华南理工大学学报(自然科学版) ›› 2024, Vol. 52 ›› Issue (10): 41-50.doi: 10.12141/j.issn.1000-565X.230673
所属专题: 2024年计算机科学与技术
基于语义-视觉一致性约束的零样本图像语义分割网络
陈琼( ), 冯媛, 李志群, 杨咏
), 冯媛, 李志群, 杨咏
- 华南理工大学 计算机科学与工程学院,广东 广州 510006
Semantic-Visual Consistency Constraint Network for Zero-Shot Image Semantic Segmentation
CHEN Qiong(), FENG Yuan, LI Zhiqun, YANG Yong
- School of Computer Science and Engineering,South China University of Technology,Guangzhou 510006,Guangdong,China
摘要:
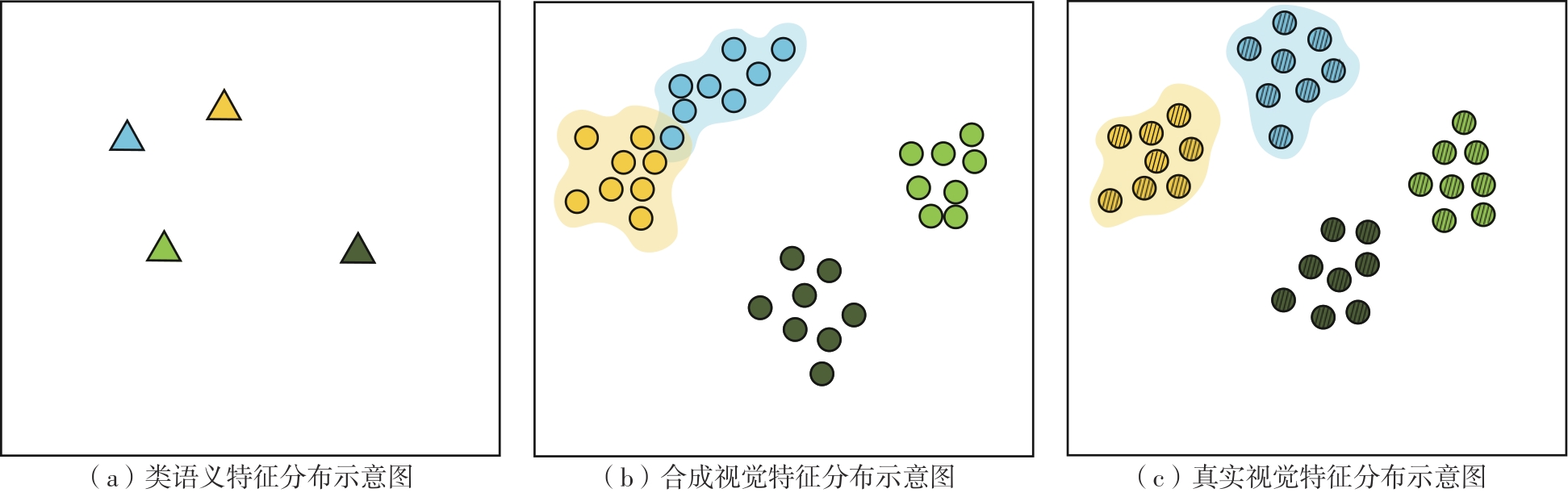
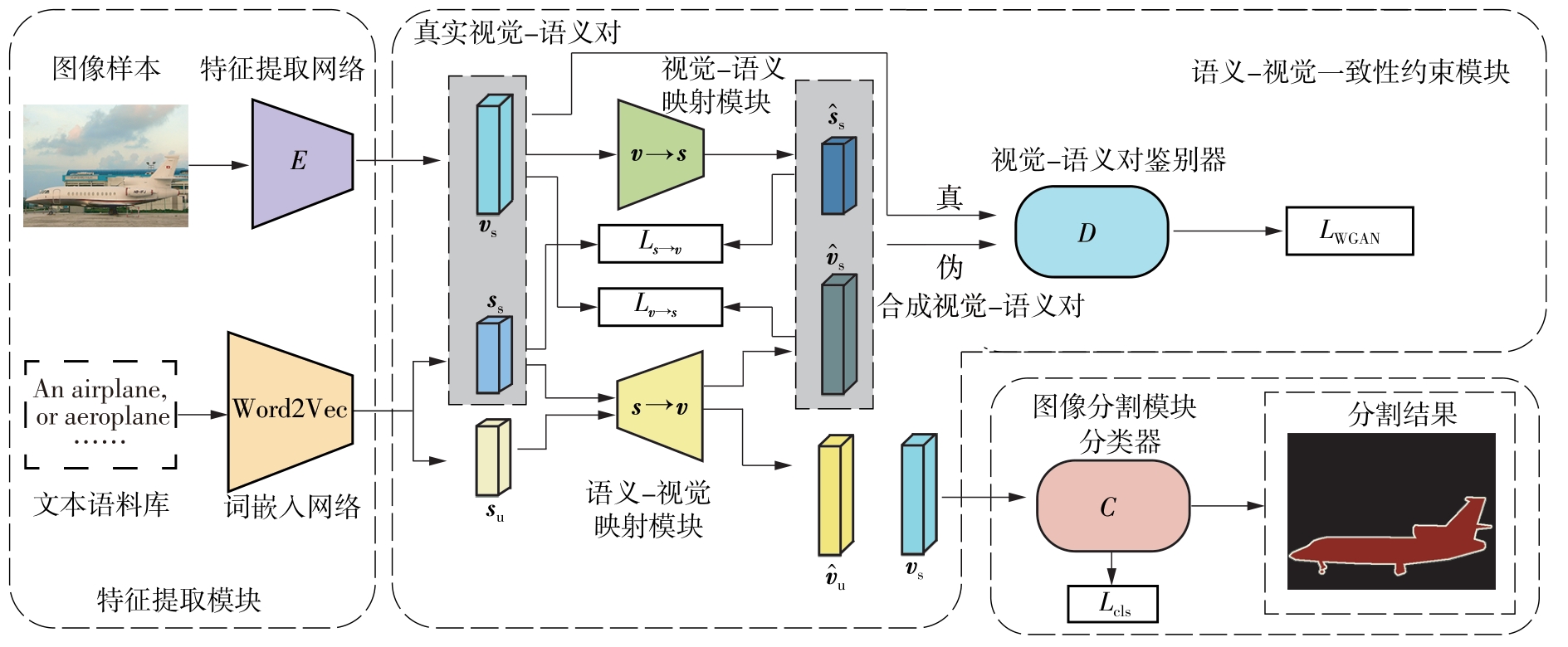
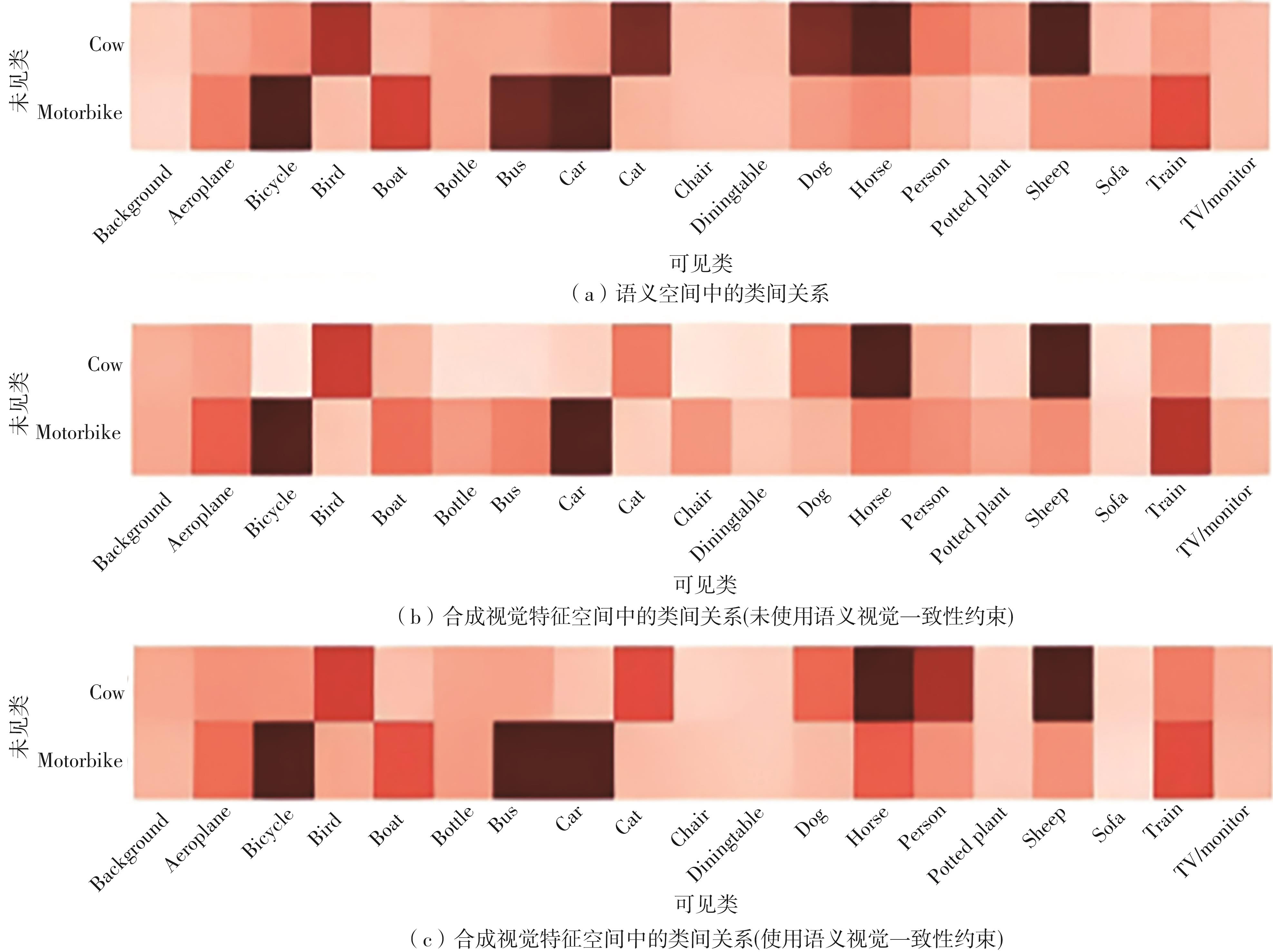
零样本图像语义分割是零样本学习在视觉领域的重要任务之一,旨在分割训练中未见的新类别。目前基于像素级视觉特征生成的方法合成的视觉特征分布和真实的视觉特征分布存在不一致性的问题,合成的视觉特征难以准确反映类语义信息,导致合成的视觉特征缺乏鉴别性;现有的一些视觉特征生成方法为了得到语义特征所表达的区分性信息,需要消耗巨大的计算资源。为此,文中提出了一种基于语义-视觉一致性约束的零样本图像语义分割网络(SVCCNet)。该网络通过语义-视觉一致性约束模块对语义特征与视觉特征进行相互转换,以提高两者的关联度,减小真实视觉特征与合成视觉特征空间结构的差异性,从而缓解合成视觉特征与真实视觉特征分布不一致的问题。语义-视觉一致性约束模块通过两个相互约束的重建映射,实现了视觉特征与类别语义的对应关系,同时保持了较低的模型复杂度。在PASCAL-VOC及PASCAL-Context数据集上的实验结果表明,SVCCNet的像素准确率、平均准确率、平均交并比、调和交并比均优于比较的主流方法。
中图分类号: