
Journal of South China University of Technology(Natural Science) >
CODS: An Audio-Text Aligned Dataset for Cantonese Opera Vocal Synthesis
Received date: 2025-05-06
Online published: 2025-05-19
Supported by
the National Natural Science Foundation of China(62476096)
As one of the traditional Chinese arts, Chinese opera culture has unique musical expressiveness. Cantonese opera, as one of the main Chinese opera genres and an important carrier of Lingnan culture, has been indexed in the World Intangible Cultural Heritage List. In recent years, generative artificial intelligence technology has demonstrated its powerful capabilities in the field of content creation. For example, singing synthesis techno-logy can synthesize natural singing based on specified music scores. This provides a new idea for the digital protection and innovation of Cantonese opera. However, the collection and organization of opera data faces problems such as poor audio quality and complex dialect annotation, resulting in an extreme shortage of high-quality opera data sets. Based on this, this paper applied the singing synthesis technology in the field of pop music to the field of Cantonese opera vocal synthesis, and proposed the first Cantonese opera vocal synthesis dataset with phoneme-level annotation and audio-text alignment. Firstly, this paper constructed the CODS dataset through a systematic process. This dataset was derived from 29 original works by four famous performers with a total length of 3.81 hours, which provides important support for the research and digitization of Cantonese opera. Using this dataset, this paper conducted experiments with a deep learning-based method for Cantonese opera voice synthesis, realizing controllable generation in terms of lyrics, timbre, and melody. Finally, this paper established a comprehensive evaluation framework for Cantonese opera synthesis. Both objective and subjective evaluations reached a satisfactory level within the domain, further validating the usability of the proposed dataset. The CODS dataset constructed in this paper successfully filled the gap in artificial intelligence in the field of Cantonese opera vocal synthesis, and strongly promoted the inheritance and innovation of this traditional art.
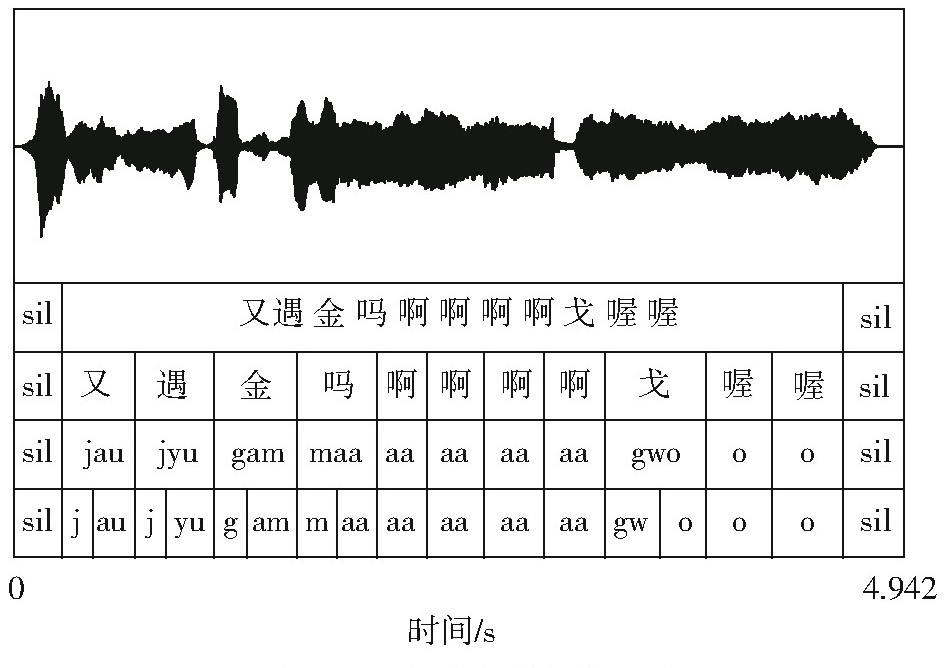
LI Yue , HUANG Yihan , PENG Zhengwei , XIE Jixuan , DU Yuye . CODS: An Audio-Text Aligned Dataset for Cantonese Opera Vocal Synthesis[J]. Journal of South China University of Technology(Natural Science), 2025 , 53(9) : 1 -10 . DOI: 10.12141/j.issn.1000-565X.250134
| [1] | XU J .The language features and cultural implication of Cantonese opera librettos[J].Frontiers in Art Research,2021,3(2):20-29. |
| [2] | 单韵鸣,杜金凤 .地方非物质文化遗产的传播困境与现代化发展模式的探索:以粤剧为例[J].学术研究,2024(8):54-60. |
| SHAN Yunming, DU Jinfeng .The promotion issues and the modemization model of the regional intangible cultural heritage:a case study of cantonese opem[J].Academic Research,2024(8):54-60. | |
| [3] | ZHANG L, LI R, WANG S,et al .M4Singer:a multi-style,multi-singer and musical score provided mandarin singing corpus[C]∥ Proceedings of Advances in Neural Information Processing Systems.New Orleans:MIT Press,2022:6914-6926. |
| [4] | ZHANG Z, ZHENG Y, LI X,et al .WeSinger 2:fully parallel singing voice synthesis via multi-singer conditional adversarial training[C]∥ Proceedings of 2023 IEEE International Conference on Acoustics,Speech and Signal Processing.Rhodes Island:IEEE,2023:1-5. |
| [5] | WANG C, ZENG C, HE X .Xiaoicesing 2:a high-fidelity singing voice synthesizer based on generative adversarial network[EB/OL].(2022-10-26)[2025-05-05].. |
| [6] | LIU X, ZHANG W, ZHENG Z,et al .FGP-GAN:fine-grained perception integrated generative adversarial network for expressive mandarin singing voice synthesis [J].IEEE Transactions on Consumer Electronics,2024,70(3):6054-6063. |
| [7] | CUI J, GU Y, WENG C,et al .Sifisinger:a high-fidelity end-to-end singing voice synthesizer based on source-filter model[C]∥ Proceedings of 2024 IEEE International Conference on Acoustics,Speech and Signal Processing.Seoul:IEEE,2024:11126-11130. |
| [8] | LIU J, LI C, REN Y,et al .DiffSinger:singing voice synthesis via shallow diffusion mechanism[C]∥ Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence.Vancouver:AAAI,2022:11020-11028. |
| [9] | REPETTO R C, SERRA X .A collection of music scores for corpus based jingju singing research[C]∥ Proceedings of the 18th International Society for Music Information Retrieval Conference.Suzhou:ISMIR,2017:46-52. |
| [10] | ZHENG M, BAI P, SHI X,et al .FT-GAN:fine-grained tune modeling for Chinese opera synthesis[C]∥ Proceedings of the Thirty-Eighth AAAI Confe-rence on Artificial Intelligence.Vancouver:AAAI,2024:19697-19705. |
| [11] | BO?I? M, HORVAT M .A survey of deep learning audio generation methods[EB/OL].(2024-05-31)[2025-05-05].. |
| [12] | KIM J, KONG J,SON J .Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech[C]∥ Proceedings of the 38th International Conference on Machine Learning.Vienna:ML Research Press,2021:5530-5540. |
| [13] | ZHANG Y, CONG J, XUE H,et al .VISinger:variational inference with adversarial learning for end-to-end singing voice synthesis[C]∥ Proceedings of 2022 IEEE International Conference on Acoustics,Speech and Signal Processing.Singapore:IEEE,2022:7237-7241. |
| [14] | ZHANG Y, XUE H, LI H,et al .VISinger 2:high-fidelity end-to-end singing voice synthesis enhanced by digital signal processing synthesizer[EB/OL].(2022-11-05)[2025-05-05].. |
| [15] | HWANG J S, LEE S H, LEE S W .HiddenSinger:high-quality singing voice synthesis via neural audio codec and latent diffusion models[J].Neural Networks,2025,181:106762/1-10. |
| [16] | ZHANG Y, HUANG R, LI R,et al .StyleSinger:style transfer for out-of-domain singing voice synthesis[C]∥ Proceedings of the Thirty-Eighth AAAI Confe-rence on Artificial Intelligence.Vancouver:AAAI,2024:19597-19605. |
| [17] | BLACK D A, LI M, TIAN M .Automatic identification of emotional cues in Chinese opera singing[C]∥ Proceedings of the 13th International Conference on Music Perception and Cognition.Seoul:[s.n.],2014:250-255. |
| [18] | ISLAM R, XU M, FAN Y .Chinese traditional opera database for music genre recognition[C]∥ Procee-dings of the 18th Oriental COCOSDA/CASLRE.Shanghai:IEEE,2015:38-41. |
| [19] | LI Y, PENG Z, XU D,et al .RoleNet:a multiple features fusion network for role classification in Canto-nese opera[J].Multimedia Tools and Applications,(2025-01-28).. |
| [20] | CHEN Q, ZHAO W, WANG Q,et al .The sustai-nable development of intangible cultural heritage with AI:Cantonese opera singing genre classification based on CoGCNet model in China[J].Sustainability,2022,14:2923/1-20. |
| [21] | LI Q, HU B .Joint time and frequency transformer for Chinese opera classification[C]∥ Proceedings of Interspeech 2023.Dublin:ISCA,2023:3919-3923. |
| [22] | WU Y, LI S, YU C,et al .Peking Opera synthesis via duration informed attention network[EB/OL].(2020-08-07)[2025-05-05].. |
| [23] | BAI P, ZHOU Y, ZHENG M,et al .Improving Chinese pop song and Hokkien Gezi Opera singing voice synthesis by enhancing local modeling[C]∥ Procee-dings of the 2023 Conference on Empirical Methods in Natural Language Processing.Singapore:ACL,2023:3302-3312. |
| [24] | ZHOU X, SUN W, SHI X .A high-quality melody-aware Peking Opera synthesizer using data augmentation[C]∥ Proceedings of 2023 IEEE International Confe-rence on Multimedia and Expo.Brisbane:IEEE,2023:1092-1097. |
| [25] | REN Y, HU C, TAN X,et al .FastSpeech 2:fast and high-quality end-to-end text to speech[EB/OL].(2020-06-08)[2025-05-05].. |
| [26] | MCAULIFFE M, SOCOLOF M, MIHUC S,et al .Montreal forced aligner:trainable text-speech alignment using kaldi[C]∥ Proceedings of Interspeech 2017.Stockholm:ISCA,2017:498-502. |
| [27] | SOLOVYEY R, STEMPKOVSKIY A, HABRUSEVA T .Benchmarks and leaderboards for sound demixing tasks[EB/OL].(2024-05-07)[2025-05-05].. |
| [28] | BOERSMA P .Praat:doing phonetics by computer [CP/OL].(2011-05-01)[2025-05-05].. |
| [29] | DAI S, WU Y, CHEN S,et al .SingStyle111:a multilingual singing dataset with style transfer[C]∥ Proceedings of the 24th International Society for Music Information Retrieval Conference.Milan:ISMIR,2023:765-773. |
| [30] | JADOUL Y, THOMPSON B, DE BOER B .Introdu-cing Parselmouth:a Python interface to Praat[J].Journal of Phonetics,2018,71:1-15. |
| [31] | LI R, ZHANG Y, WANG Y,et al .Robust singing voice transcription serves synthesis[EB/OL].(2024-05-16)[2025-05-05].. |
| [32] | 关子尹,邓伟生,赵子明 .粤语审音配词字库 [DB/OL].(2003-01-12)[2025-05-05].. |
| [33] | KONG J, KIM J,BAE J .HiFi-GAN:generative adversarial networks for efficient and high fidelity speech synthesis[C]∥ Advances in Neural Information Processing Systems 33:34th Conference on Neural Information Processing Systems.San Diego:Neural Information Processing Systems Foundation,Inc.,2020:17022-17033. |
| [34] | VASWANI A, SHAZEER N, PARMAR N,et al .Attention is all you need[C]∥ Proceedings of Advances in Neural Information Processing Systems.Long Beach:MIT Press,2017:6000-6010. |
| [35] | GULATI A, QIN J, CHIU C C,et al .Conformer:convolution-augmented transformer for speech recognition[EB/OL].(2020-05-16)[2025-05-05].. |
| [36] | CHEN J, TAN X, LUAN J,et al .Hifisinger:towards high-fidelity neural singing voice synthesis[EB/OL].(2020-09-03)[2025-05-05].. |
/
| 〈 |
|
〉 |