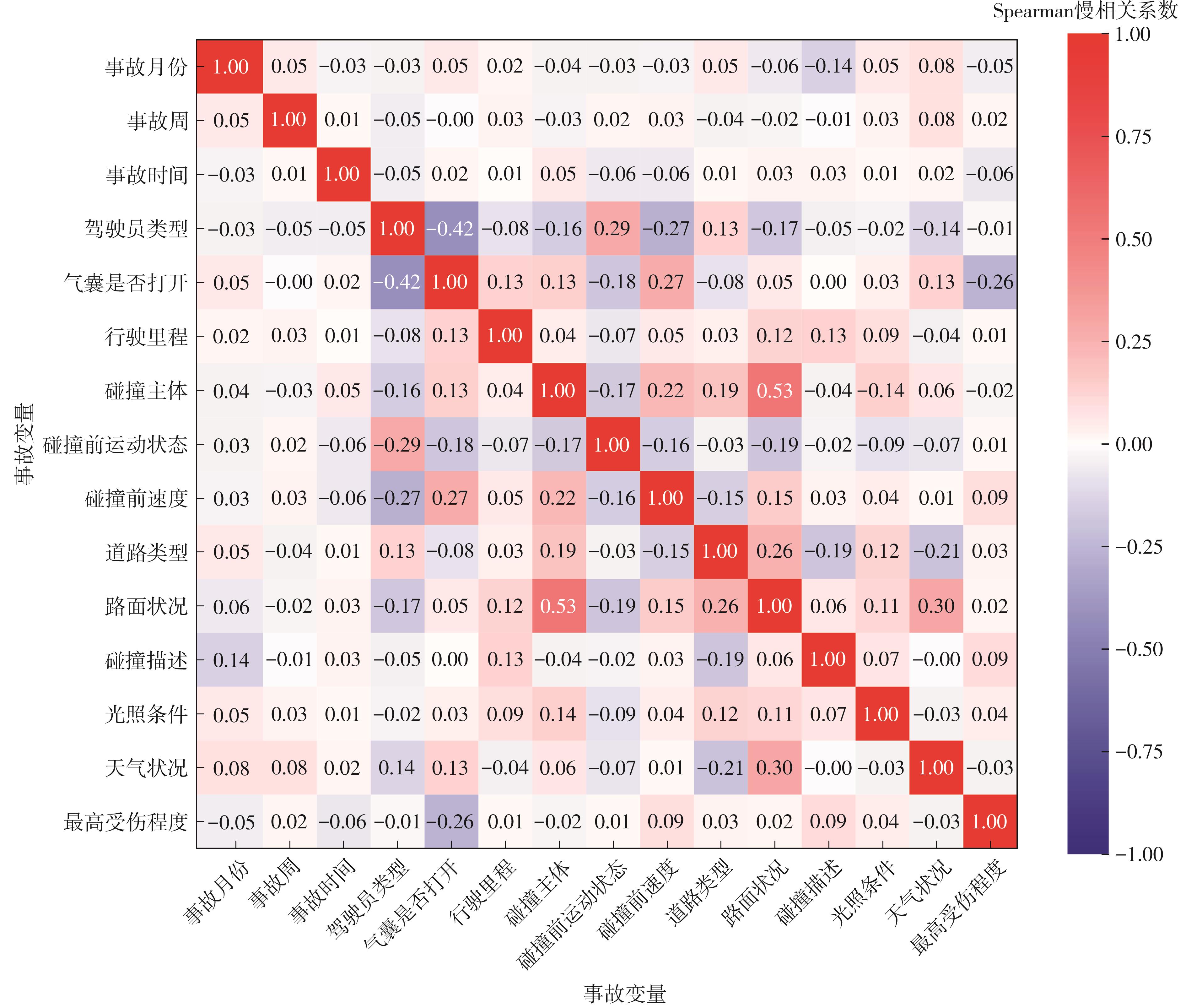
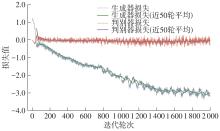
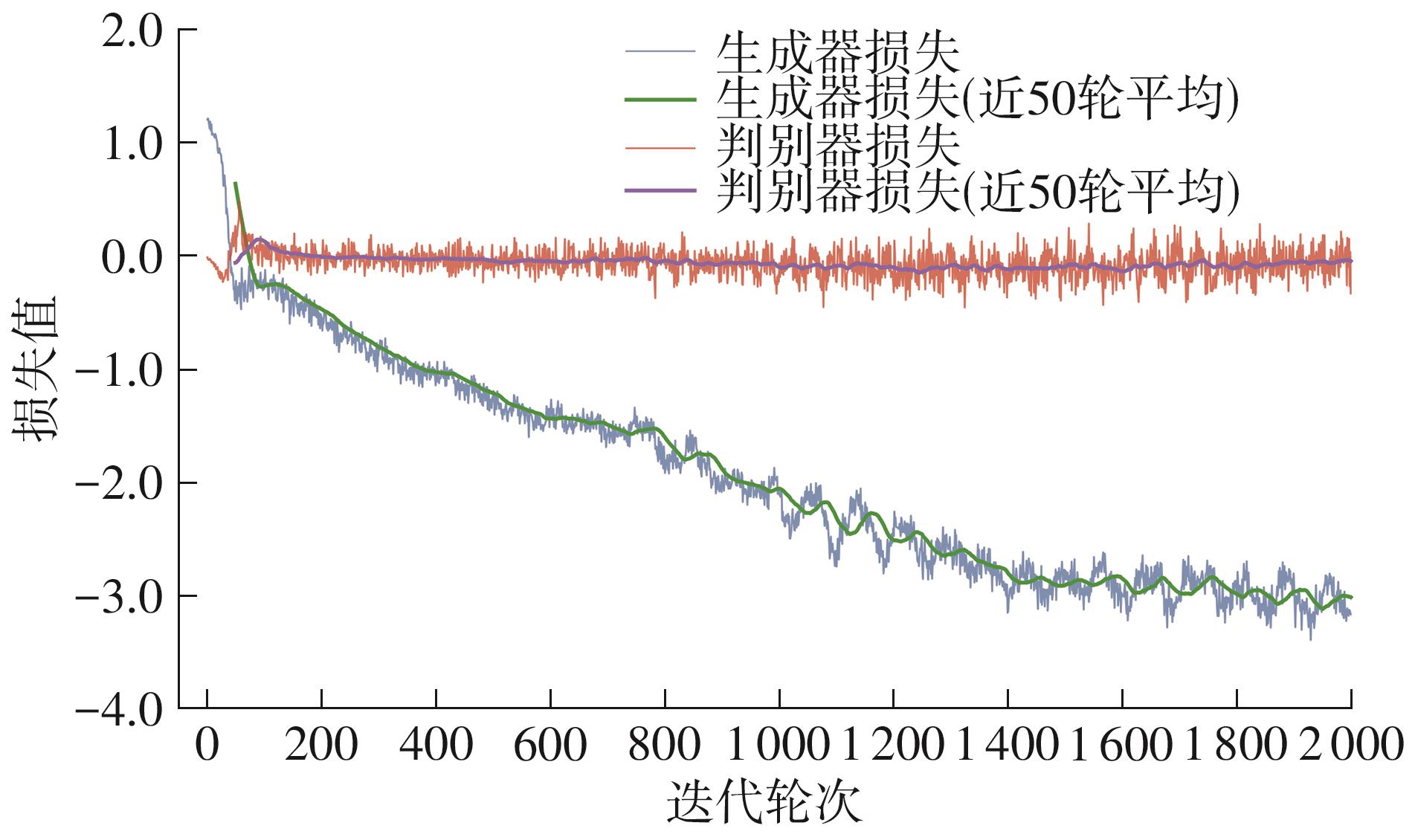
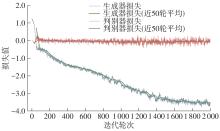
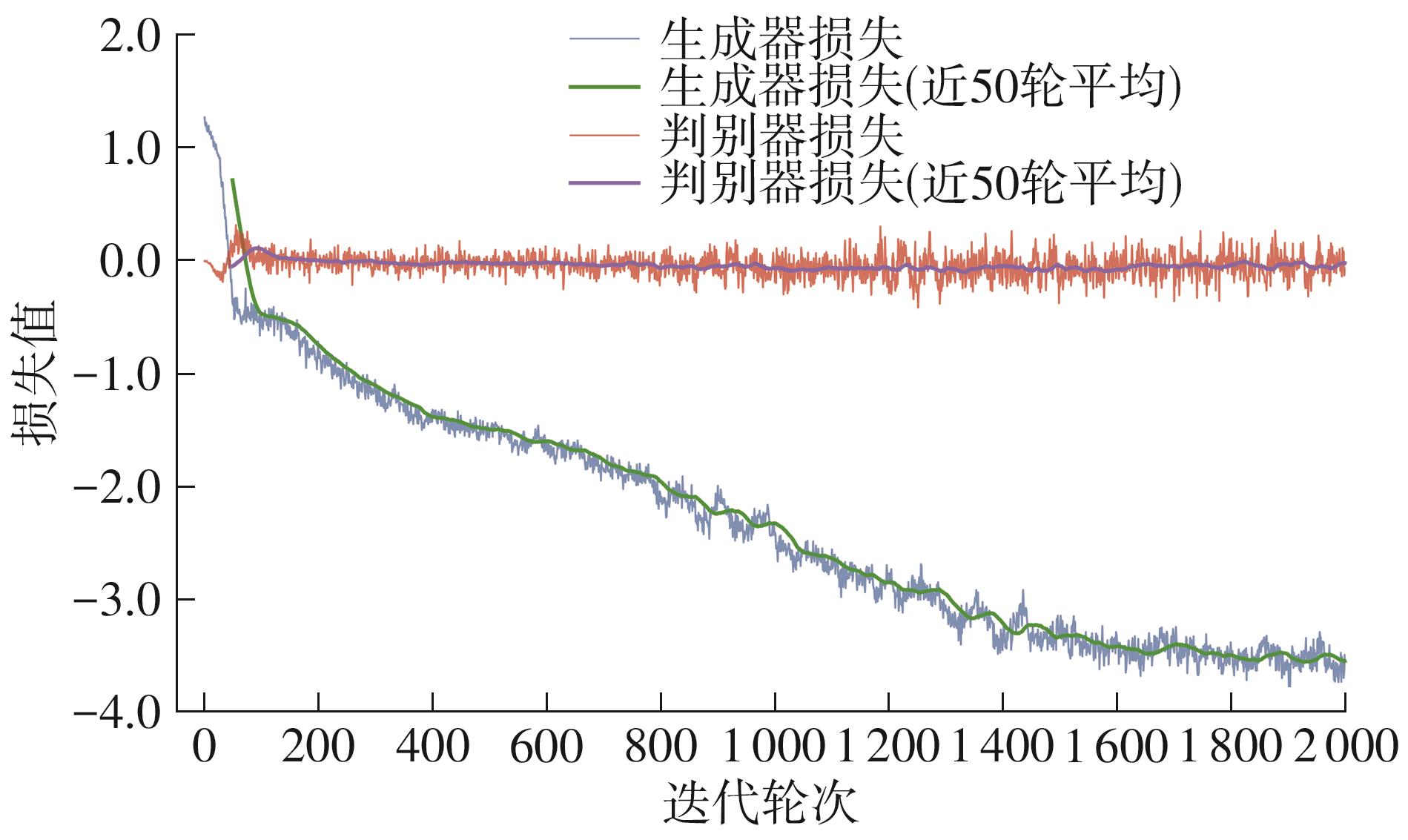
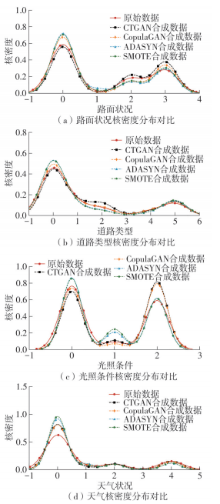
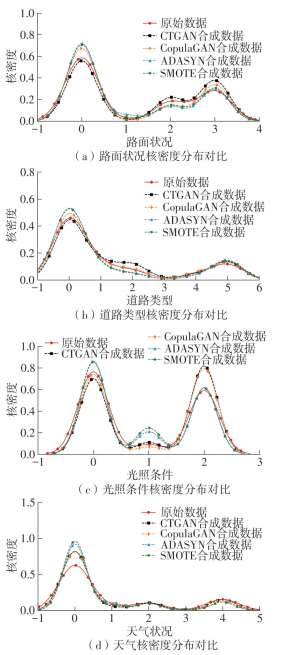
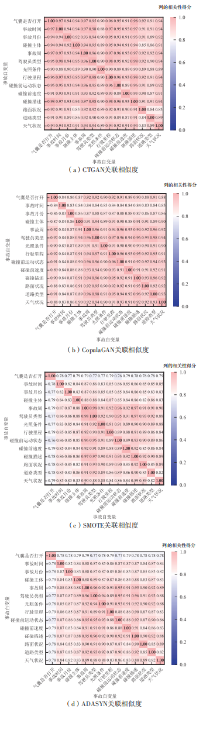
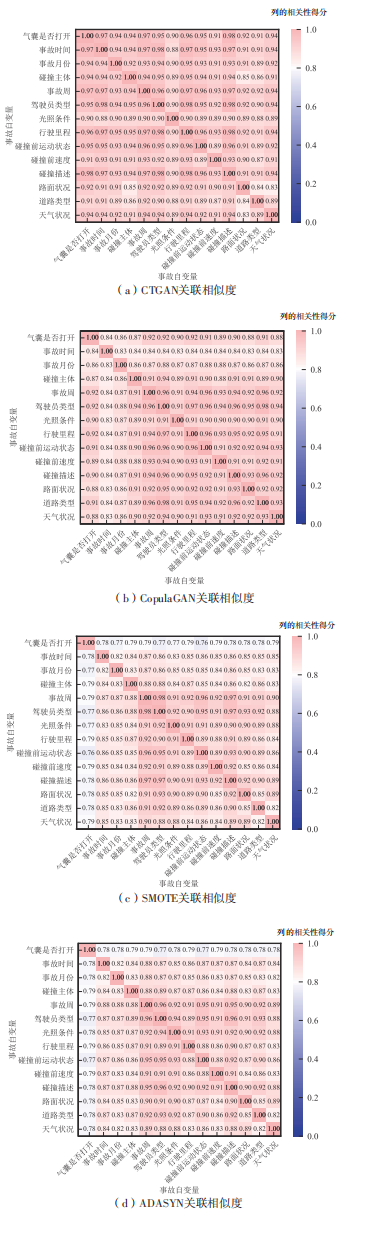
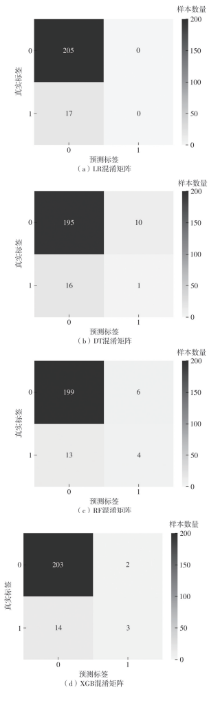
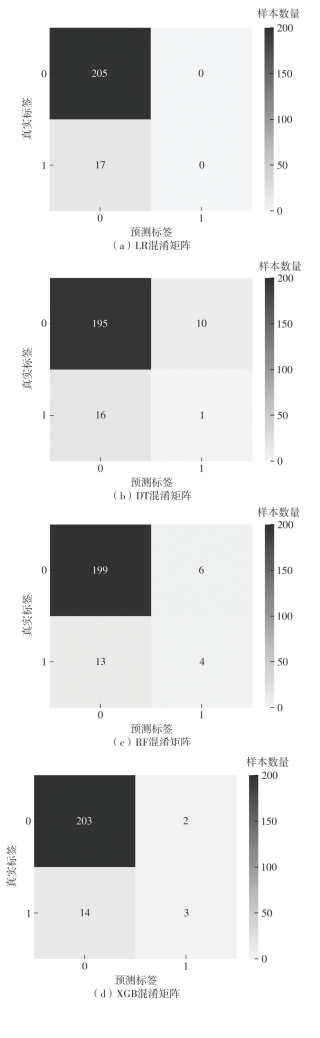
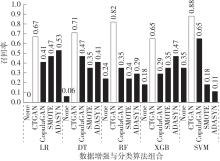
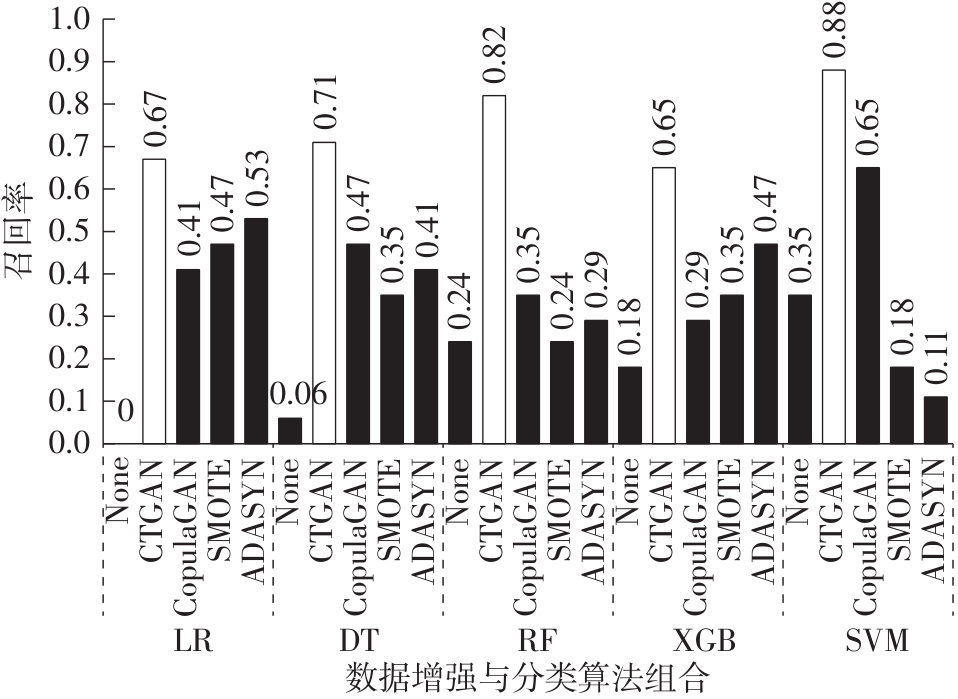
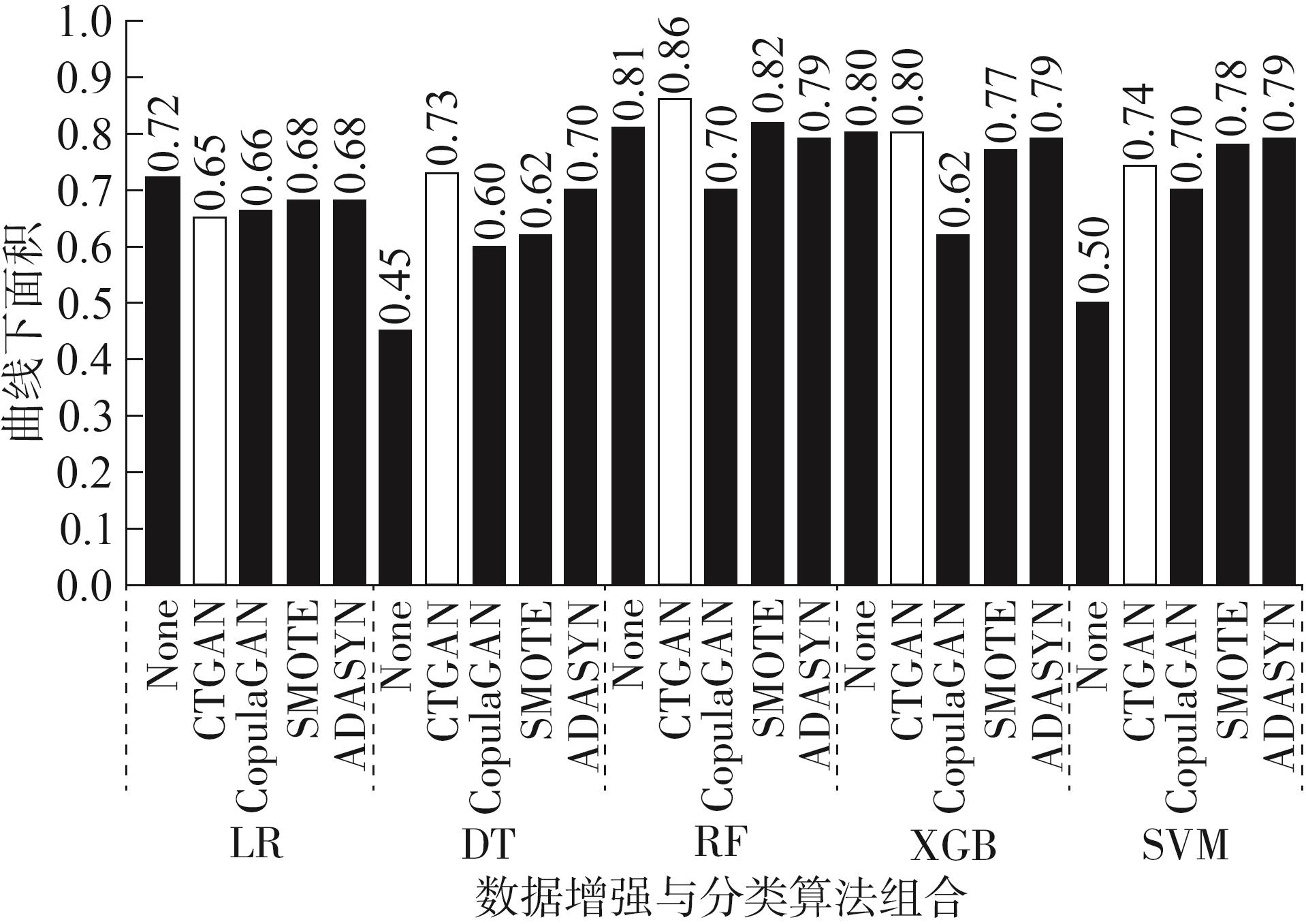
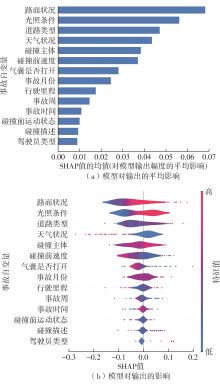
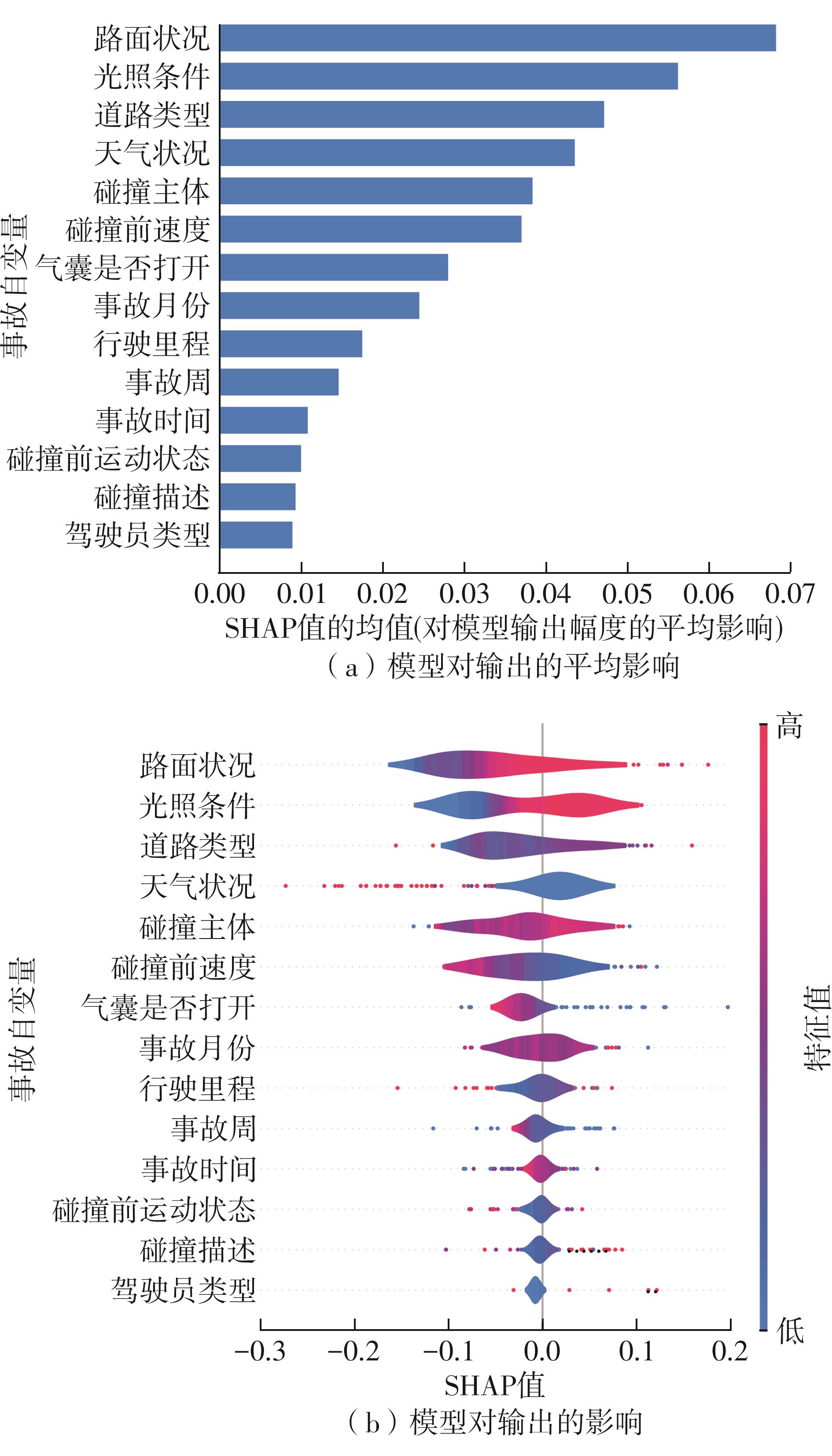
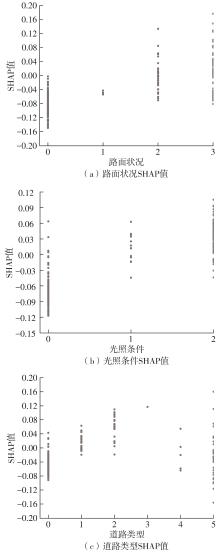
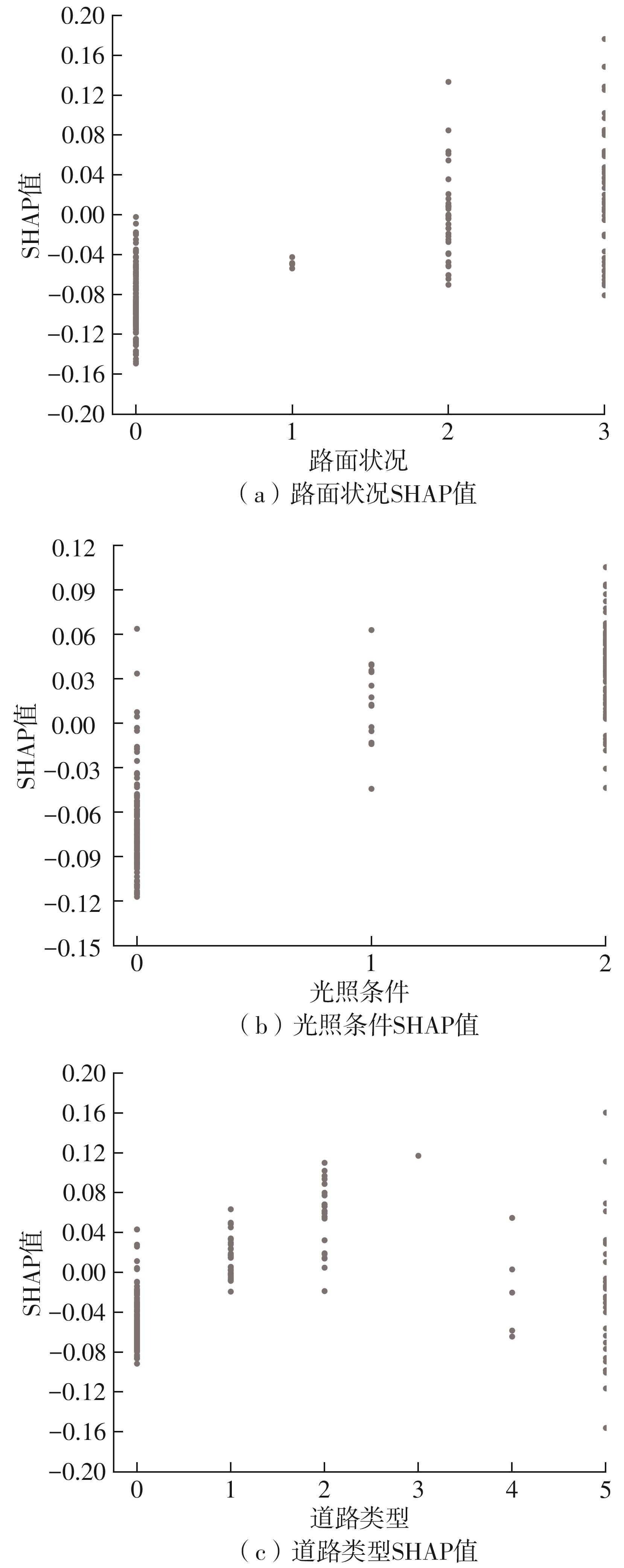
| [1] |
KUO P F, HSU W T, LORD D,et al .Classification of autonomous vehicle crash severity:solving the pro-blems of imbalanced datasets and small sample size[J].Accident Analysis & Prevention,2024,205:107666/1-13.
|
| [2] |
MEASE D, WYNER A J, BUJA A .Boosted classification trees and class probability/quantile estimation[J].Journal of Machine Learning Research,2007,8:409-439.
|
| [3] |
HE H, GARCIA E A .Learning from imbalanced data[J].IEEE Transactions on Knowledge and Data Engineering,2009,21(9):1263-1284.
|
| [4] |
HE H, BAI Y, GARCIA E A,et al .ADASYN:adaptive synthetic sampling approach for imbalanced learning[C]∥ Proceeding of 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence).Hong Kong:IEEE,2008:1322-1328.
|
| [5] |
BARUA S, ISLAM M M, YAO X,et al .MWMOTE-majority weighted minority oversampling technique for imbalanced data set learning[J].IEEE Transactions on Knowledge and Data Engineering,2012,26(2):405-425.
|
| [6] |
TANG B, HE H .KernelADASYN:Kernel based adaptive synthetic data generation for imbalanced learning[C]∥ Proceeding of 2015 IEEE Congress on Evolutionary Computation (CEC).Sendai:IEEE,2015:664-671.
|
| [7] |
ZHU S. Analysis of the severity of vehicle-bicycle crashes with data mining techniques[J].Journal of Safety Research,2020,76:218-227.
|
| [8] |
CAI Q, ABDEL-ATY M, YUAN J,et al .Real-time crash prediction on expressways using deep generative models[J].Transportation Research Part C:Emerging Technologies,2020,117:102697/1-14.
|
| [9] |
MIRZA M, OSINDERO S .Conditional generative adversarial nets[J].arXiv preprint arXiv:,2014.
|
| [10] |
RADFORD A, METZ L, CHINTALA S .Unsupervised representation learning with deep convolutional generative adversarial networks[J].arXiv preprint arXiv:,2015.
|
| [11] |
ARJOVSKY M, CHINTALA S .Bottou. Wasserstein GAN[J].arXiv preprint arXiv:,2017.
|
| [12] |
ZHOU D, ZHANG H, LI Q,et al .Coutfitgan:learning to synthesize compatible outfits supervised by silhouette masks and fashion styles[J].IEEE Tran-sactions on Multimedia,2022,25(1):4986-5001.
|
| [13] |
ZHOU D, ZHANG H, YANG K,et al .Learning to synthesize compatible fashion items using semantic alignment and collocation classification:an outfit ge-neration framework[J].IEEE Transactions on Neural Networks and Learning Systems,2022,35(4):5226-5240.
|
| [14] |
FIORE U, DE SANTIS A, PERLA F,et al .Using generative adversarial networks for improving classification effectiveness in credit card fraud detection[J].Information Sciences, 2019,479:448-455.
|
| [15] |
ZHANG H, YU X, REN P,et al .Deep adversarial learning in intrusion detection:a data augmentation enhanced framework[J].arXiv preprint arXiv:,2019.
|
| [16] |
LI Y, YANG Z, XING L .Crash injury severity prediction considering data imbalance:a wasserstein ge-nerative adversarial network with gradient penalty approach[J].Accident Analysis & Prevention,2023,192:107271/1-18.
|
| [17] |
ZHOU B, ZHOU Q, LI Z .Addressing data imba-lance in crash data: evaluating generative adversarial network’s efficacy against conventional methods[J].IEEE Access,2025,13:2929-2944.
|
| [18] |
MUJALLI R O, LÓPEZ G, GARACH L .Bayes classifiers for imbalanced traffic accidents datasets[J].Accident Analysis & Prevention,2016,88:37-51.
|
| [19] |
SAVOLAINEN P T, MANNERING F L, LORD D,et al .The statistical analysis of highway crash-injury severities:a review and assessment of methodological alternatives[J].Accident Analysis & Prevention,2011,43(5):1666-1676.
|
| [20] |
ALKHEDER S, ALRUKAIBI F, AIASH A .Risk analysis of traffic accidents’severities:an application of three data mining models[J].ISA Transactions,2020,106:213-220.
|
| [21] |
WEN X, XIE Y, WU L,et al .Quantifying and comparing the effects of key risk factors on various types of roadway segment crashes with LightGBM and SHAP[J].Accident Analysis & Prevention,2021,159:106261/1-11.
|
| [22] |
DONG S, KHATTAK A, ULLAH I,et al .Predicting and analyzing road traffic injury severity using boosting-based ensemble learning models with SHAPley Additive exPlanations[J].International Journal of Environmental Research and Public Health,2022,19(5):2925/1-23.
|
| [23] |
WANG H, WANG X, HAN J,et al .A recognition method of aggressive driving behavior based on ensemble learning[J].Sensors,2022,22(2):644/1-24.
|
| [24] |
WU N, SUN J .Fatigue detection of air traffic controllers based on radiotelephony communications and self-adaption quantum genetic algorithm optimization ensemble learning[J].Applied Sciences,2022,12(20):10252.
|
| [25] |
IMRAN M, MAHMOOD A M, QYSER A A M .An empirical experimental evaluation on imbalanced data sets with varied imbalance ratio[C]∥ Proceeding of International Conference on Computing and Communication Technologies.Chengdu:IEEE,2014:1-7.
|
| [26] |
XU L, SKOULARIDOU M, CUESTA-INFANTE A,et al .Modeling tabular data using conditional gan[J].Advances in Neural Information Processing Systems,2019,659:7335-7345.
|
| [27] |
BOUROU SEL SAER A, VELIVASSAKI T H,et al .A review of tabular data synthesis using gans on an ids dataset[J].Information,2021,12(9):375.
|
| [28] |
ZHENG O, ABDEL-ATY M, WANG Z,et al .Avoid:autonomous vehicle operation incident dataset across the globe[J].arXiv preprint arXiv:2303.12889,2023.
|
| [29] |
DAS P, CHANDA K .Bayesian Network based modeling of regional rainfall from multiple local meteorological drivers[J].Journal of Hydrology,2020,591:125563/1-17.
|
| [30] |
DING S, ABDEL-ATY M, WANG D,et al .Exploratory analysis of injury severity under different levels of driving automation (SAE Level 2-5) using multi-source data[J].arXiv preprint arXiv:,2023.
|
| [31] |
LIU P, GUO Y, LIU P,et al .What can we learn from the AV crashes?—an association rule analysis for identifying the contributing risky factors[J].Accident Analysis & Prevention,2024,199:107492/1-12.
|
| [32] |
KHAN M Q, LEE S .A comprehensive survey of dri-ving monitoring and assistance systems[J].Sensors,2019,19(11):2574/1-32.
|
| [33] |
LI J, LI B, TU Z,et al .Light the night:a multi-condition diffusion framework for unpaired low-light Enhancement in Autonomous Driving[C]∥ Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville:IEEE,2024: 15205-15215.
|
| [34] |
LI X, LIN K Y, MENG M,et al .A survey of ADAS perceptions with development in China[J].IEEE Transactions on Intelligent Transportation Systems,2022,23(9):14188-14203.
|