
收稿日期: 2025-03-18
网络出版日期: 2025-05-23
基金资助
天津市自然科学基金项目(23JCZDJC00020)
3D Hand Pose Estimation with Multimodal Feature Fusion Guided by Depth Geometric Features
Received date: 2025-03-18
Online published: 2025-05-23
Supported by
the Natural Science Foundation of Tianjin,China(23JCZDJC00020)
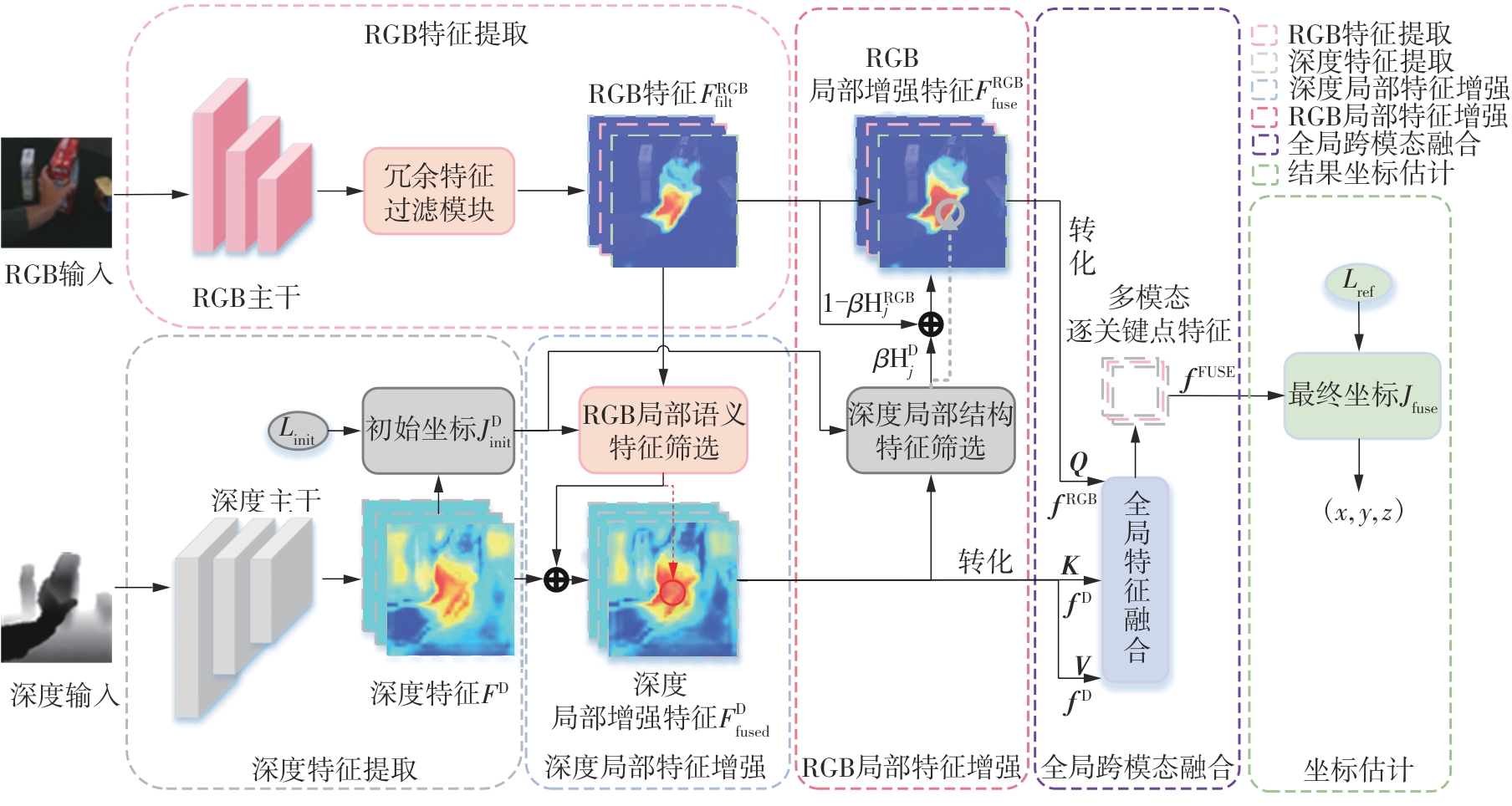
由于数据采集质量不稳定,在3D手部姿态估计任务中,仅使用单一的RGB(红绿蓝)或深度图像往往会导致关键特征的缺失。相比之下,结合两者语义和结构优势的多模态方法更具鲁棒性。然而,现有多模态手部姿态估计方法在融合RGB和深度特征时,仍面临信息冗余、模态对齐误差及局部特征缺失等问题,影响了关键点定位的精度与稳定性。鉴于此,该文提出一种基于深度几何特征引导的多模态关键点特征增强与融合方法。首先,利用深度结构特征表征手部轮廓和几何信息,以初步估计关键点位置。然后,引导选取对应RGB模态信息的局部增强深度模态特征,弥补深度模态因空洞和遮挡而引起的结构特征缺失。进一步地,采用关键点局部深度三维结构特征来局部增强初始RGB特征,提升RGB模态对手部三维空间结构的理解能力。最后,通过全局跨模态注意力机制进行交互学习,使局部增强的深度与RGB特征在全局范围内对齐,并动态优化模态信息的互补性。与现有的主流深度学习方法相比,该方法在DexYCB、HO-3D和InterHand2.6M数据集上分别达到了7.52、1.80和7.40 mm的最低误差。
关欣 , 刘晨曦 , 李锵 . 深度几何特征引导多模态特征融合的3D手部姿态估计[J]. 华南理工大学学报(自然科学版), 2025 , 53(11) : 37 -51 . DOI: 10.12141/j.issn.1000-565X.250072
Owing to the inherent instability in data acquisition quality, the reliance on either RGB or depth images alone in 3D hand pose estimation tasks frequently results in the loss of critical features. In contrast, multimodal approaches that integrate the complementary semantic and structural strengths of both modalities exhibit significantly enhanced robustness. However, existing multimodal 3D hand pose estimation methods face significant challenges in effectively fusing RGB and depth information, primarily due to issues of feature redundancy, modality misalignment, and the loss of local features. These limitations significantly degrade the accuracy and stability of keypoint localization. To address these challenges, this paper proposes a depth feature-guided multimodal keypoint feature enhancement and fusion method. In this method, first, depth structural features are leveraged to capture hand contour and geometric information, thus providing an initial estimation of keypoint positions. Subsequently, RGB modal information is employed to locally enhance depth features, thus effectively addressing the inherent limitations of depth modal in capturing structural features being lost due to voids and occlusions. Furthermore, a framework integrating the localized depth-based 3D structural features of keypoint is proposed to refine the initial RGB features, thus enhancing the spatial structure understanding of the hand in the RGB modal. To optimize the fusion process, a global cross-modal attention mechanism is introduced to facilitate interactive learning, thus ensuring the global alignment of locally enhanced depth and RGB features while dynamically enhancing the complementarity between modalities. Compared with existing mainstream deep learning methods, the proposed approach helps to achieve the lowest errors of 7.52, 1.80 and 7.40 mm on DexYCB, HO-3D and InterHand2.6M datasets, respectively.
| [1] | ROUMAISSA B, MOHAMED C B .Deep learning based on hand pose estimation methods:a systematic literature review[J].Multimedia Tools and Applications,2025,84(3):1-38. |
| [2] | BEHúN K, PAVELKOVá A, HEROUT A .Implicit hand gestures in aeronautics cockpit as a cue for crew state and workload inference[C]∥Proceedings of 2015 IEEE 18th International Conference on Intelligent Transportation Systems.Gran Canaria:IEEE,2015:632-637. |
| [3] | LIU X, REN P, GAO Y,et al .Keypoint fusion for RGB-D based 3D hand pose estimation[C]∥Proceedings of the AAAI Conference on Artificial Intelligence.Vancouver:AAAI Press,2024:3756-3764. |
| [4] | REZAEI M, RASTGOO R, ATHITSOS V .TriHorn-net:a model for accurate depth-based 3D hand pose estimation[J].Expert Systems with Applications,2023,223(1):119922/1-9. |
| [5] | 孙迪钢,张平 .基于先验知识和网格监督的手部姿态估计[J].华南理工大学学报(自然科学版),2024,52(6):138-147. |
| SUN Digang, ZHANG Ping .Hand pose estimation based on prior knowledge and mesh supervision[J].Journal of South China University of Technology (Natural Science Edition),2024,52(6):138-147. | |
| [6] | KAZAKOS E, NIKOU C, KAKADIARIS I A .On the fusion of RGB and depth information for hand pose estimation[C]∥Proceedings of 2018 25th IEEE International Conference on Image Processing.Athens:IEEE,2018:868-872. |
| [7] | XU P, ZHU X, CLIFTON D A .Multimodal learning with transformers:a survey[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2023,45(10):12113-12132. |
| [8] | HU X, YANG K, FEI L,et al .ACNet:attention based network to exploit complementary features for rgbd semantic segmentation[C]∥Proceedings of 2019 IEEE International Conference on Image Processing.Taipei:IEEE,2019:1440-1444. |
| [9] | HU J, SHEN L, SUN G .Squeeze-and-excitation networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE Computer Society,2018:7132-7141. |
| [10] | LIU X, REN P, CHEN Y,et al .SA-Fusion:multimodal fusion approach for web-based human-computer interaction in the wild[C]∥Proceedings of the ACM Web Conference 2023.Austin:ACM Press,2023:3883-3891. |
| [11] | GUAN X, SHEN H, NYATEGA C O,et al .Repeated cross-scale structure-induced feature fusion network for 2D hand pose estimation[J].Entropy,2023,25(5):724/1-16. |
| [12] | 冼进,徐小茹,冼允廷,等 .基于混合编码和掩膜空间调制的图像补全算法[J].华南理工大学学报(自然科学版),2025,53(3):31-39. |
| XIAN Jin, XU Xiaoru, XIAN Yunting,et al .Image inpainting network based on hybrid encoding and mask space modulation[J].Journal of South China University of Technology (Natural Science Edition),2025,53(3):31-39. | |
| [13] | REN P, CHEN Y, HAO J,et al .Two heads are better than one: Image-point cloud network for depth-based 3D hand pose estimation[C]∥Proceedings of the AAAI Conference on Artificial Intelligence.Wa-shington D C:AAAI Press,2023:2163-2171. |
| [14] | OHKAWA T, HE K, SENER F,et al .Assemblyhands:towards egocentric activity understanding via 3d hand pose estimation[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Vancouver:IEEE,2023:12999-13008. |
| [15] | CHAO Y, YANG W, XIANG Y,et al .DexYCB:a benchmark for capturing hand grasping of objects[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Virtual Conference:IEEE,2021:9044-9053. |
| [16] | MOON G, YU S I, WEN H,et al .InterHand2.6M:a dataset and baseline for 3D interacting hand pose estimation from a single RGB image[C]∥Proceedings of 16th European Conference on Computer Vision-ECCV 2020:Glasgow:Springer International Publishing,2020:548-564. |
| [17] | PASZKE A, GROSS S, MASSA F,et al .PyTorch: an imperative style,high-performance deep learning library[J].Advances in Neural Information Processing Systems,2019,32(1):8026–8037 |
