华南理工大学学报(自然科学版) ›› 2025, Vol. 53 ›› Issue (3): 20-30.doi: 10.12141/j.issn.1000-565X.240035
基于Matrix Core的高性能多维FFT设计与优化
陆璐1,2( ), 祝松祥1, 田卿燕3, 林海山3, 郭逸劼1
), 祝松祥1, 田卿燕3, 林海山3, 郭逸劼1
- 1.华南理工大学 计算机科学与工程学院,广东 广州 510006
2.鹏城实验室,广东 深圳 518000
3.广东省隧道工程安全与应急保障技术及装备企业重点实验室,广东 广州 510440
Design and Optimization of High-Performance Multi-Dimensional FFT Based on Matrix Core
LU Lu1,2(), ZHU Songxiang1, TIAN Qingyan3, LIN Haishan3, GUO Yijie1
- 1.School of Computer Science and Engineering,South China University of Technology,Guangzhou 510006,Guangdong,China
2.Pengcheng Laboratory,Shenzhen 518000,Guangdong,China
3.Tunnel Engineering Safety and Emergency Support Technology and Equipment Laboratory of Guangdong Province,Guangzhou 510440,Guangdong,China
摘要:
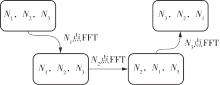
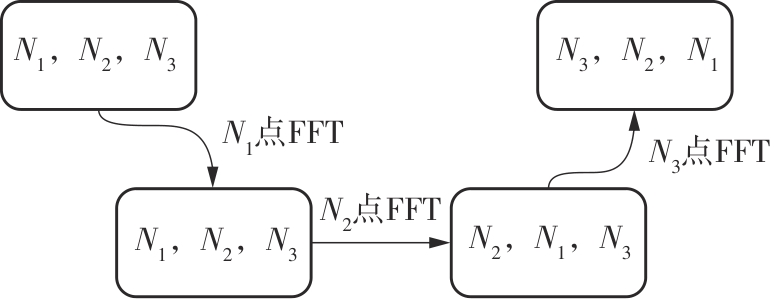
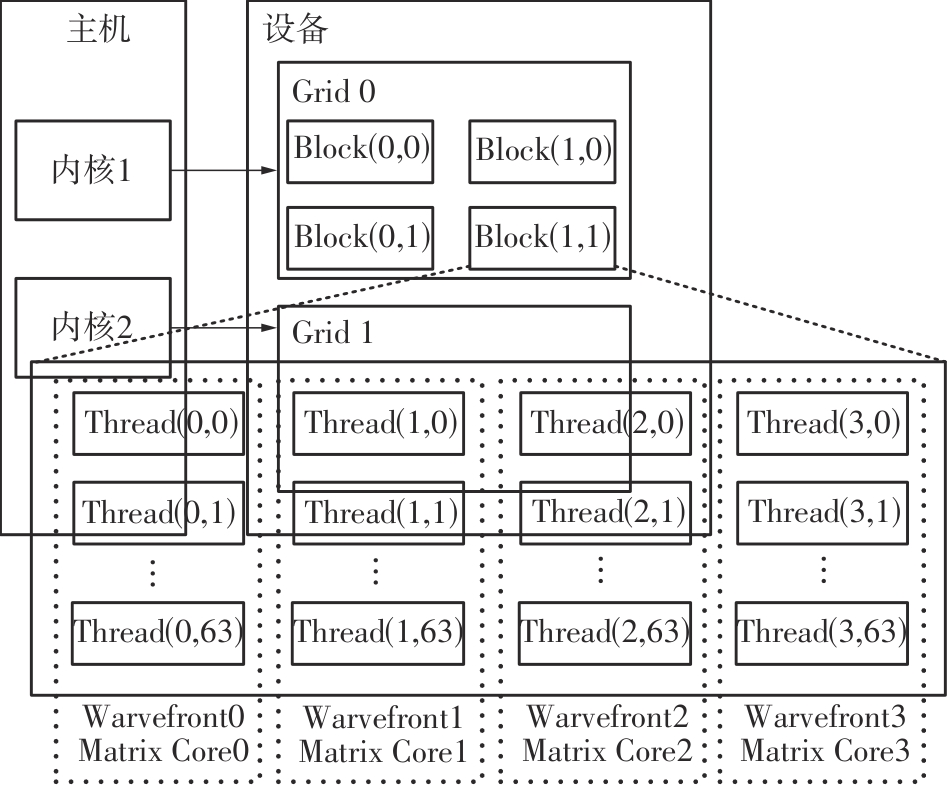
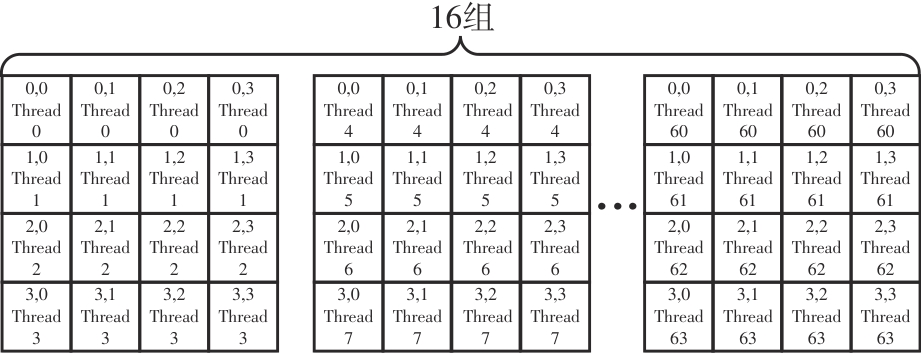
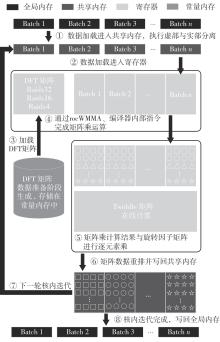
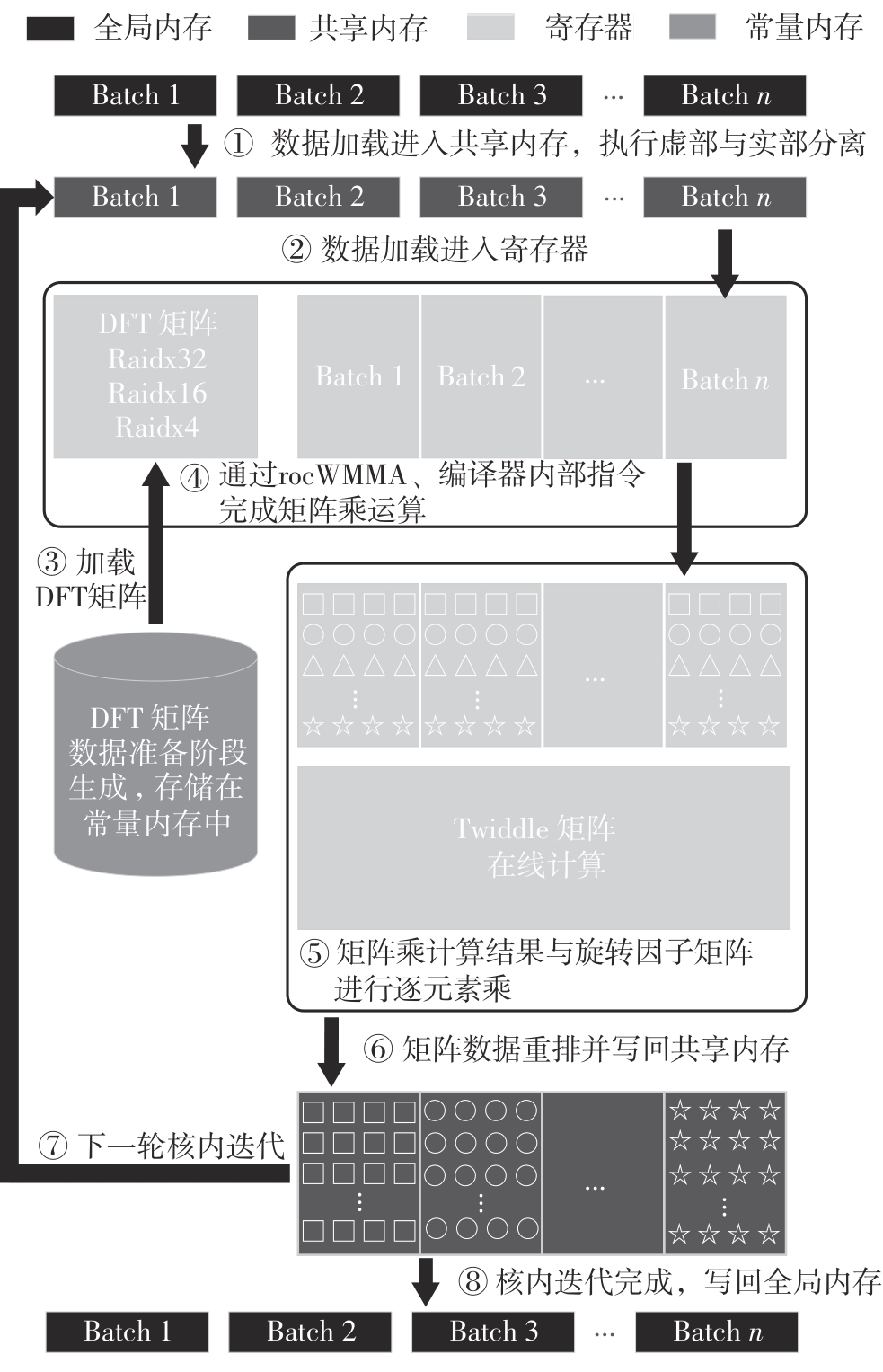
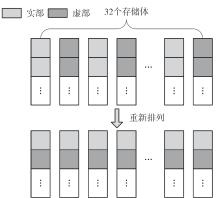
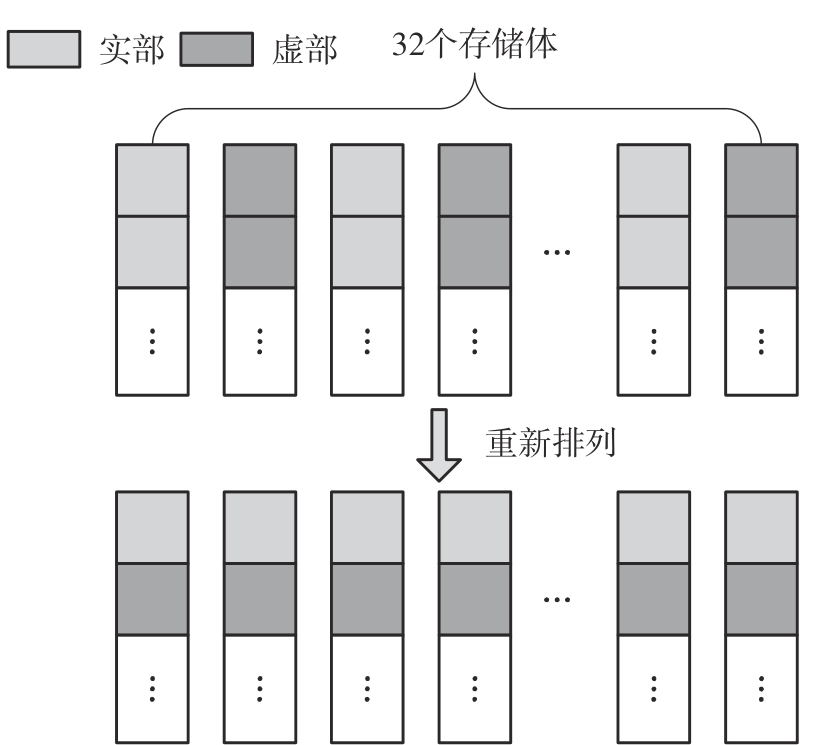
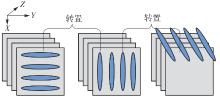
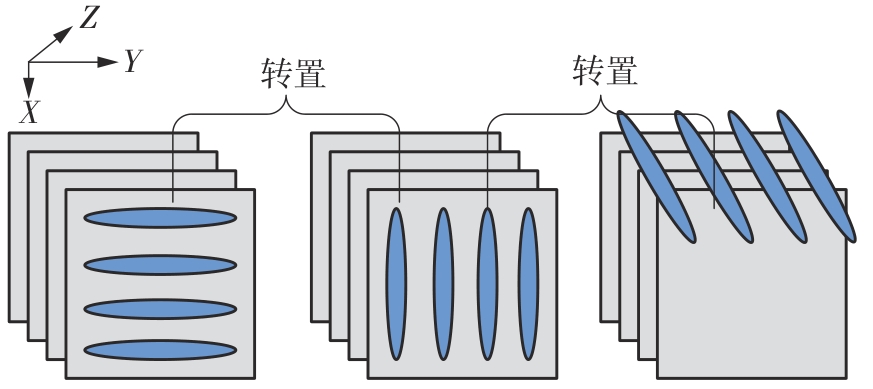
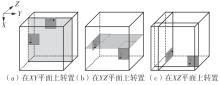
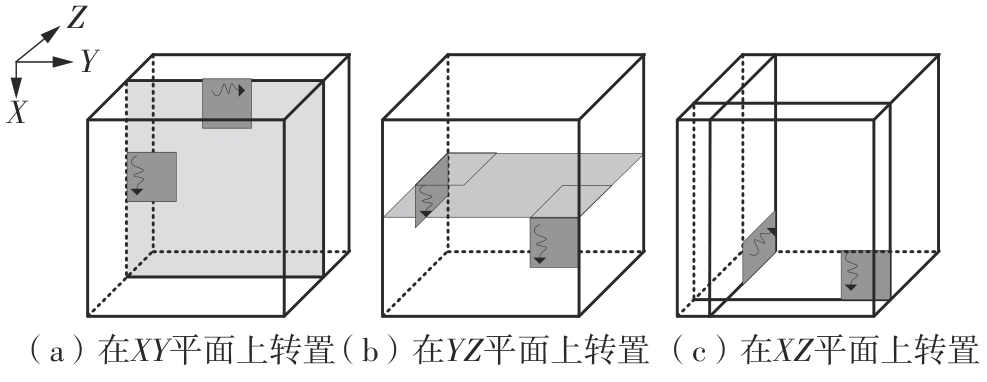
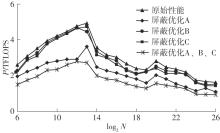
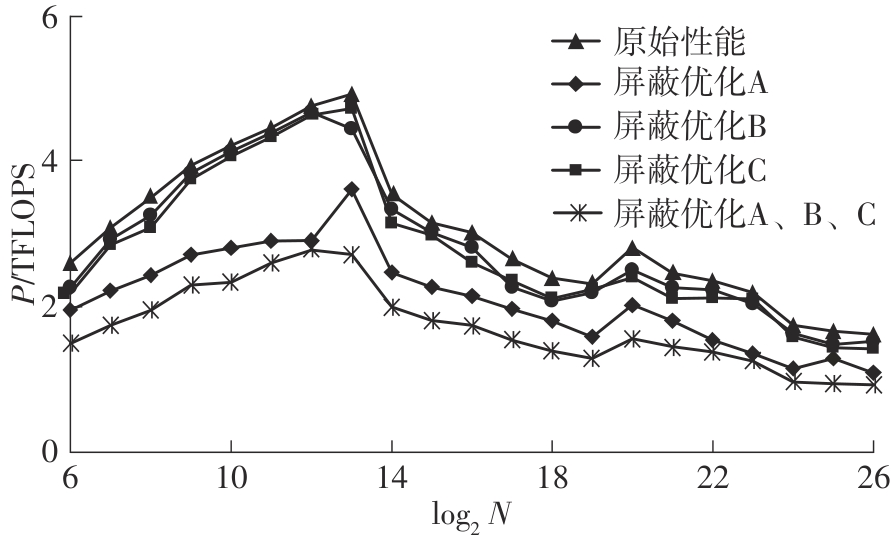
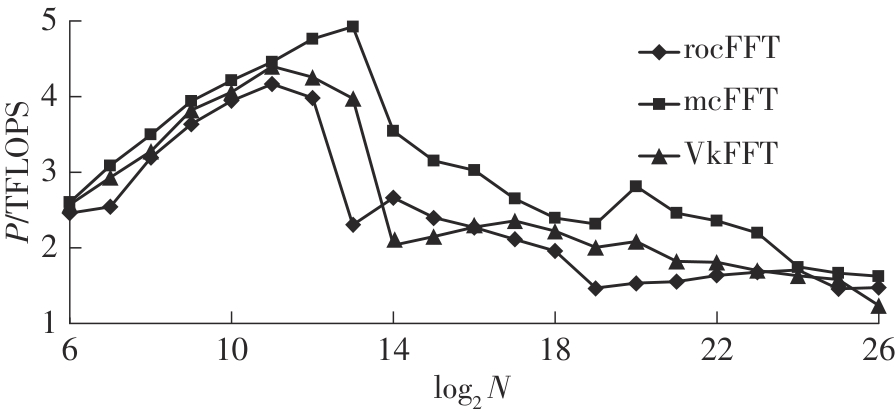
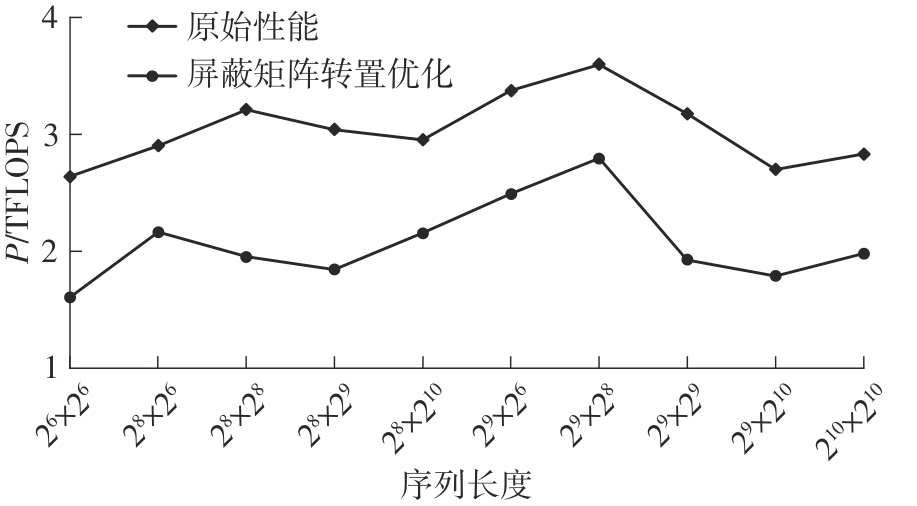
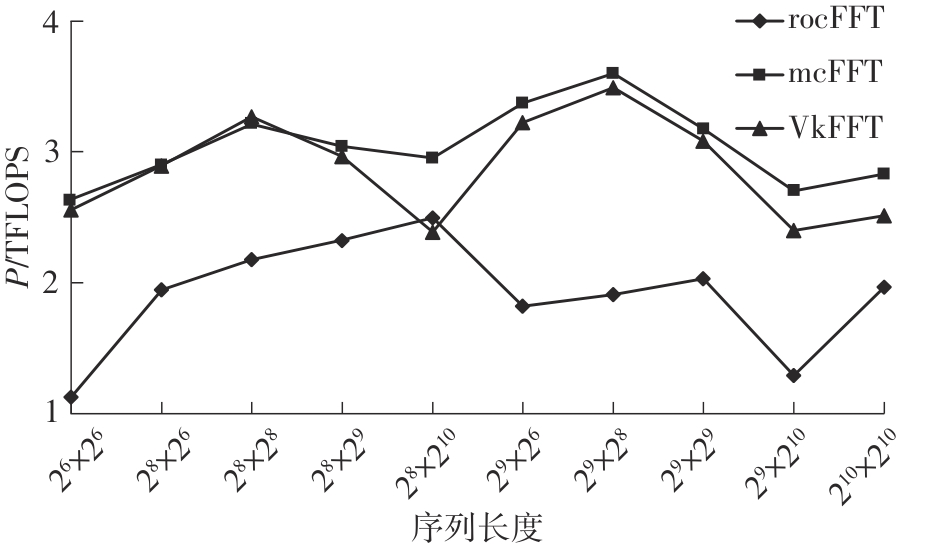
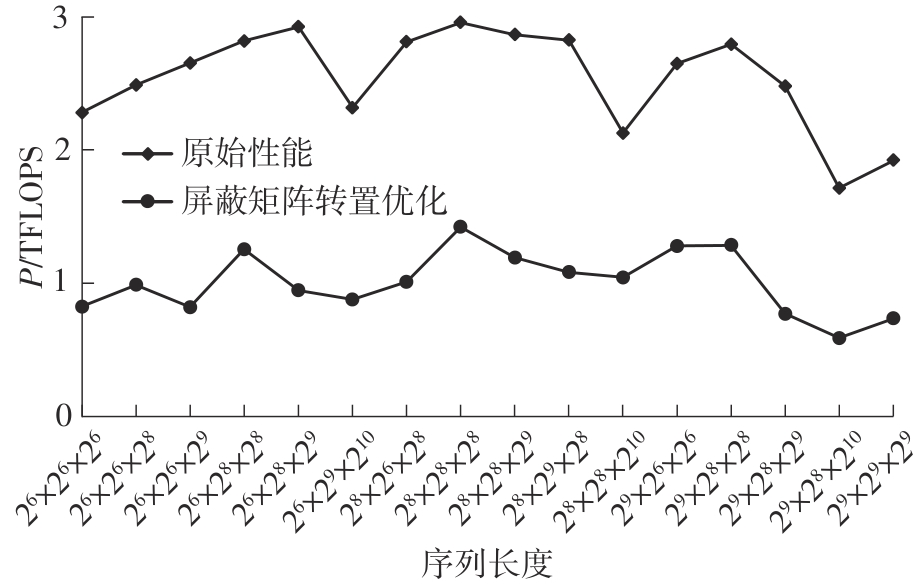
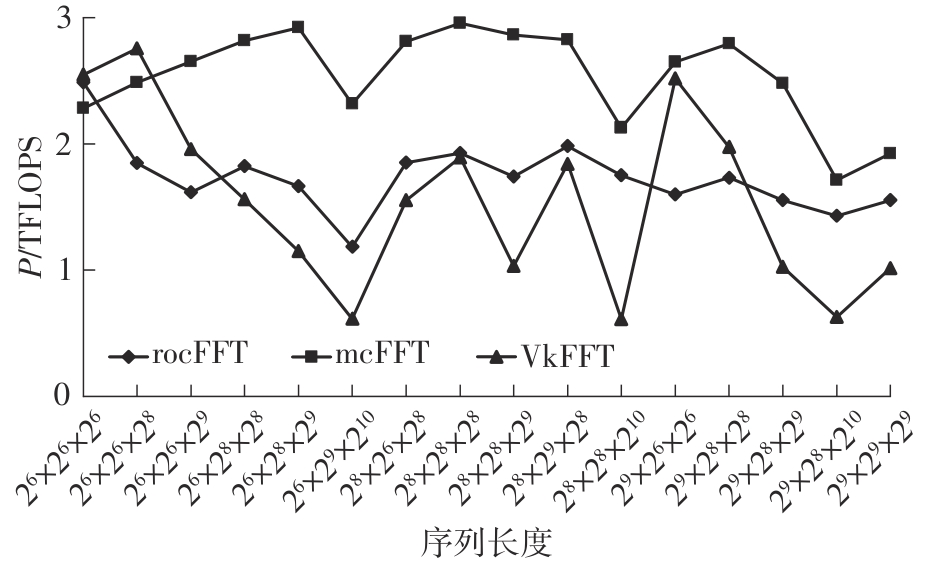
快速傅里叶变换(FFT)算法广泛应用于科学计算等领域。为了充分挖掘图形处理器(GPU)的计算能力并进一步提高FFT的计算效率,该文针对矩阵形式的Stockham FFT,提出了一种基于Matrix Core的高性能多维FFT计算方案。在计算优化方面,该方案利用Matrix Core加速FFT计算中的矩阵乘运算,同时通过编译器内部指令完成小粒度的矩阵乘加,使得Matrix Core支持更多尺寸的FFT计算。在内存优化方面,该方案使用2层迭代策略,以充分利用共享内存,减少与全局内存的数据交换;根据Matrix Core的矩阵数据在各个线程寄存器中的分布规律,直接在寄存器上完成FFT计算中大量存在的矩阵逐元素乘操作;通过对共享内存中的数据进行重排来缓解存储体冲突,并采用双缓冲策略缓解访存瓶颈。该文还提出了高效的矩阵转置策略,以加速多维FFT计算。在AMD MI250 GPU平台上将该方案与GPU上主流的高性能FFT计算库rocFFT和VkFFT进行了比较实验,结果表明:该方案在AMD MI250上的1维、2维和3维FFT平均计算效率均优于rocFFT和VkFFT,3维FFT的平均计算效率为rocFFT的1.5倍,为VkFFT的2.0倍,具有较好的性能提升;mcFFT的计算精度与rocFFT和VkFFT保持在相同水平。
中图分类号: