华南理工大学学报(自然科学版) ›› 2023, Vol. 51 ›› Issue (5): 104-113.doi: 10.12141/j.issn.1000-565X.220623
所属专题: 2023年电子、通信与自动控制
基于FPGA并行加速的脉冲神经网络在线学习硬件结构的设计与实现
刘怡俊1 曹宇2 叶武剑1 林子琦2
- 1.广东工业大学 集成电路学院,广东 广州 510006
2.广东工业大学 信息工程学院,广东 广州 510006
Design and Implementation of Hardware Structure for Online Learning of Spiking Neural Networks Based on FPGA Parallel Acceleration
LIU Yijun1 CAO Yu2 YE Wujian1 LIN Ziqi2
- 1.School of Integrated Circuits, Guangdong University of Technology, Guangzhou 510006, Guangdong, China
2.School of Information Engineering, Guangdong University of Technology, Guangzhou 510006, Guangdong, China
摘要:
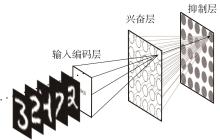
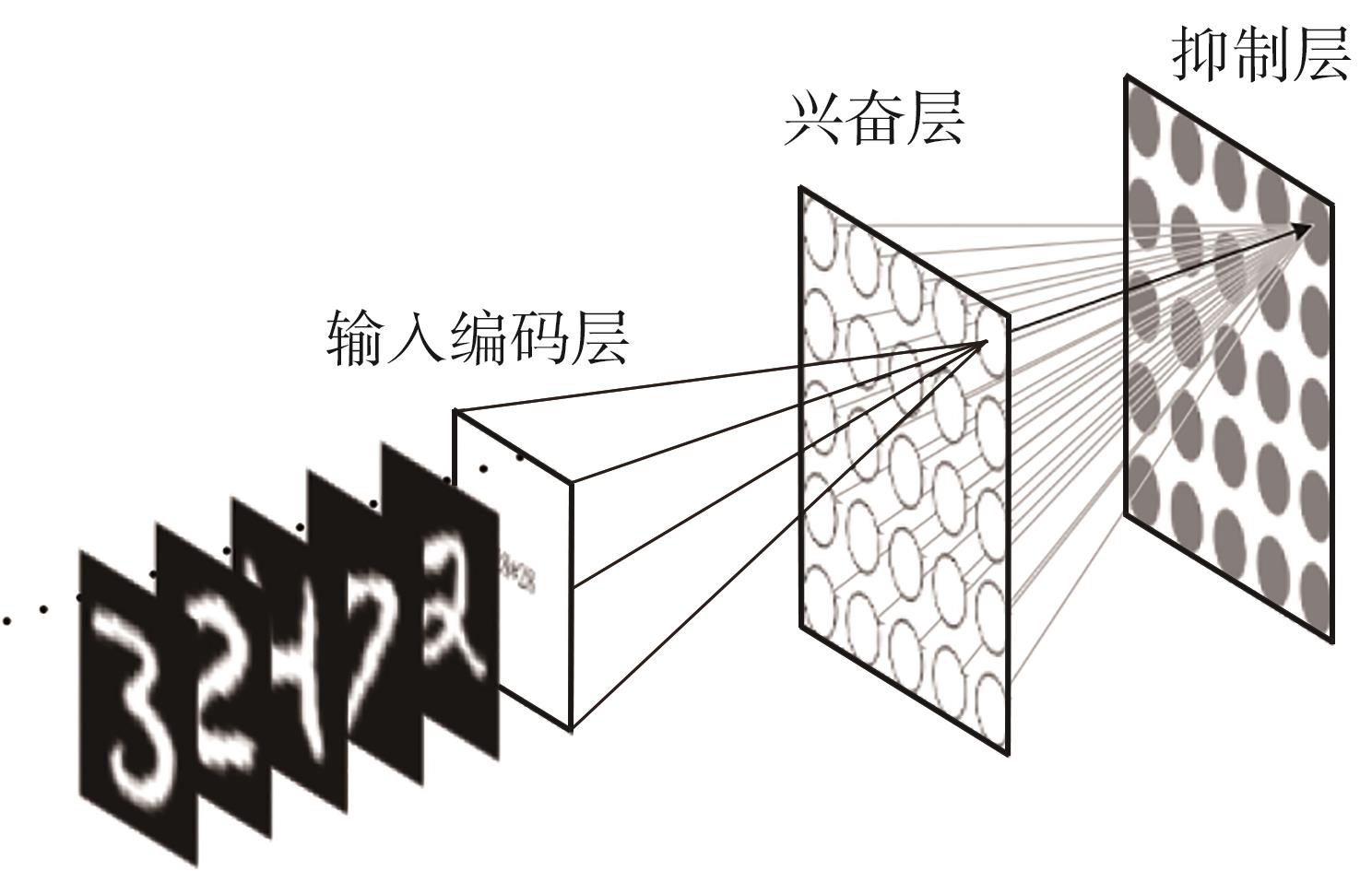
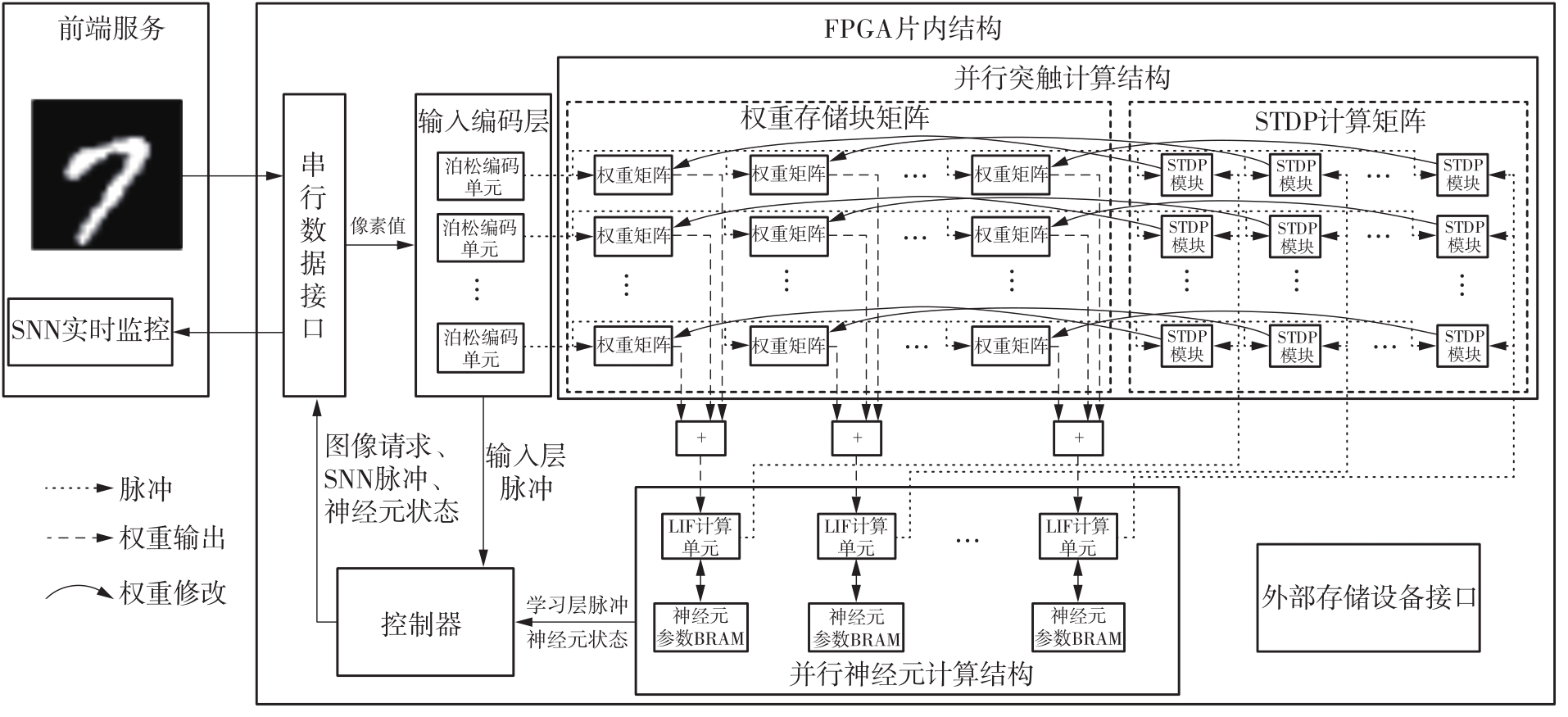
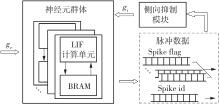
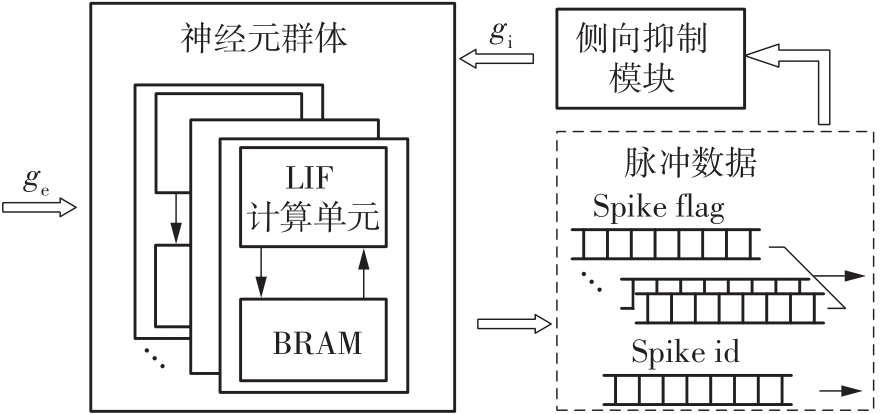
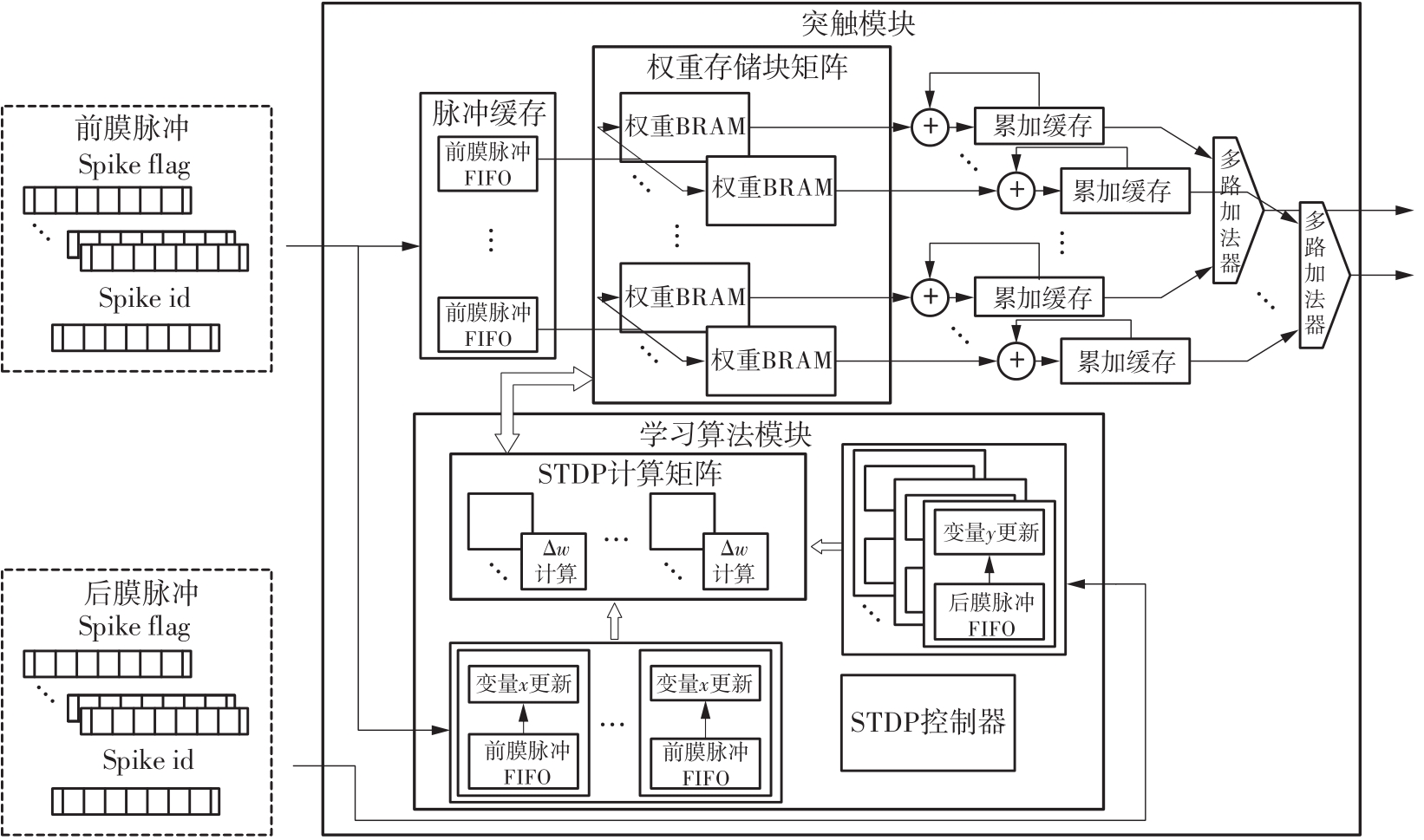
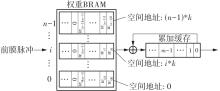
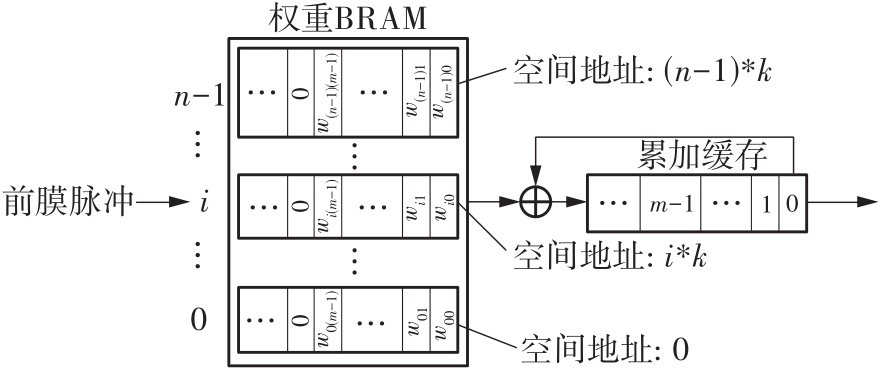
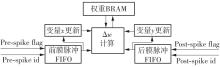
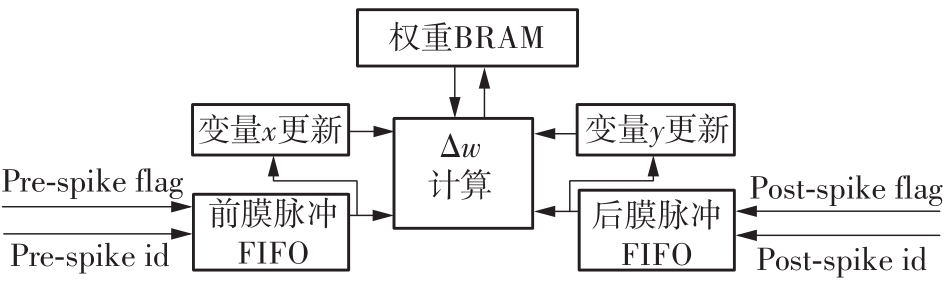
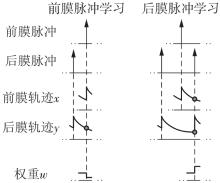
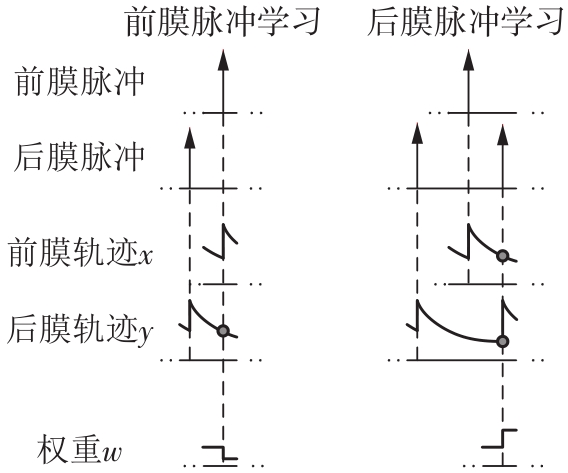
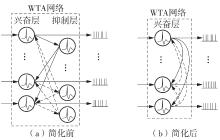
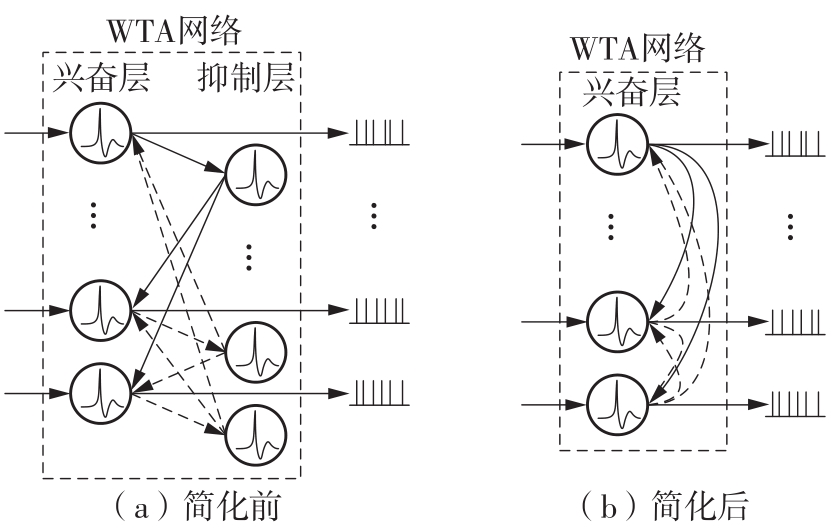
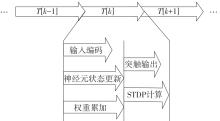
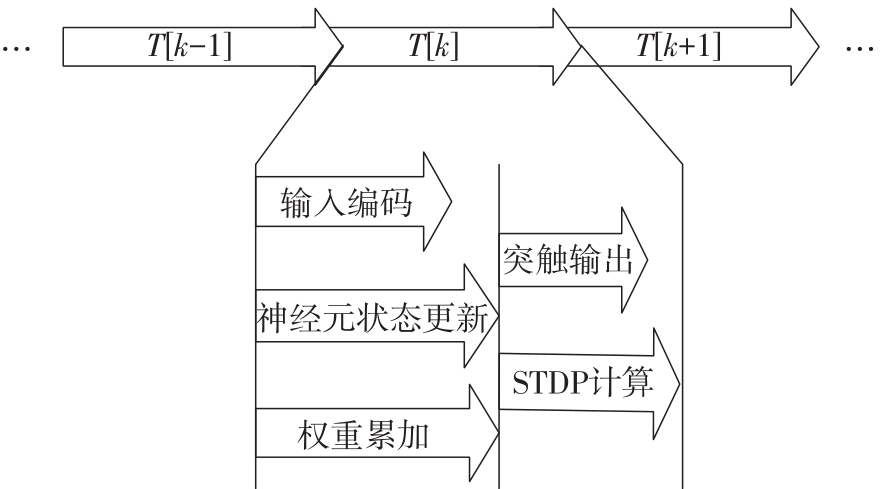
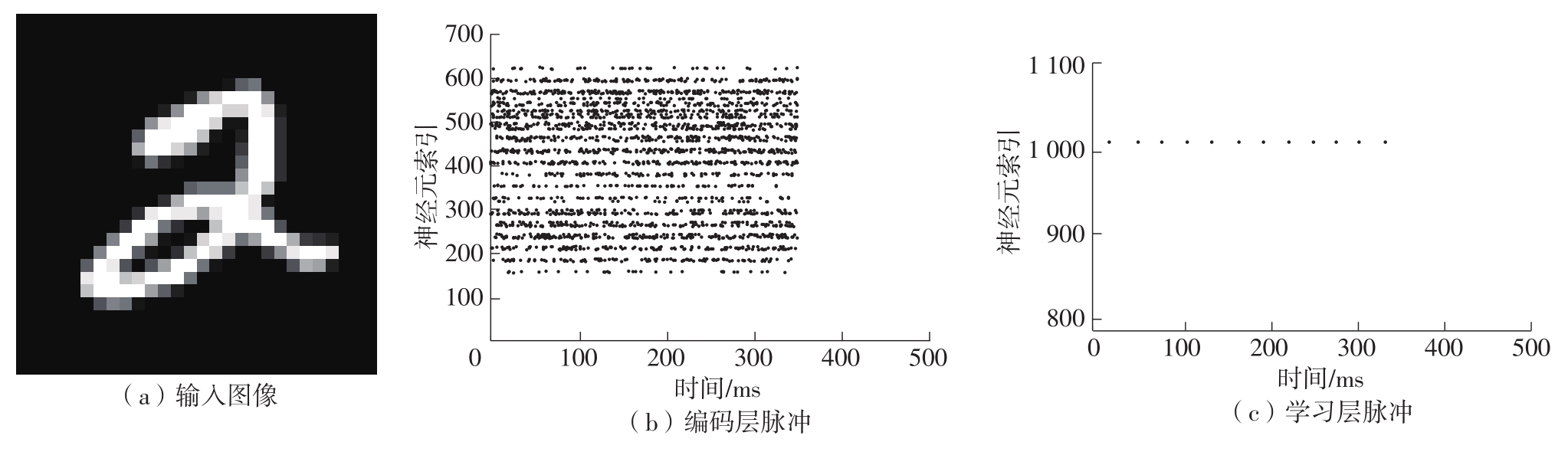
当前,基于数字电路的脉冲神经网络硬件设计,在学习功能方面的突触并行性不高,导致硬件整体延时较大,在一定程度上限制了脉冲神经网络模型在线学习的速度。针对上述问题,文中提出了一种基于FPGA并行加速的高效脉冲神经网络在线学习硬件结构,通过神经元和突触的双并行设计对模型的训练与推理过程进行加速。首先,设计具有并行脉冲传递功能和并行脉冲时间依赖可塑性学习功能的突触结构;然后,搭建输入编码层和赢家通吃结构的学习层,并优化赢家通吃网络的侧向抑制的实现,形成规模为784~400的脉冲神经网络模型。实验结果表明:在MNIST数据集上,使用该硬件结构的脉冲神经网络模型训练一幅图像需要的时间为1.61 ms、能耗约为3.18 mJ,推理一幅图像需要的时间为1.19 ms、能耗约为2.37 mJ,识别MNIST测试集样本的准确率可达87.51%;在文中设计的硬件框架下,突触并行结构能使训练速度提升38%以上,硬件能耗降低约24.1%,有助于促进边缘智能计算设备及技术的发展。
中图分类号: