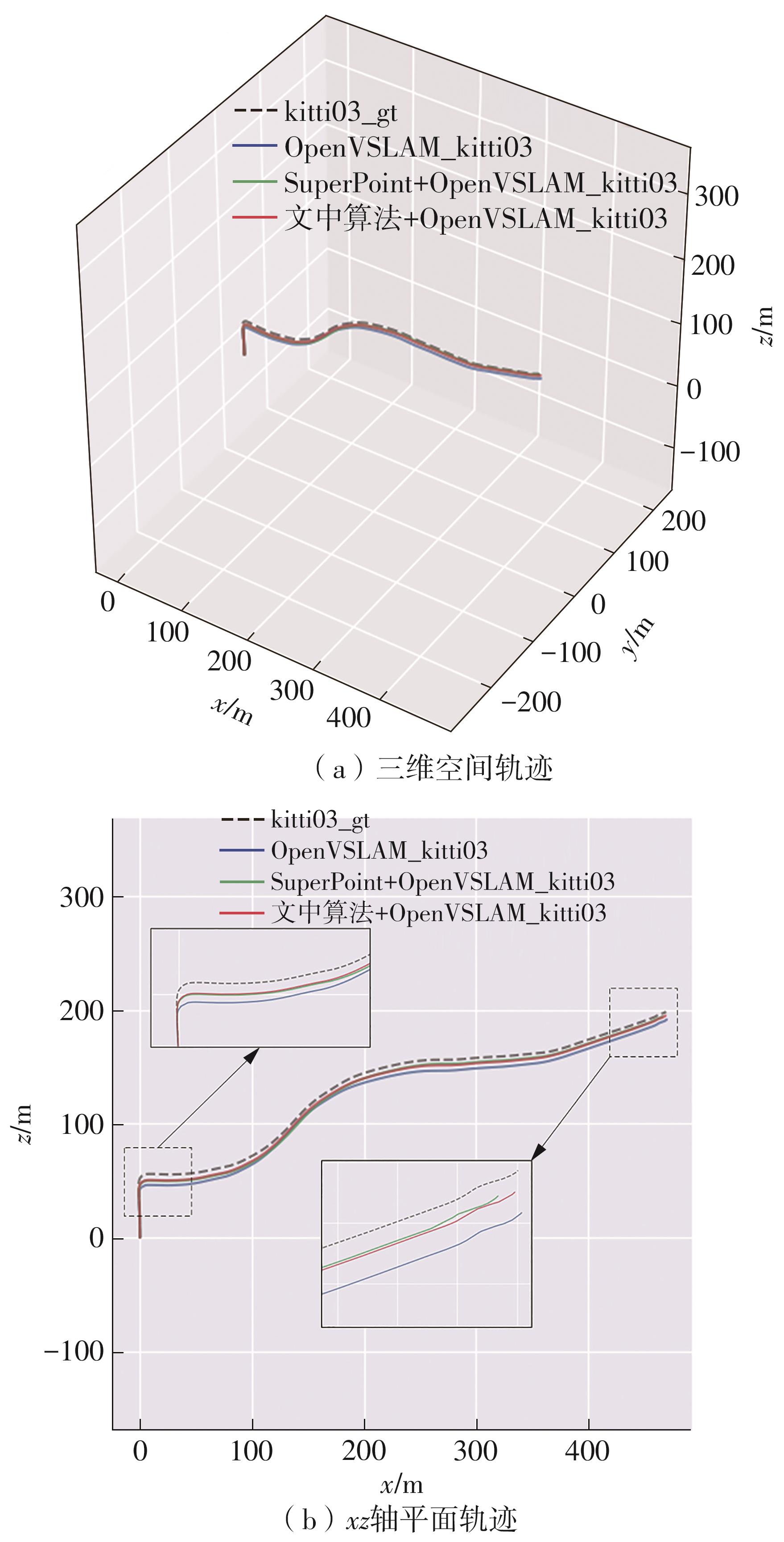
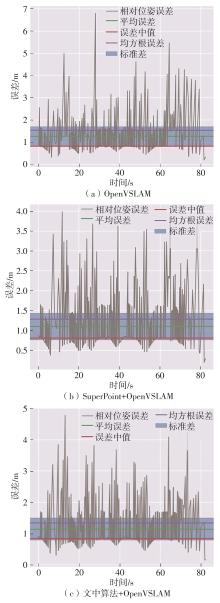
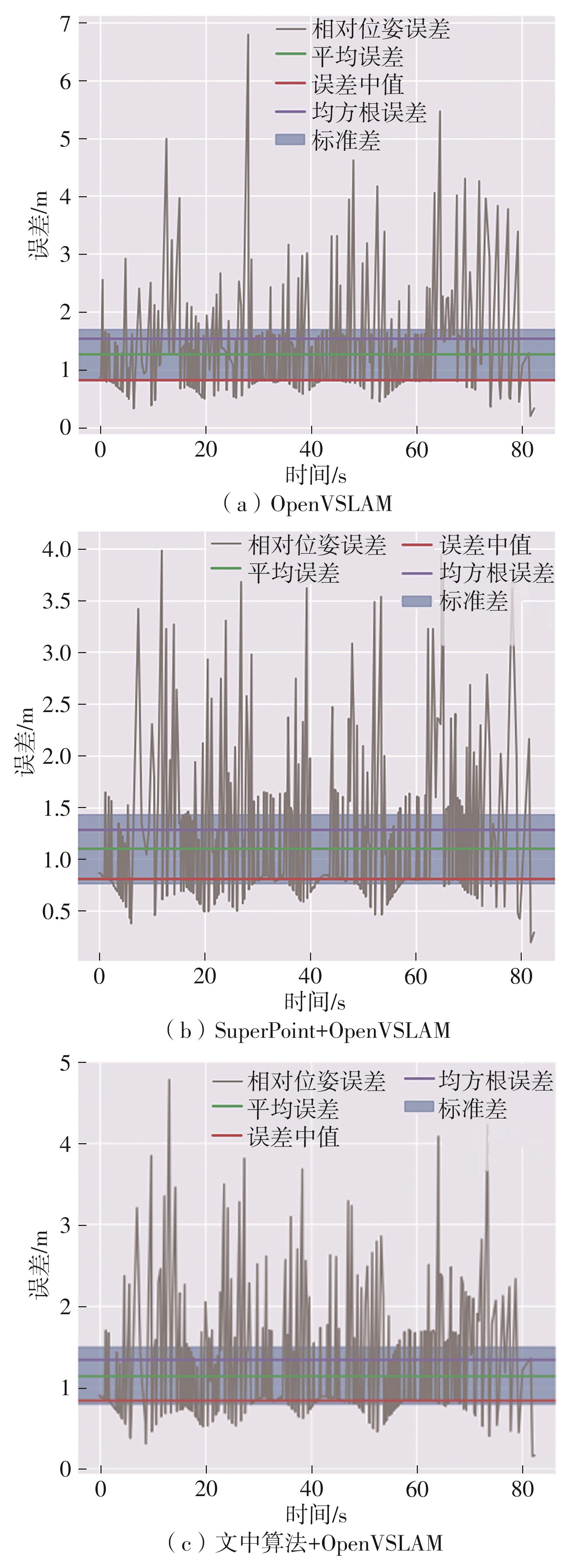
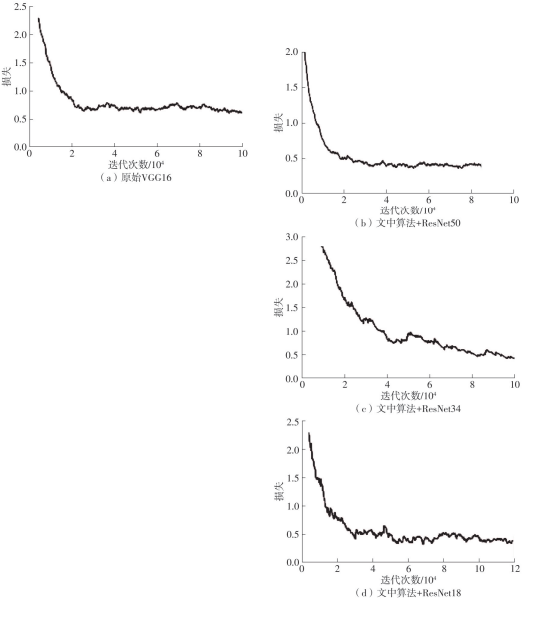
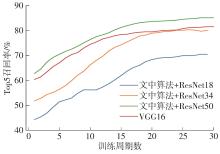
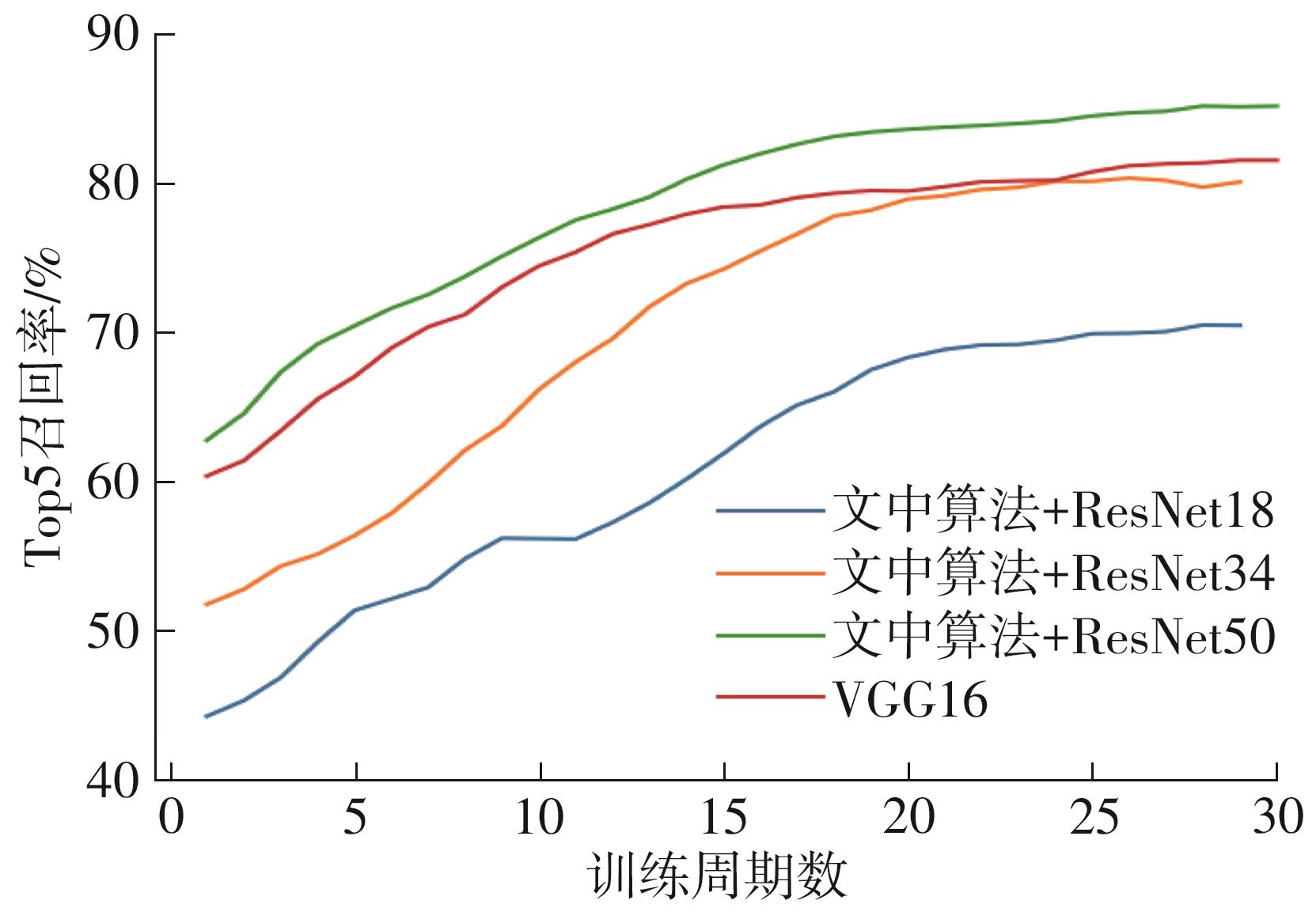
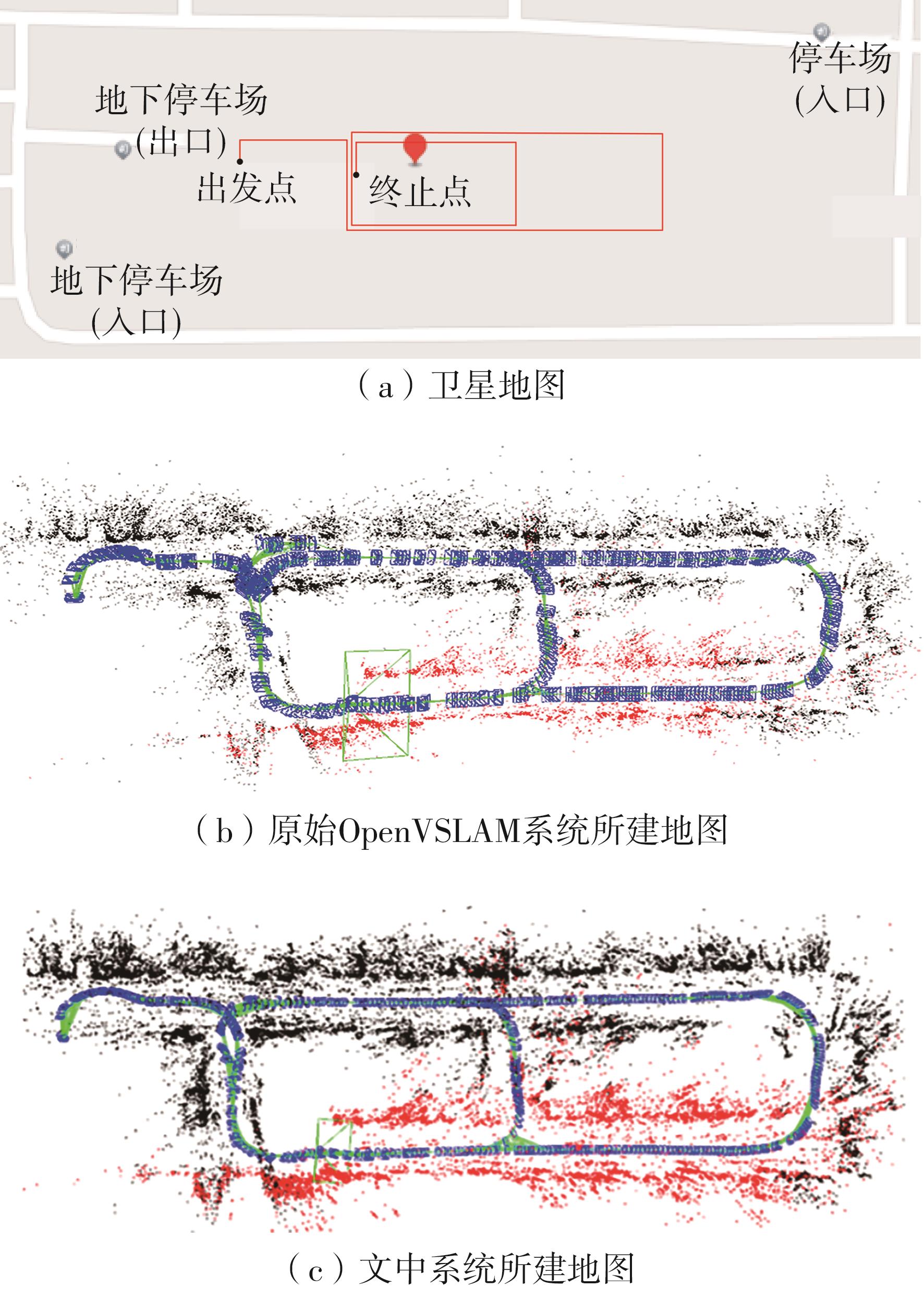
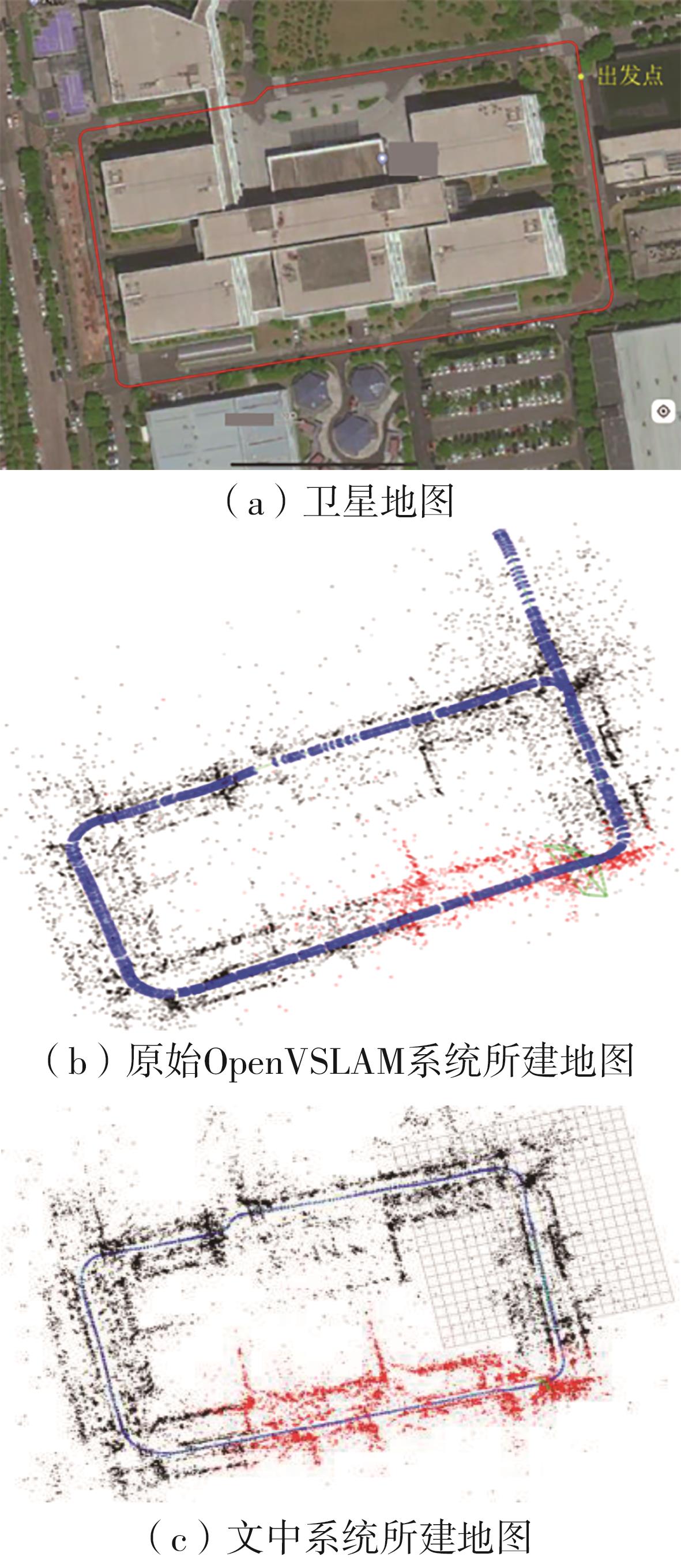
随着自动驾驶技术的发展,视觉同步建图与定位(SLAM)技术受到越来越多的关注。在记忆泊车场景中,需要对停车场场景建立先验地图,待汽车再次驶入相同的停车场时,使用视觉SLAM进行场景建图与定位。为使SLAM所建地图的鲁棒性更好、精度和效率更高,文中首先使用轻量化的深度学习算法改善传统特征提取算法在不同场景下鲁棒性较差的不足,用深度可分离卷积代替普通卷积结构,从而大大提升了特征提取效率;接着基于ResNet网络改进Patch-NetVLAD算法,并在MSLS数据集上对改进的残差网络和原始VGG网络进行重新训练,使用图像检索进行粗定位,挑选出候选图像帧,再通过精定位求解相机位姿,完成全局初始化的重定位;在此基础上,使用改进后的词袋算法重新训练不同停车场场景下的图像,将所有算法移植到OpenVSLAM架构中完成实际场景的建图与定位。实验结果表明,文中设计的视觉SLAM系统能够完成地上停车场、地下停车场以及室外半封闭园区道路等多场景的建图,平均纵向定位误差为8.42 cm,平均横向定位误差为8.30 cm,均达到工程要求。
中图分类号: