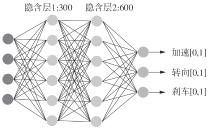
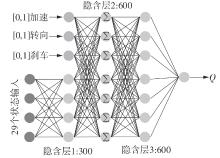
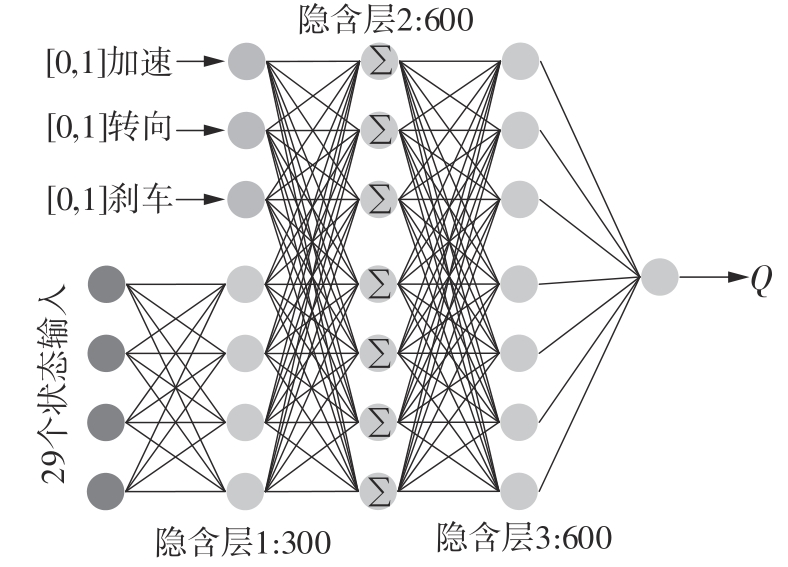
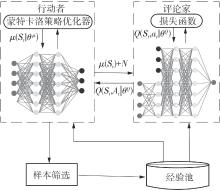
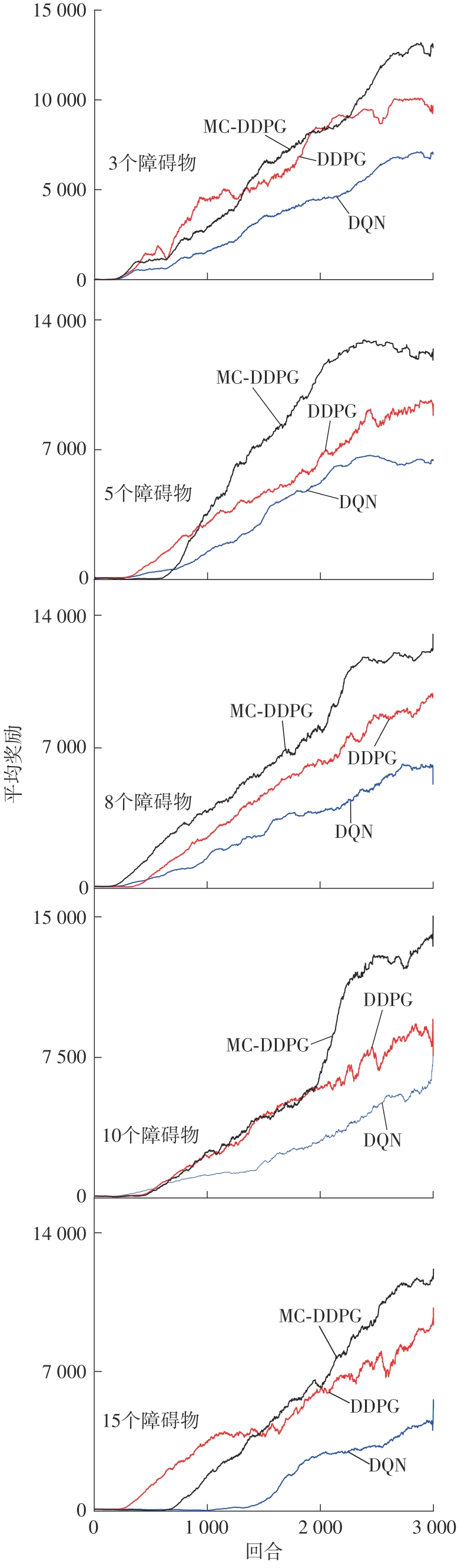
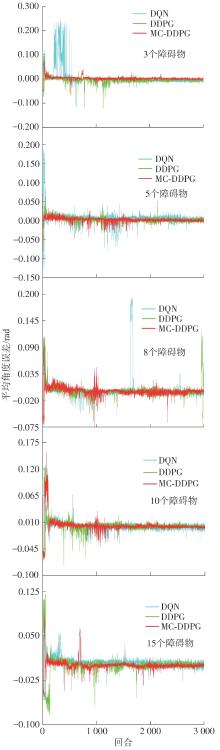
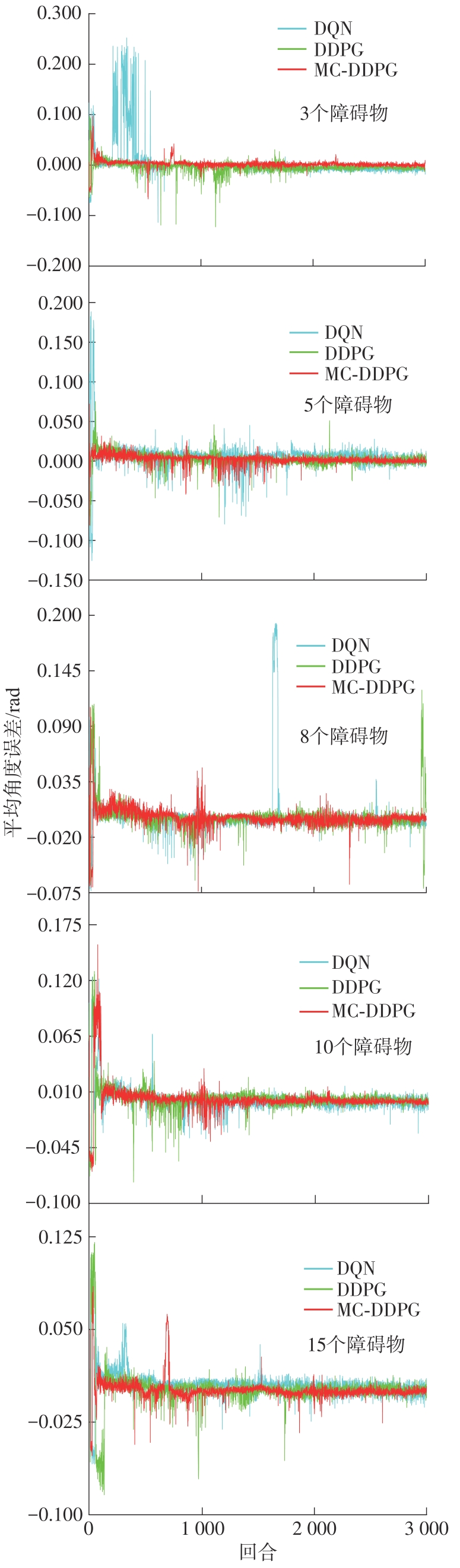
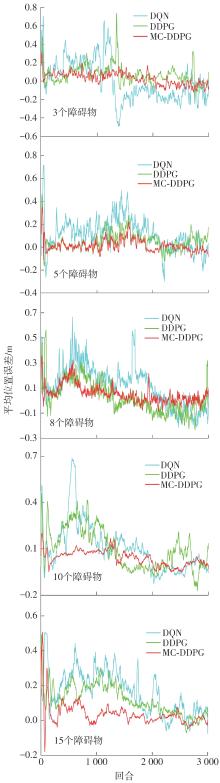
| 1 |
JAN B, FARMAN H, KHAN M .Designing a smart transportation system:an internet of things and big data approach[J].IEEE Wireless Communications,2019,26(4):73-79.
|
| 2 |
徐向阳,胡文浩,董红磊 .自动驾驶汽车测试场景构建关键技术综述[J].汽车工程,2021,43(4):610-619.
|
|
XU Xiangyang, HU Wenhao, DONG Honglei .Overview of key technologies for autonomous vehicle test scenario construction[J].Automotive Engineering,2021,43(4):610-619.
|
| 3 |
熊璐,杨兴,卓桂荣,等 .无人驾驶车辆的运动控制发展现状综述[J].机械工程学报,2020,56(10):127-143.
|
|
XIONG Lu, YANG Xing, ZHUO Guirong,et al .Overview on motion control of autonomous vehicles[J].Journal of Mechanical Engineering,2020,56(10):127-143.
|
| 4 |
ZHANG X L, ZHANG W X, ZHAO Y Q .Personalized motion planning and tracking control for autonomous vehicles obstacle avoidance[J].IEEE Transactions on Vehicular Technology,2022,71(5):4733-4747.
|
| 5 |
于向军,槐元辉,姚宗伟 .工程车辆无人驾驶关键技术[J].吉林大学学报(工学版),2021,51(4):1153-1168.
|
|
YU Xiang-jun, KUI Yuan-hui, YAO Zong-wei .Key technologies in autonomous vehicle for engineering[J].Journal of Jilin University(Engineering and Technology Edition),2021,51(4):1153-1168.
|
| 6 |
GRUYER D, MAGNIER V, HAMDI K,et al .Perception information processing and modeling:critical stages for autonomous driving applications[J].Annual Reviews in Control,2017,41(10):323-341.
|
| 7 |
张家旭,杨雄,施正堂,等 .汽车紧急换道避障的路径规划与跟踪控制[J].华南理工大学学报(自然科学版),2020,48(9):86-93,106.
|
|
ZHANG Jiaxu, YANG Xiong, SHI Zhengtang,et al .Path planning and tracking control for emergency lane change and obstacle avoidance of vehicles[J].Journal of South China University of Technology (Natural Science Edition),2020,48(9):86-93,106.
|
| 8 |
WANG T, JIANG J F, LIN Y T,et al .Driver model for obstacle avoidance based on CarSim[J].Transactions of the Chinese Society of Agricultural Engineering,2010,26(5):159-163.
|
| 9 |
樊晓平,李双艳,陈特放 .基于新人工势场函数的机器人动态避障规划[J].控制理论与应用,2005,22(5):703-707.
|
|
FAN Xiao-ping, LI Shuang-yan, CHEN Te-fang .Dynamic obstacle-avoiding path plan for robots based on a new artificial potential field function[J].Control Theory & Applications,2005,22(5):703-707.
|
| 10 |
KATSUKI R, TASAKI T, WATANABE T .Graph search based local path planning with adaptive node sampling[C]∥ Proceedings of 2018 IEEE Intelligent Vehicles Symposium.Changshu:IEEE,2018:2084-2089.
|
| 11 |
WANG Hong-chao, ZHANG Wei-wei, WU Xun-cheng,et al .A double-layer nonlinear model predictive control based control algorithm for local trajectory planning for automated trucks under uncertain road adhesion coefficient conditions[J].Frontiers of Information Technology & Electronic Engineering,2020,21(7):1059-1074.
|
| 12 |
ZONG C G, JI Z J, YU Y,et al .Research on obstacle avoidance method for mobile robot based on multisensor information fusion[J].Sensors and Materials,2020,32(4):1159-1170.
|
| 13 |
YANG Z C, FENG Y T, ZHANG L X,et al .Obstacle avoidance control of underactuated robot based on neural network feedforward compensation[J].Measurement & Control Technology,2017,36(11):89-97.
|
| 14 |
姚强强,田颖,王圣渊,等 .基于力驱动的智能汽车路径跟踪控制策略[J].华南理工大学学报(自然科学版),2022,50(2):33-41,57.
|
|
YAO Qiangqiang, TIAN Ying, WANG Shengyuan,et al .Research on path tracking control strategy of intelligent vehicles based on force drive[J].Journal of South China University of Technology (Natural Science Edition),2022,50(2):33-41,57.
|
| 15 |
SALLAB A E, ABDOU M, PEROT E,et al .Deep reinforcement learning framework for autonomous driving[J].Electronic Imaging,2017,29(19):70-76.
|
| 16 |
卢笑,竺一薇,阳牡花,等 .联合图像与单目深度特征的强化学习端到端自动驾驶决策方法[J].武汉大学学报(信息科学版),2021,46(12):1862-1871.
|
|
LU Xiao, ZHU Yiwei, YANG Muhua,et al .Reinforcement learning based end-to-end autonomous driving decision-making method by combining image and monocular depth features[J].Geomatics and Information Science of Wuhan University,2021,46(12):1862-1871.
|
| 17 |
张守武,王恒,陈鹏,等 .神经网络在无人驾驶车辆运动控制中的应用综述[J].工程科学学报,2022,44(2):235-243.
|
|
ZHANG Shou-wu, WANG Heng, CHEN Peng,et al .Overview of the application of neural networks in the motion control of unmanned vehicles[J].Chinese Journal of Engineering,2022,44(2):235-243.
|
| 18 |
董豪,杨静,李少波,等 .基于深度强化学习的机器人运动控制研究进展[J].控制与决策,2022,37(2):278-292.
|
|
DONG Hao, YANG Jing, LI Shao-bo,et al .Research progress of robot motion control based on deep reinforcement learning[J].Control and Decision,2022,37(2):278-292.
|
| 19 |
WANG Y P, ZHENG K X, TIAN D X,et al .Asynchronous supervised learning pre-training methods for reinforcement learning autonomous driving models[J].Frontiers of Information Technology & Electronic Engineering,2021,22(5):673-687.
|
| 20 |
吕帅,龚晓宇,张正昊,等 .结合进化算法的深度强化学习方法研究综述[J].计算机学报,2022,45(7):1478-1499.
|
|
Shuai LÜ, GONG Xiao-yu, ZHANG Zheng-hao,et al .Survey of deep reinforcement learning methods with evolutionary algorithms[J].Chinese Journal of Computers,2022,45(7):1478-1499.
|
| 21 |
张新钰,高洪波,赵建辉,等 .基于深度学习的自动驾驶技术综述[J].清华大学学报(自然科学版),2018,58(4):438-444.
|
|
ZHANG Xinyu, GAO Hongbo, ZHAO Jianhui,et al .Overview of deep learning intelligent driving methods [J].Journal of Tsinghua University (Science and Technology),2018,58(4):438-444.
|
| 22 |
陈红名,刘全,闫岩,等 .基于经验指导的深度确定性多行动者-评论家算法[J].计算机研究与发展,2019,56(8):1708-1720.
|
|
CHEN Hongming, LIU Quan, YAN Yan,et al .An experience-guided deep deterministic actor-critic algorithm with multi-actor[J].Journal of Computer Research and Development,2019,56(8):1708-1720.
|
| 23 |
陈亮,梁宸,张景异,等 .Actor-Critic框架下一种基于改进DDPG的多智能体强化学习算法[J].控制与决策,2021,36(1):75-82.
|
|
CHEN Liang, LIANG Chen, ZHANG Jing-yi,et al .A multi-intelligence reinforcement learning algorithm based on improved DDPG in the Actor-Critic framework[J].Control and Decision,2021,36(1):75-82.
|