华南理工大学学报(自然科学版) ›› 2025, Vol. 53 ›› Issue (3): 50-56.doi: 10.12141/j.issn.1000-565X.240159
基于文本-视觉和信息熵最小化的对比学习模型
蔡晓东1( ), 董丽芳1, 黄业洋1, 周丽2
), 董丽芳1, 黄业洋1, 周丽2
- 1.桂林电子科技大学 信息与通信学院,广西 桂林 541004
2.南宁西岸枫谷商务数据有限公司,广西 南宁 530008
Contrastive Learning Model Based on Text-Visual and Information Entropy Minimization
CAI Xiaodong1(), DONG Lifang1, HUANG Yeyang1, ZHOU Li2
- 1.School of Information and Communication,Guilin University of Electronic Technology,Guilin 541004,Guangxi,China
2.Nanning West Bund Fenggu Business Data Co. ,Ltd. ,Nanning 530008,Guangxi,China
摘要:
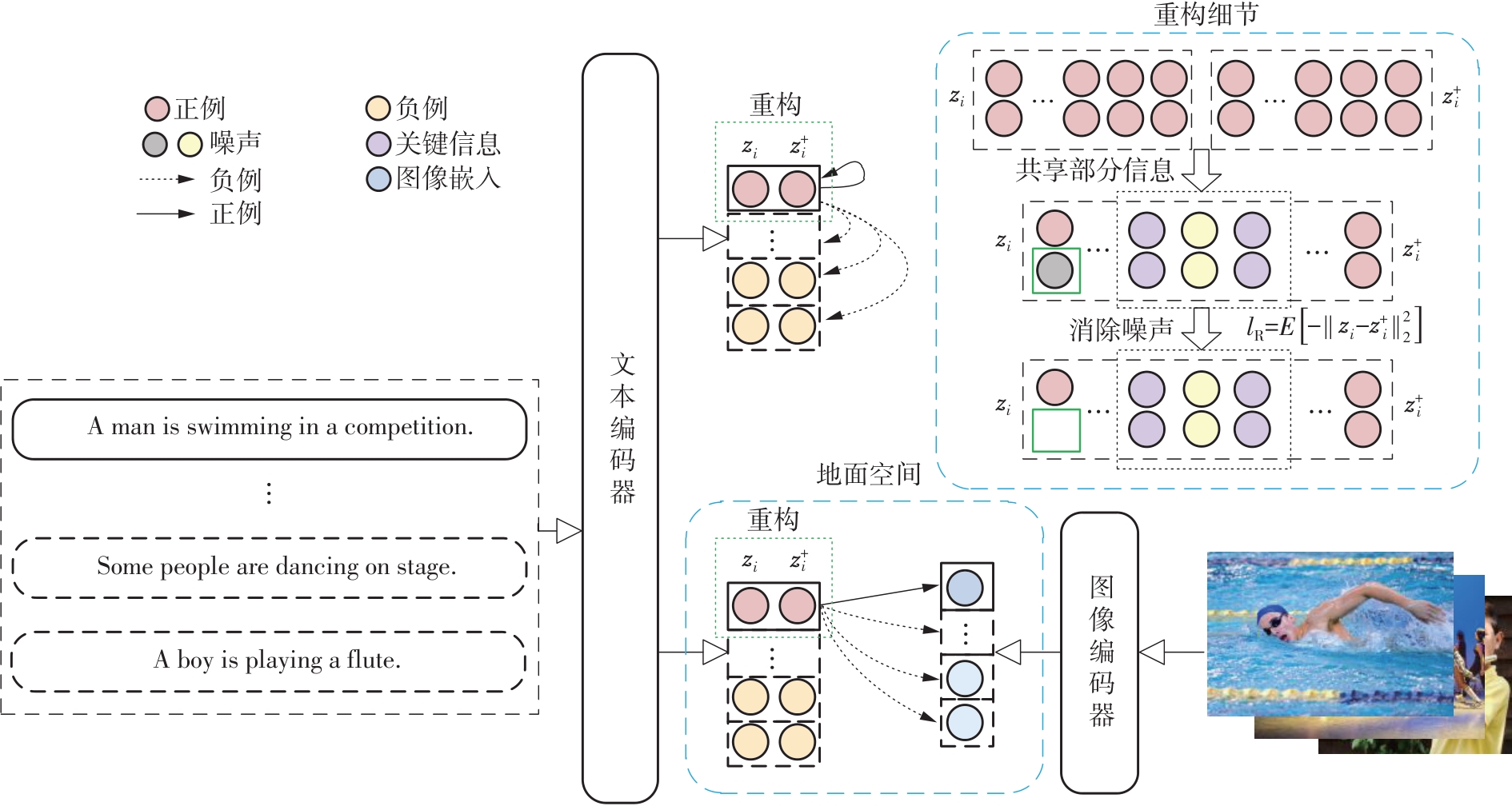
当前的无监督对比学习方法主要依赖纯文本信息来构建句子嵌入,在全面理解句子所表达的深层含义时存在局限性。同时,传统的对比学习方法过于注重最大化文本正实例之间的互信息,忽视了句子嵌入中潜在的噪声干扰。为了既能保留文本中的有用信息,又能有效地剔除文本嵌入中的噪声干扰,该文提出了一种基于文本-视觉和信息熵最小化的对比学习模型。首先,将文本与对应的视觉信息在对比学习的框架下进行深度融合,共同映射到一个统一的地面空间,并确保它们的表示在该空间中保持一致,从而克服了仅依赖纯文本信息进行句子嵌入学习的限制,使得对比学习过程更加全面且精确;然后,遵循信息最小化原则,在最大化文本正实例间互信息的同时,基于信息熵最小化对文本正实例进行重构。在标准语义文本相似度(STS)任务上的实验结果表明,所提出的模型在Spearman相关系数评价指标上取得了显著提升,相较于现有先进方法具有显著的优势,同时也证明了该模型的有效性。
中图分类号: