Journal of South China University of Technology(Natural Science Edition) ›› 2026, Vol. 54 ›› Issue (2): 1-15.doi: 10.12141/j.issn.1000-565X.250152
• Computer Science & Technology • Previous Articles Next Articles
Target Navigation Method Based on Multimodal Scene Memory and Instruction Prompting
DONG Min, LAI Youcheng, BI Sheng
- School of Computer Science and Engineering,South China University of Technology,Guangzhou 510006,Guangdong,China
-
Received:2025-05-26Online:2026-02-25Published:2025-09-19 -
About author:董敏(1977—),女,博士,副教授,主要从事智能系统研究。E-mail: hollymin@scut.edu.cn -
Supported by:the Natural Science Foundation of Guangdong Province(2022B1515020015)
CLC Number:
Cite this article
DONG Min, LAI Youcheng, BI Sheng. Target Navigation Method Based on Multimodal Scene Memory and Instruction Prompting[J]. Journal of South China University of Technology(Natural Science Edition), 2026, 54(2): 1-15.
share this article

Fig.1
Architecture of MEMO-NAV system"
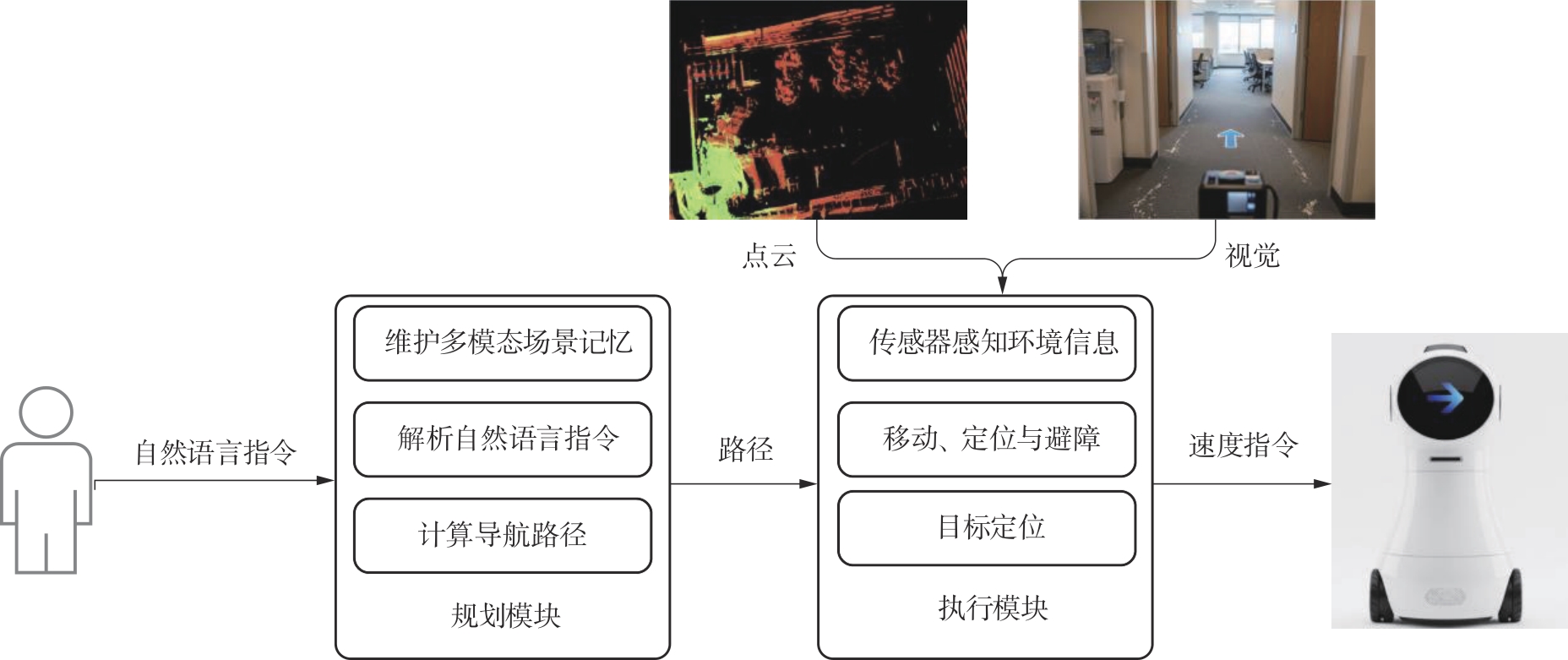
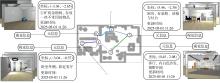
Fig.2
Multimodal scene memory at a simulated environment"
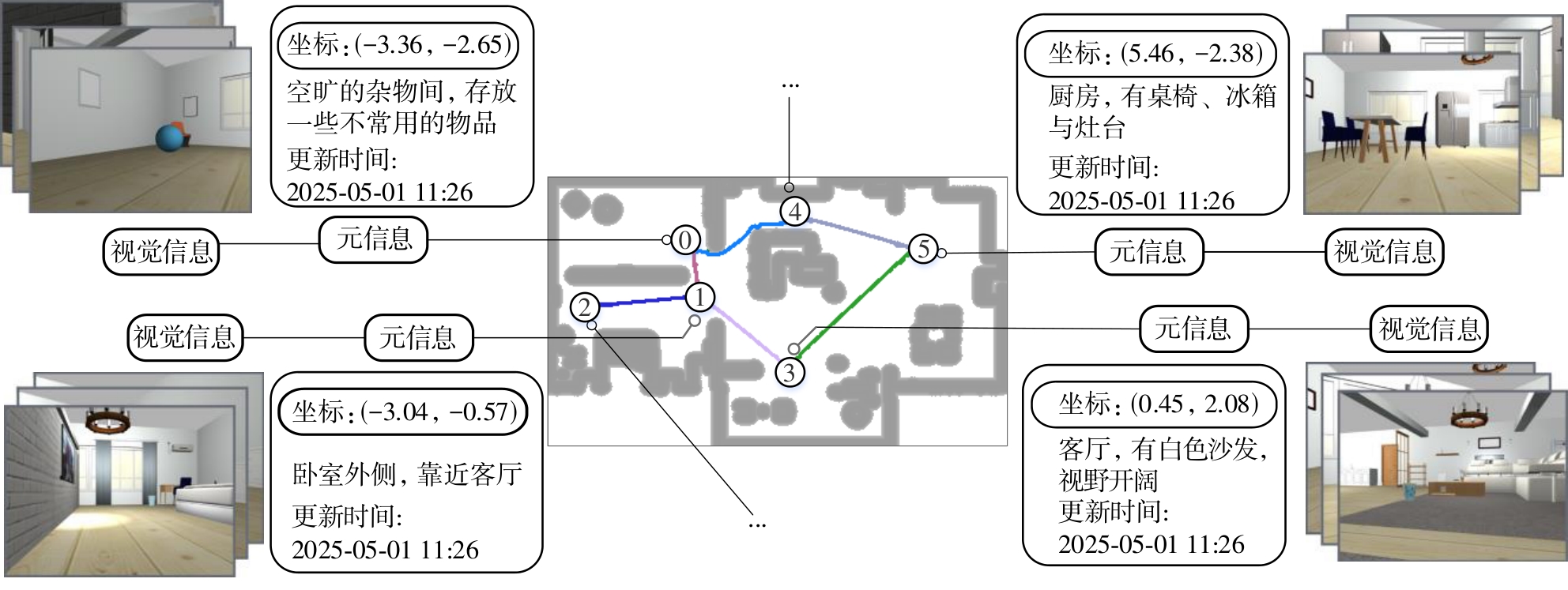
Fig.3
Indoor simulation environment and grid map"
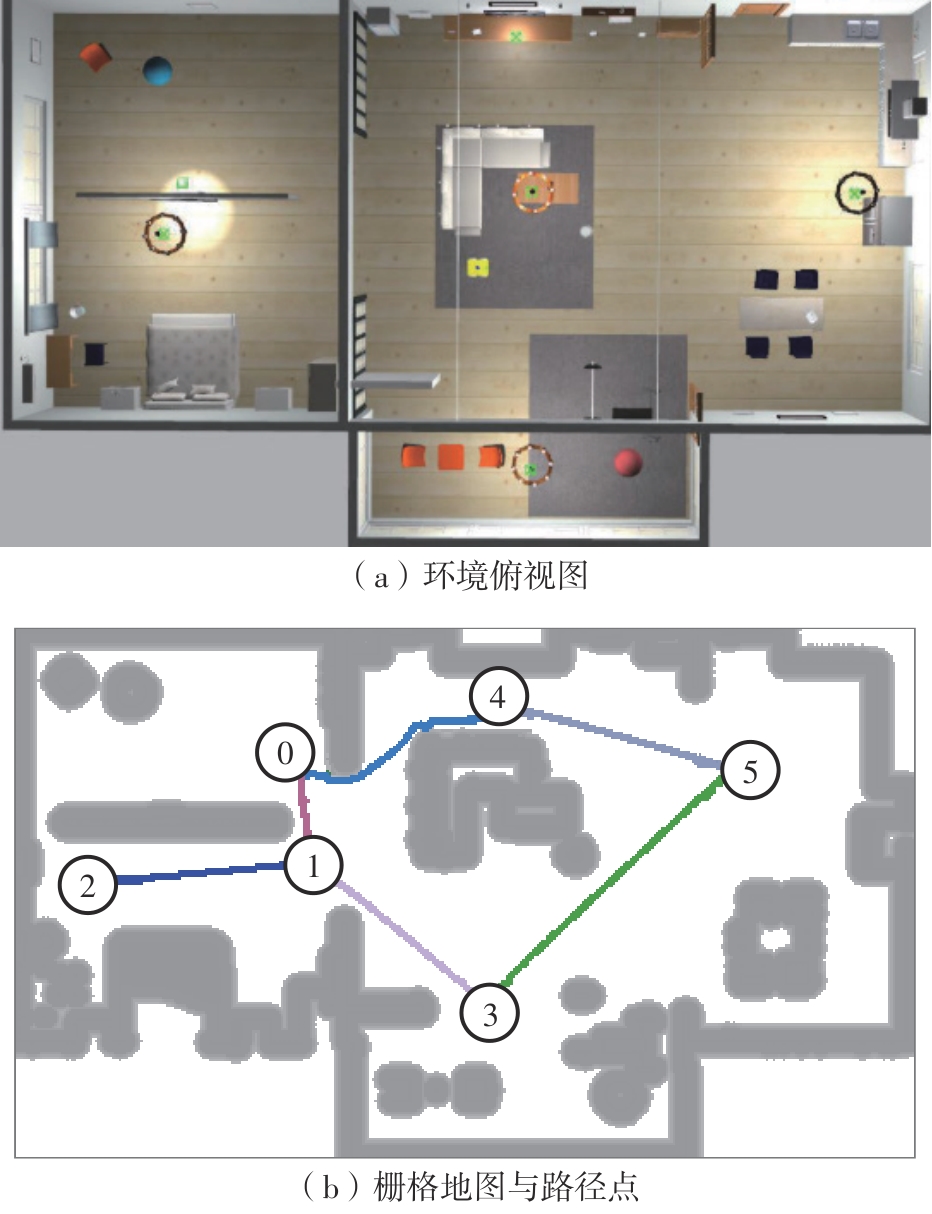
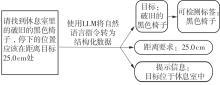
Fig.4
Parsing results of natural language instructions"
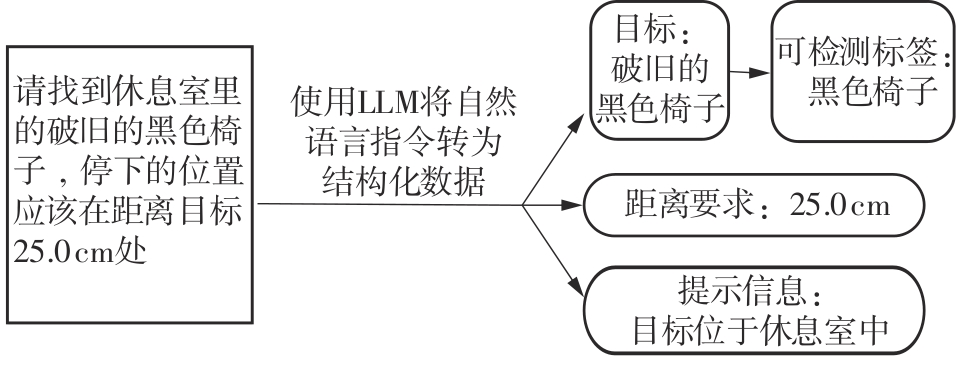
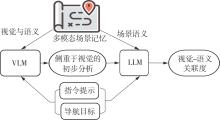
Fig.5
Calculation process of visual-semantic relevance"
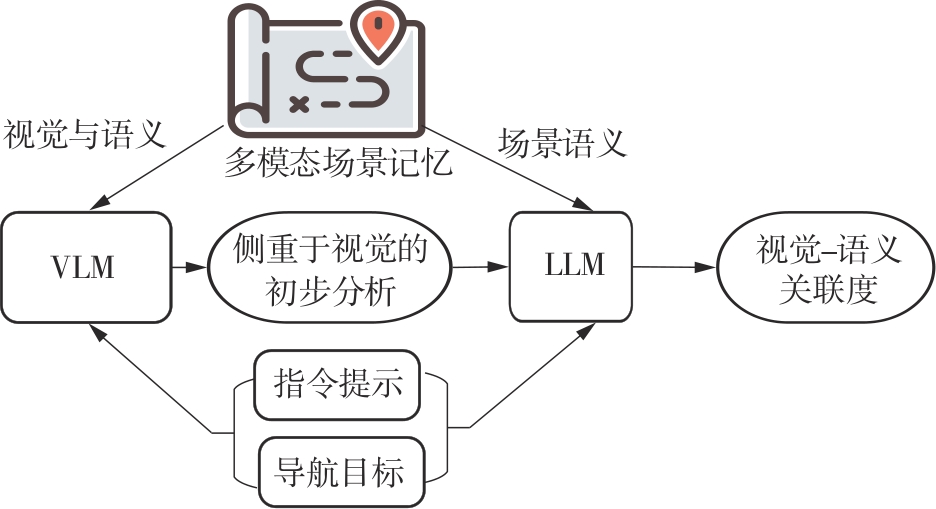

Fig.6
Target localization workflowtarget_px,target_py=xy_to_pxpy(target_pos)self_px,self_py=xy_to_pxpy(self_pos)θ = atan2(target_py-self_py,target_px-self_px)queue=[(target_px,target_py,0)] //(x,y,distance)visited = set()"
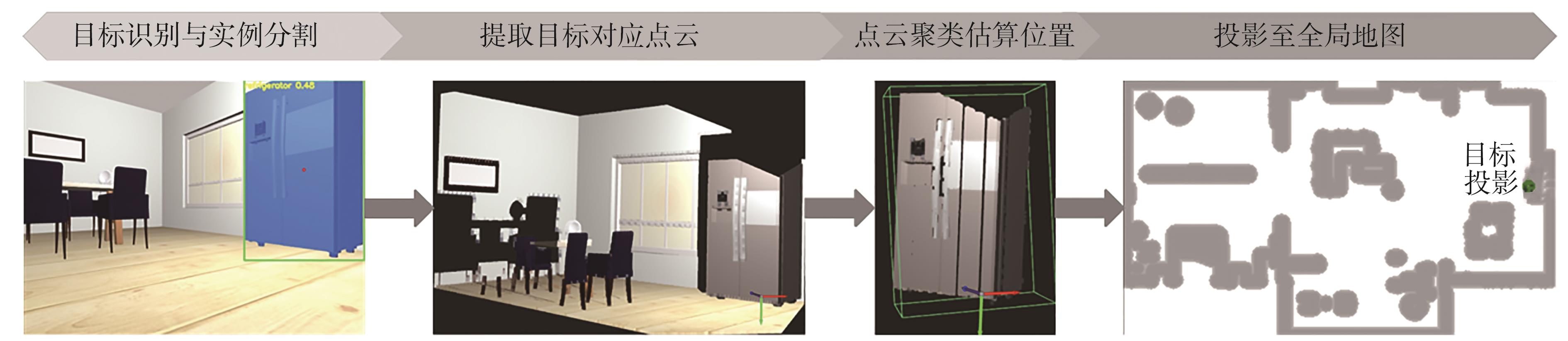
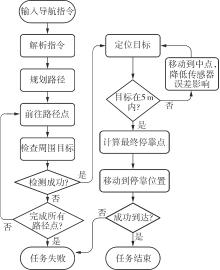
Fig.7
Single-instance target navigation process"
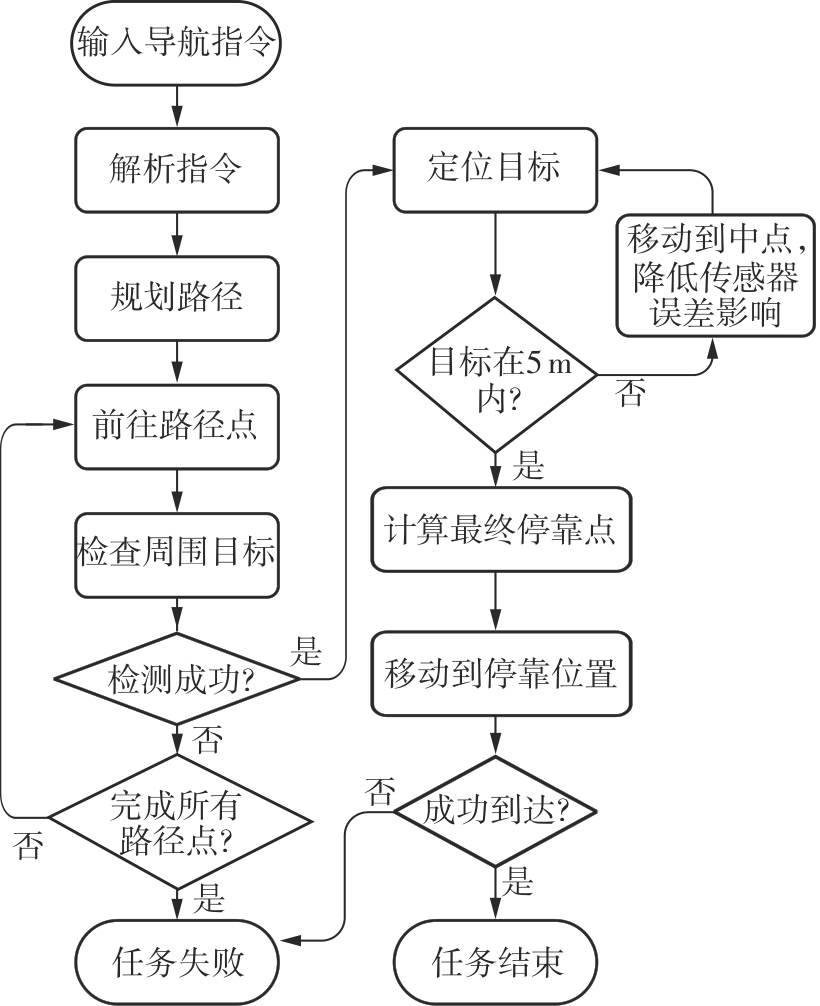
Table 1
Performance comparison of different algorithms"
| 算法 | RS/% | RSPL/% | RSCT/% | RSPRS(1)/% | RSPRS(2)/% | RSPRS(3)/% |
|---|---|---|---|---|---|---|
| 距离优先 | 48.19 | 29.08 | 29.68 | 10.14 | 18.84 | 26.45 |
| LGX | 59.78 | 42.20 | 27.25 | 24.64 | 36.96 | 47.10 |
| LM-Nav | 58.33 | 36.58 | 39.94 | 13.58 | 25.31 | 38.27 |
| MEMO-Nav | 78.98 | 63.10 | 41.46 | 59.78 | 68.48 | 74.64 |
Table 2
Performance comparison of different algorithms under stable and changing environmental conditions"
| 算法 | ||||||
|---|---|---|---|---|---|---|
| 环境稳定 | 环境变化 | 环境稳定 | 环境变化 | 环境稳定 | 环境变化 | |
| 距离优先 | 49.28 | 47.10 | 30.04 | 28.12 | 30.35 | 29.01 |
| LGX | 58.69 | 61.73 | 42.49 | 41.91 | 26.09 | 28.41 |
| LM-Nav | 65.94 | 50.72 | 42.72 | 30.44 | 43.75 | 36.13 |
| MEMO-Nav | 82.61 | 75.36 | 67.03 | 59.17 | 43.84 | 39.08 |
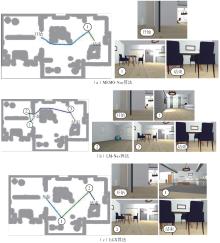
Fig.8
Path of three algorithms when executing the instruction of “Locate the black chair in the kitchen”"
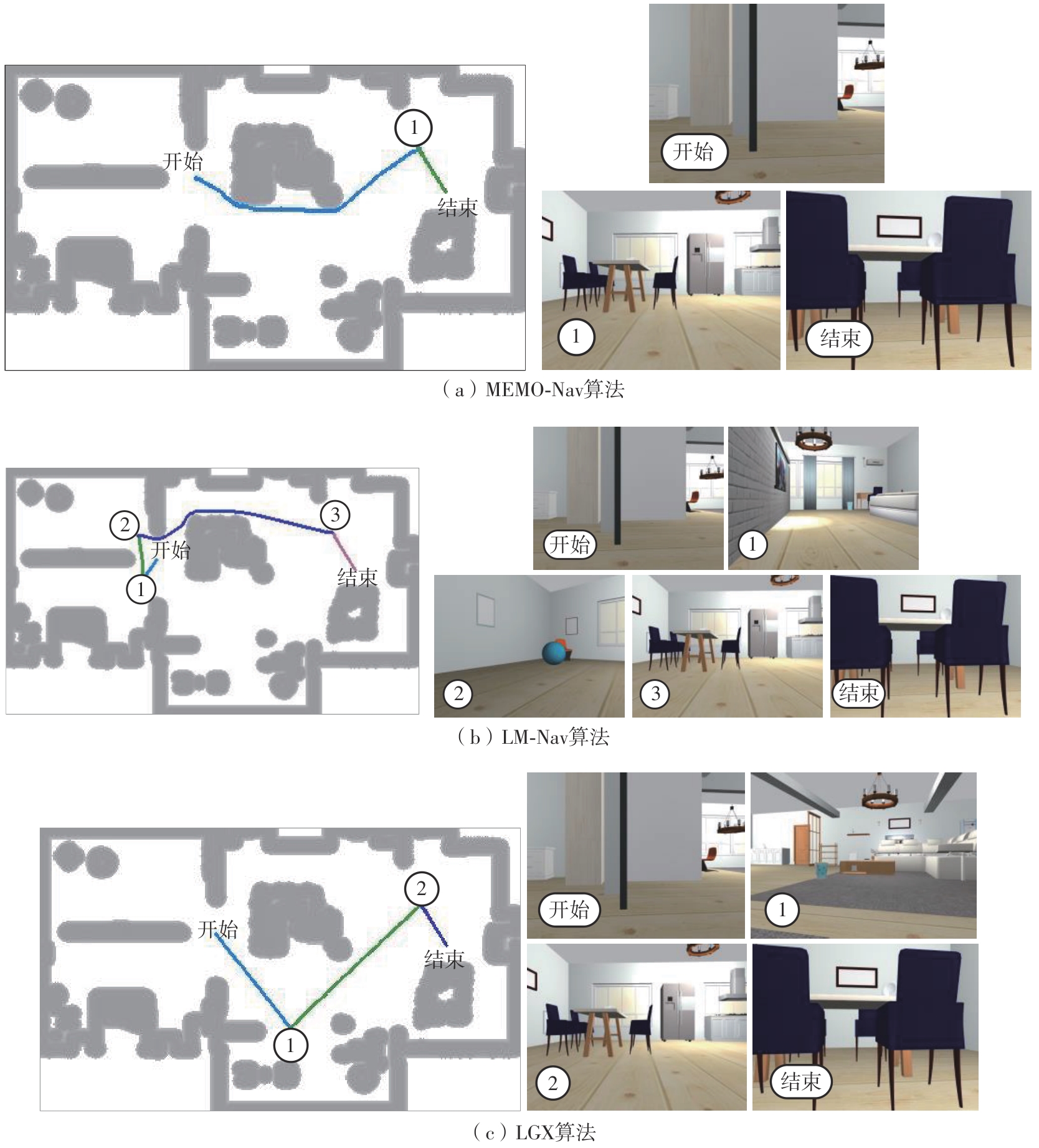
Table 3
Required time and path length of three algorithms when executing the instruction “Locate the black chair in the kitchen”"
| 算法 | 最短路径/m | 实际路径/m | 执行用时/s | 规划用时/s | 总用时/s |
|---|---|---|---|---|---|
| MEMO-Nav | 9.79 | 12.20 | 43.80 | 27.53 | 71.33 |
| LM-Nav | 9.79 | 22.51 | 77.99 | 4.12 | 82.11 |
| LGX | 9.79 | 14.58 | 53.78 | 50.44 | 104.22 |
Table 4
Ablation experiment results"
| 方案 | RS/% | RSPL/% | RSCT/% | RSPRS(1)/% | RSPRS(2)/% | RSPRS(3)/% |
|---|---|---|---|---|---|---|
| 1 | 68.48 | 48.90 | 38.31 | 48.91 | 55.79 | 67.39 |
| 2 | 75.36 | 58.42 | 40.12 | 56.16 | 64.49 | 72.10 |
| 3 | 78.99 | 63.10 | 41.46 | 59.78 | 68.84 | 74.64 |
Table 5
Ablation experiment results under two environmental conditions"
| 方案 | ||||||
|---|---|---|---|---|---|---|
| 环境稳定 | 环境变化 | 环境稳定 | 环境变化 | 环境稳定 | 环境变化 | |
| 1 | 76.54 | 60.44 | 57.11 | 40.69 | 41.45 | 36.17 |
| 2 | 79.01 | 71.60 | 63.11 | 53.74 | 41.89 | 38.35 |
| 3 | 82.72 | 75.31 | 67.03 | 59.17 | 42.83 | 39.29 |
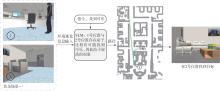
Fig.9
Execute the instruction “Find the cola” using only visual information (where the target object was not present during mapping)"
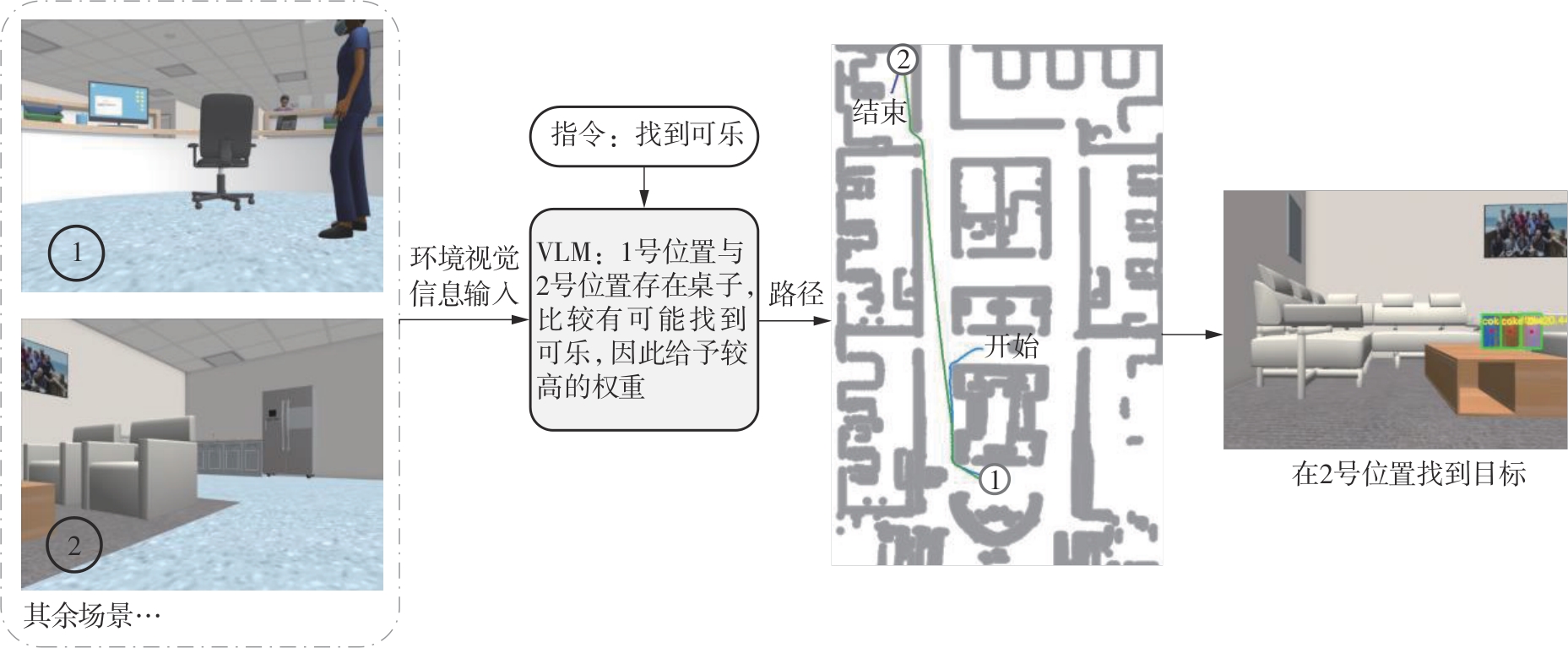
Fig.10
Execute the instruction “Find the cola” using both visual and semantic information (where the target object was not present during mapping)"
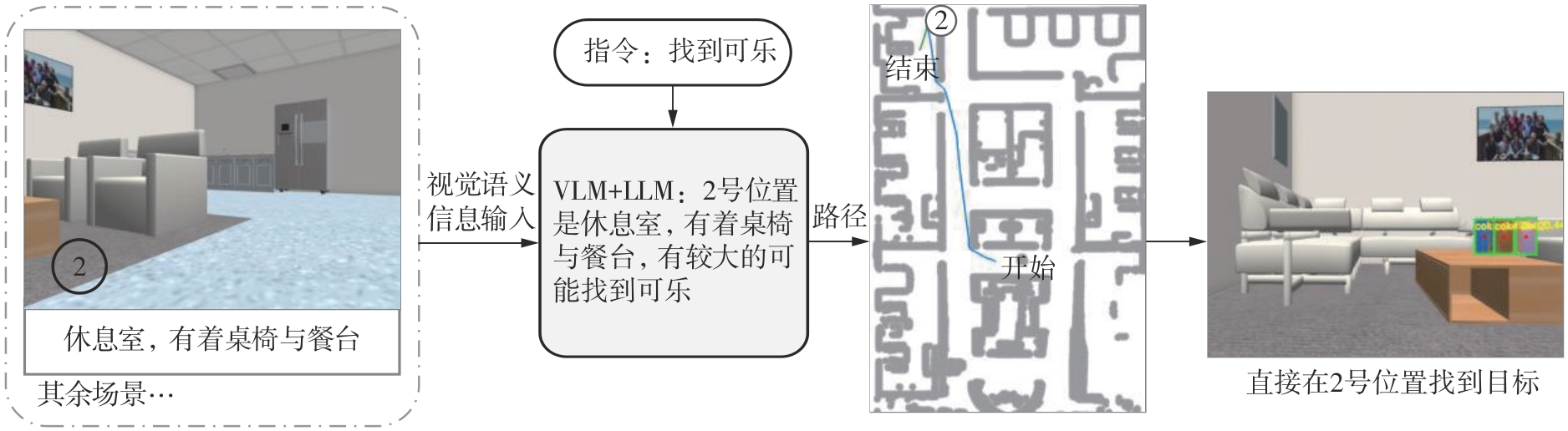
Fig.11
Influence of prompt information in instructions on performing the same target navigation task"
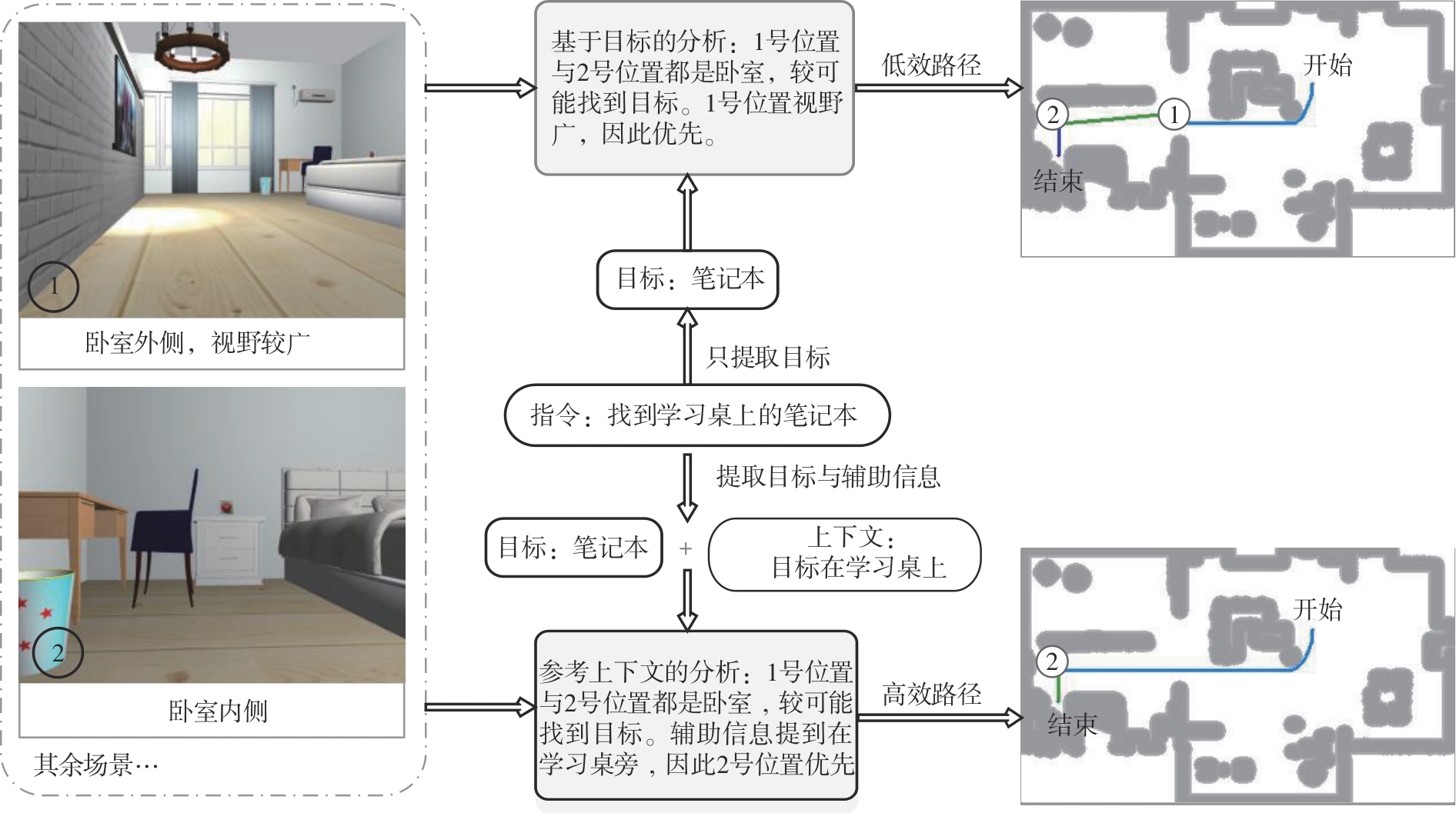
Table 6
Target localization accuracy of MEMO-Nav in a simulated environment"
| 误差/cm | RIHR/% | EMOID/cm |
|---|---|---|
| 10.0 | 58.87 | 4.3 |
| 12.5 | 65.25 | 3.4 |
| 15.0 | 74.47 | 2.6 |
| 17.5 | 80.14 | 2.1 |
| 20.0 | 83.69 | 1.7 |

Fig.12
Robot used in real-world environment experiments"

Table 7
Performance metrics for various approaches in real-world environments"
| 算法 | RS/% | RSPL/% | RSCT/% |
|---|---|---|---|
| LGX | 48.44 | 38.74 | 19.15 |
| LM-Nav | 46.87 | 39.02 | 26.42 |
| MEMO-Nav | 64.06 | 47.21 | 32.81 |

Fig.13
Real-world execution of MEMO-Nav for the command “Identify the white fan in the office area”"
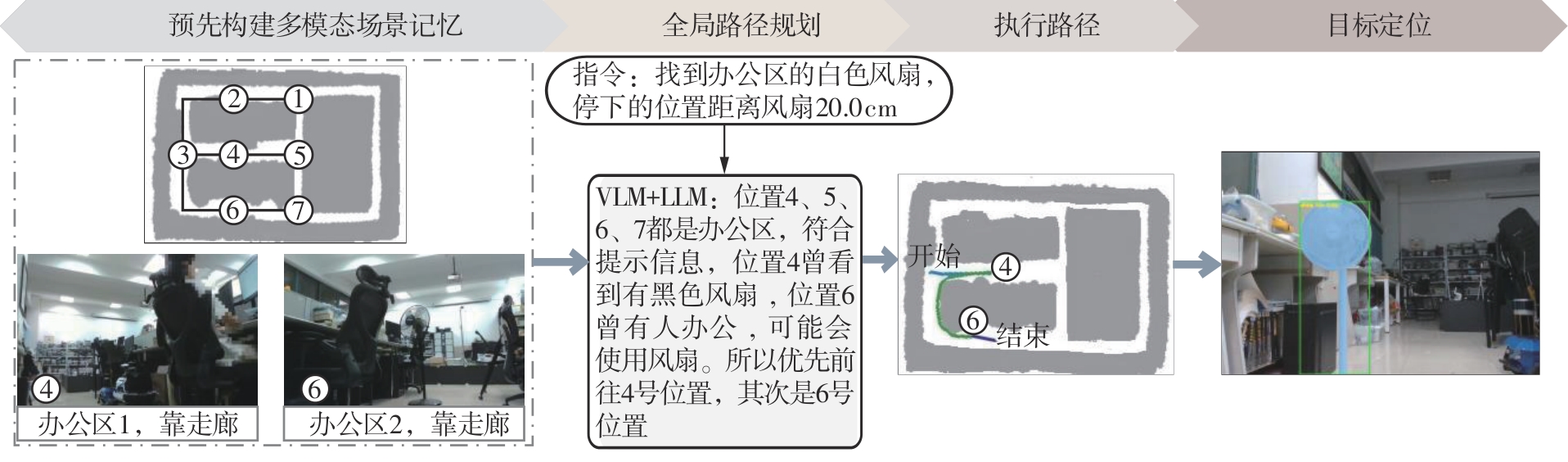
Table 8
Target localization accuracy of MEMO-Nav in real-world environments"
| 误差/cm | RIHR/% | EMOID/cm |
|---|---|---|
| 10.0 | 44.59 | 6.7 |
12.5 15.0 17.5 | 51.35 54.05 60.80 | 5.2 4.5 2.9 |
| 20.0 | 77.03 | 2.5 |
| [1] | SUN J, WU J, JI Z,et al .A survey of object goal navigation[J].IEEE Transactions on Automation Science and Engineering,2024,22:2292-2308. |
| [2] | LI B, HAN J, CHENG Y,et al .Object goal navigation in embodied AI:a survey[C]∥ Proceedings of 2022 the 4th International Conference on Video,Signal and Image Processing.Shanghai:ACM,2022:87-92. |
| [3] | ZHU Y, MOTTAGHI R, KOLVE E,et al .Target-driven visual navigation in indoor scenes using deep reinforcement learning [C]∥ Proceedings of 2017 IEEE International Conference on Robotics and Automation.Singapore:IEEE,2017:3357-3364. |
| [4] | CHAPLOT D S, GANDHI D P, GUPTA A,et al .Object goal navigation using goal-oriented semantic exploration[C]∥ Proceedings of the 34th Conference on Advances in Neural Information Processing Systems.[S.l.]:Curran Associates,2020:4247-4258. |
| [5] | VASWANI A, SHAZEER N, PARMAR N,et al .Attention is all you need [C]∥ Proceedings of the 31st Conference on Neural Information Processing Systems.Long Beach:Curran Associates,2017:5998-6008. |
| [6] | DU H, YU X, ZHENG L .VTNet:visual transformer network for object goal navigation[C]∥ Proceedings of the 9th International Conference on Learning Representations.[S.l.]:OpenReview,2021:1-16. |
| [7] | FUKUSHIMA R,OTA K, KANEZAKI A,et al .Object memory transformer for object goal navigation [C]∥ Proceedings of 2022 International Conference on Robotics and Automation.Philadelphia:IEEE,2022:11288-11294. |
| [8] | ZHOU K, GUO C, ZHANG H,et al .Optimal graph transformer Viterbi knowledge inference network for more successful visual navigation[J].Advanced Engineering Informatics,2023,55,101889/ 1-11. |
| [9] | DU H, LI L, HUANG Z,et al .Object-goal visual navigation via effective exploration of relations among historical navigation states[C]∥ Proceedings of 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Vancouver:IEEE,2023:2563-2573. |
| [10] | SHAH D, EYSENBACH B, KAHN G,et al .ViNG:learning open-world navigation with visual goals[C]∥ Proceedings of 2021 IEEE International Conference on Robotics and Automation.Xi’ an:IEEE,2021:13215-13222. |
| [11] | SHAH D, SRIDHAR A, DASHORA N,et al .ViNT:a foundation model for visual navigation[C]∥ Procee-dings of the 7th Conference on Robot Learning.Atlanta:OpenReview,2023:711-733. |
| [12] | SHAH D, OSINSKI B, LEVINE S,et al .LM-Nav:robotic navigation with large pre-trained models of language,vision,and action[C]∥ Proceedings of the 6th Conference on Robot Learning.Auckland:OpenReview,2022:492-504. |
| [13] | RADFORD A, KIM J W, HALLACY C,et al .Learning transferable visual models from natural language supervision[C]∥ Proceedings of the 38th International Conference on Machine Learning.[S.l.]:ML Research Press,2021:8748-8763. |
| [14] | DORBALA V S, MULLEN J F, MANOCHA D .Can an embodied agent find your “cat-shaped mug”?LLM-based zero-shot object navigation[J].IEEE Robotics and Automation Letters,2024,9(5):4083-4090. |
| [15] | SHAH D, EQUI M R, OSINSKI B,et al .Navigation with large language models:semantic guesswork as a heuristic for planning[C]∥ Proceedings of the 7th Conference on Robot Learning.Atlanta:OpenReview,2023:2683-2699. |
| [16] | ZHOU G, HONG Y, WU Q .NavGPT:explicit reasoning in vision-and-language navigation with large language models[C]∥ Proceedings of the 38th AAAI Conference on Artificial Intelligence.Vancouver:AAAI,2024:7641-7649. |
| [17] | HUANG W, XIA F, SHAH D,et al .Grounded decoding:guiding text generation with grounded models for embodied agents[C]∥ Proceedings of the 37th Conference on Neural Information Processing Systems.New Orleans:Curran Associates,2023:59636-59661. |
| [18] | LONG Y, CAI W, WANG H,et al .InstructNav:zero-shot system for generic instruction navigation in unexplored environment[C]∥ Proceedings of the 8th Conference on Robot Learning.Munich:OpenReview,2024:2049-2060. |
| [19] | MACENSKI S, FOOTE T, GERKEY B,et al .Robot operating system 2:design,architecture,and uses in the wild[J].Science Robotics,2022,7:eabm6074/1-12. |
| [20] | MACENSKI S, SORAGNA A, CARROLL M,et al .Impact of ROS 2 node composition in robotic systems [J].IEEE Robotics and Automation Letters,2023,8(7):3996-4003. |
| [21] | 丛明,温旭,王明昊,等 .基于迭代卡尔曼滤波器的GPS-激光-IMU融合建图算法[J].华南理工大学学报(自然科学版),2024,52(3):75-83. |
| CONG Ming, WEN Xu, WANG Minghao,et al .A GPS-laser-IMU fusion mapping algorithm based on ite-rated Kalman filter[J].Journal of South China University of Technology (Natural Science Edition),2024,52(3):75-83. | |
| [22] | KHANAM R, HUSSAIN M .YOLOv11:an overview of the key architectural enhancements[EB/OL].(2024-10-23)[2025-01-10].. |
| [23] | MINDERER M, GRITSENKO A, HOULSBY N .Scaling open-vocabulary object detection[C]∥ Proceedings of the 37th Conference on Neural Information Processing Systems.New Orleans:Curran Associates,2023:72983-73007. |
| [24] | KIRILLOV A, MINTUN E, RAVI N,et al .Segment anything[C]∥ Proceedings of 2023 IEEE/CVF International Conference on Computer Vision.Paris:IEEE,2023:3992-4003. |
| [25] | SCHUBERT E, SANDER J, ESTER M,et al .DBSCAN revisited,revisited:why and how you should (still) use DBSCAN[J].ACM Transactions on Database Systems,2017,42(3):1-21. |
| [1] | XIONG Lu , FENG Haojie ZHANG Peizhi , et al. Review of Learning-Based Methods For Generating Interactive Scenarios in Autonomous Driving [J]. Journal of South China University of Technology(Natural Science Edition), 2026, 54(3): 31-51. |
| [2] | TU Xinhui, GUO Cong, ZONG Yuhang. Information Retrieval Re-Ranking Method Based on Bidirectional Text Expansion [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(9): 59-67. |
| [3] | MA Xiaoliang, GAO Jie, LIU Ying, PEI Qingqi, ZHAO Ruqiang, YANG Bangxing, DENG Congjian. Customer Service Knowledge Recommendation Large Model Construction Driven by Intent Understanding [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(3): 40-49. |
| [4] | PEI Mingyang, SHAO Kangshun, LI Linqing, XU Fengjuan. Modeling Methodologies for Unmanned Aerial Vehicle Path Planning in Emergency Rescue: A Comprehensive Review and Prospect [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(12): 17-33. |
| [5] | GUAN Xin, LIU Chenxi, LI Qiang. 3D Hand Pose Estimation with Multimodal Feature Fusion Guided by Depth Geometric Features [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(11): 37-51. |
| [6] | CHENG Guozhu, XUE Daoan, GU Shuang. Path Planning Method Integrating Curve Combination and Numerical Optimization for Parallel Parking on Narrow Road [J]. Journal of South China University of Technology(Natural Science Edition), 2025, 53(11): 77-89. |
| [7] | YAO Daojin, YIN Xiong, LUO Zhen, et al. AGVS Path Planning Algorithm in Complex Environments [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(11): 56-62. |
| [8] | WEN Huiying, YUAN Yuqing, LIN Yifeng. Conflict-Free Path Planning For Multi-AGVs in Automated Terminals Considering Road Load Balancing [J]. Journal of South China University of Technology(Natural Science Edition), 2023, 51(10): 1-10. |
| [9] | WEI Wu, HAN Jin, LI Yanjie, et al. Path Planning of Mobile Robots Based on Dual-Tree Quick-RRT* Algorithm [J]. Journal of South China University of Technology (Natural Science Edition), 2021, 49(7): 51-58. |
| [10] | WEN Huiying, LIN Yifeng, WU Haoshu, et al. Extended Co-evolutionary Algorithm for Path Planning Based on the Urban Traffic Environment Evolution [J]. Journal of South China University of Technology (Natural Science Edition), 2021, 49(10): 1-10. |
| [11] | ZHANG Jiaxu, YANG Xiong, SHI Zhengtang, et al. Path Planning and Tracking Control for Emergency Lane Change and Obstacle Avoidance of Vehicles [J]. Journal of South China University of Technology(Natural Science Edition), 2020, 48(9): 86-93,106. |
| [12] | ZHAO Xing JI Kang LIN Hao XU Peng. Resource Allocation Model Based on Multi-objective Path Planning in Emergency Management [J]. Journal of South China University of Technology(Natural Science Edition), 2019, 47(4): 76-82. |
| [13] | HONG Xiaobin WEI Xinyong HUANG Yesheng LIU Yanxia XIAO Guoquan. Local Path Planning Method for Unmanned Surface Vehicle Based on Image Recognition and VFH + [J]. Journal of South China University of Technology(Natural Science Edition), 2019, 47(10): 24-33. |
| [14] | PAN Xiao-fang ZHOU Shun-ping YANG Lin WAN Bo. Origin Destination Constraint Experience Model of Taxi and Path Planning [J]. Journal of South China University of Technology (Natural Science Edition), 2017, 45(8): 57-64,83. |
| [15] | WU Yu-xiang WANG Chao. An Improved Three-Dimensional Path Planning Method of Mobile Robot [J]. Journal of South China University of Technology (Natural Science Edition), 2016, 44(9): 53-60. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||