
Journal of South China University of Technology(Natural Science) >
Contrastive Learning Model Based on Text-Visual and Information Entropy Minimization
Received date: 2024-04-07
Online published: 2024-09-13
Supported by
the Guangxi Innovation-Driven Development Project(AA20302001)
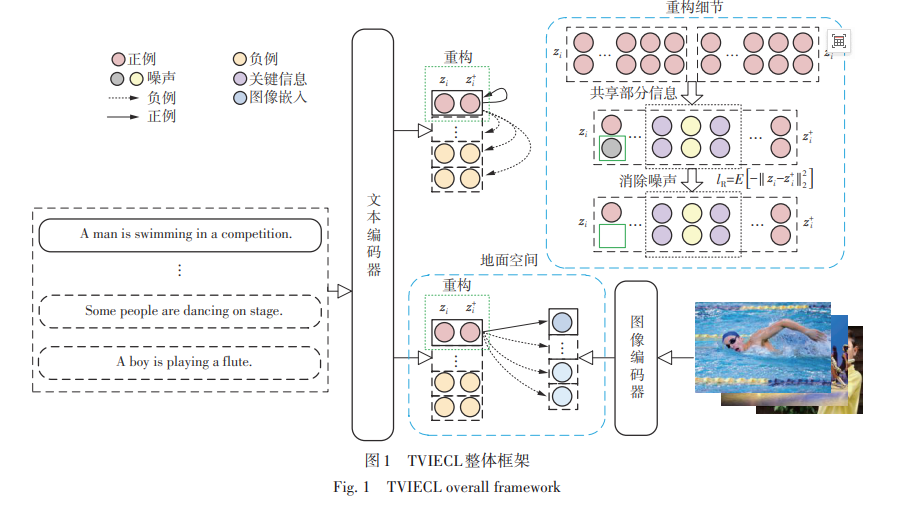
Current unsupervised contrastive learning methods mainly rely on pure textual information to construct sentence embeddings, which presents limitations in comprehensively understanding the deeper meanings conveyed by sentences. Meanwhile, traditional contrastive learning methods focus excessively on maximizing the mutual information between positive instances of text, overlooking the potential noise interference within sentence embeddings. To effectively retain useful information in the text while eliminating noise interference in the embeddings, the paper proposed a contrastive learning model based on text-vision and information entropy minimization. Firstly, the text and the corresponding visual information are deeply fused under the framework of contrastive learning, and jointly mapped to a unified grounding space, ensuring their representations remain consistent within this space. This approach overcomes the limitations of relying solely on pure textual information for sentence embedding learning, making the contrastive learning process more comprehensive and precise. Secondly, following the principle of information minimization, the model reconstructs positive text instances based on information entropy minimization while maximizing mutual information between positive text instances. Experimental results on the standard semantic textual similarity (STS) task demonstrate that the proposed model achieves significant improvements in the Spearman correlation coefficient evaluation metric, showcasing a notable advantage over existing state-of-the-art methods. This also confirms the effectiveness of the proposed model.
CAI Xiaodong , DONG Lifang , HUANG Yeyang , ZHOU Li . Contrastive Learning Model Based on Text-Visual and Information Entropy Minimization[J]. Journal of South China University of Technology(Natural Science), 2025 , 53(3) : 50 -56 . DOI: 10.12141/j.issn.1000-565X.240159
| 1 | GAO T, YAO X, CHEN D .SimCSE:simple contrastive learning of sentence embeddings[C]∥ Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing.Punta Cana:The Association for Computational Linguistics,2021:6894-6910. |
| 2 | ZHANG Z, CHEN K, WANG R,et al .Neural machine translation with universal visual representation[C]∥ Proceedings of the 8th International Conference on Learning Representations.[S. l.]:OpenReview.net,2020:1-14. |
| 3 | ZHAO Y, TITOV I .Visually grounded compound PCFGs [C]∥ Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing.[S. l.]:The Association for Computational Linguistics,2020:4369-4379. |
| 4 | LAZARIDOU A, PHAM N T, BARONI M .Combining language and vision with a multimodal skip-gram model [C]∥ Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Denver:The Association for Computational Linguistics,2015:153-163. |
| 5 | ZABLOCKI E, PIWOWARSKI B, SOULIER L,et al. Learning multi-modal word representation grounded in visual context[C]∥ Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence.New Orleans:AAAI,2018:5626-5633. |
| 6 | KIELA D, CONNEAU A, JABBRI A,et al .Learning visually grounded sentence representations[C]∥ Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.New Orleans:The Association for Computational Linguistics,2018:408-418. |
| 7 | BORDES P, ZABLOCKI é, SOULIER L,et al .Incorporating visual semantics into sentence representations within a grounded space[C]∥ Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong:The Association for Computational Linguistics,2019:696-707. |
| 8 | TAN H, BANSAL M .Vokenization:improving language understanding with contextualized,visual-grounded supervision[C]∥ Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing.[S.l.]:The Association for Computational Linguistics,2020:2066-2080. |
| 9 | TANG Z, CHO J, TAN H,et al .Vidlankd:impro-ving language understanding via video-distilled knowledge transfer[J].Advances in Neural Information Processing Systems,2021,34:24468-24481. |
| 10 | ZHOU K, ZHANG B, ZHAO W X,et al .Debiased contrastive learning of unsupervised sentence representations[C]∥ Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics.Dublin:The Association for Computational Linguistics,2022:6120-6130. |
| 11 | HOU P, LI X .Improving contrastive learning of sentence embeddings with focal infoNCE[C]∥ Procee-dings of the 2023 Conference on Empirical Methods in Natural Language Processing.Singapore:The Association for Computational Linguistics,2023:4757-4762. |
| 12 | WU X, GAO C, SU Y,et al .Smoothed contrastive learning for unsupervised sentence embedding[C]∥ Proceedings of the 29th International Conference on Computational Linguistics.Gyeongju:International Committee on Computational Linguistics,2022:4902-4906. |
| 13 | KLEIN T, NABI M .SCD:self-contrastive decorrelation of sentence embeddings[C]∥ Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics.Dublin:The Association for Computational Linguistics,2022:394-400. |
| 14 | TIAN Y, SUN C, POOLE B,et al .What makes for good views for contrastive learning?[J].Advances in Neural Information Processing Systems,2020,33:6827-6839. |
| 15 | TSAI Y H H, WU Y, SALAKHUTDINOV R,et al .Self-supervised learning from a multi-view perspective [C]∥ Proceedings of the 9th International Conference on Learning Representations.[S.l.]:OpenReview.net,2021:1-18. |
| 16 | ZHANG M, MOSBACH M, ADELANI D,et al .MCSE:multimodal contrastive learning of sentence embeddings[C]∥ Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.Seattle:The Association for Computational Linguistics,2022:5959-5969. |
| 17 | ZHANG H, WU C, ZHANG Z,et al .ResNeSt:split-attention networks[C]∥ Proceedings of 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops.New Orleans:IEEE,2022:2735-2745. |
| 18 | CHEN S, ZHOU J, SUN Y,et al .An information minimization based contrastive learning model for unsupervised sentence embeddings learning[C]∥ Procee-dings of the 29th International Conference on Computational Linguistics.Gyeongju:International Committee on Computational Linguistics,2022:4821-4831. |
| 19 | YOUNG P, LAI A, HODOSH M,et al .From image descriptions to visual denotations: new similarity me-trics for semantic inference over event descriptions[J].Transactions of the Association for Computational Linguistics,2014,2:67-78. |
| 20 | LIN T Y, MAIRE M, BELONGIE S,et al .Microsoft COCO:common objects in context[C]∥ Proceedings of the 13th European Conference on Computer Vision.Zurich:Springer,2014:740-755. |
/
| 〈 |
|
〉 |