| [18] | KULON D, WANG H, GüLER R A,et al .Single image 3D hand reconstruction with mesh convolutions[EB/OL].(2019-08-15)[2024-12-30].. |
| [19] | HUANG W, REN P, WANG J,et al .AWR:adaptive weighting regression for 3d hand pose estimation[C]∥Proceedings of the AAAI Conference on Artificial Intelligence.New York:AAAI Press,2020:11061-11068. |
| [20] | XIONG F, ZHANG B, XIAO Y,et al .A2J: anchor-to-joint regression network for 3D articulated pose estimation from a single depth image[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision.Seoul:IEEE,2019:793-802. |
| [21] | JIANG C, XIAO Y, WU C,et al .A2J-transformer:anchor-to-joint transformer network for 3D interacting hand pose estimation from a single RGB image[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Vancouver:IEEE,2023:8846-8855. |
| [22] | FU Q, LIU X, XU R,et al .Deformer:dynamic fusion transformer for robust hand pose estimation[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision.Paris:IEEE,2023:23600-23611. |
| [23] | KUANG Z, DING C, YAO H .Learning context with priors for 3D interacting hand-object pose estimation[C]∥Proceedings of the 32nd ACM International Conference on Multimedia.Melbourne:Association for Computing Machinery,2024:768-777. |
| [24] | DURAN E, KOCABAS M, CHOUTAS V,et al .HMP: hand motion priors for pose and shape estimation from video[C]∥Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision.Waikoloa:IEEE,2024:6353-6363. |
| [25] | PARK J K,OH Y, MOON G,et al .HandOccNet: occlusion-robust 3D hand mesh estimation network[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.New Orleans:IEEE,2022:1496-1505. |
| [26] | HAMPALI S,RAD M, OBERWEGER M,et al .HOnnotate: a method for 3D annotation of hand and object poses[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Virtual Event:IEEE,2020:3196-3206. |
| [27] | OPHOFF T, VAN BEECK K, GOEDEMé T .Exploring RGB+ depth fusion for real-time object detection[J].Sensors,2019,19(4):866/1-16. |
| [28] | LI L, ZHUO L, ZHANG B,et al .DiffHand: end-to-end hand mesh reconstruction via diffusion models[EB/OL].(2023-05-23)[2024-12-30].. |
| [29] | GAO K, LIU X, REN P,et al .Progressively global-local fusion with explicit guidance for accurate and robust 3D hand pose reconstruction[J].Knowledge-Based Systems,2024,304:112532/ 1-22. |
| [30] | LIN X, ZHOU Y, DU K,et al .Multi-level fusion net for hand pose estimation in hand-object interaction[J].Signal Processing:Image Communication,2021,94(1):116196/1-14. |
| [31] | HASSON Y, TEKIN B, BOGO F,et al .Leveraging photometric consistency over time for supervised hand-object reconstruction[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Virtual Event:IEEE,2020:571-580. |
| [32] | FAN Z, SPURR A, KOCABAS M,et al .Learning to disambiguate strongly interacting hands via probabilistic per-pixel part segmentation[C]∥Proceedings of 2021 International Conference on 3D Vision.London:IEEE,2021:1-10. |
| [33] | HAMPALI S, SARKAR S D,RAD M,et al .Keypoint transformer:solving joint identification in challenging hands and object interactions for accurate 3d pose estimation[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.New Orleans:IEEE,2022:11090-11100. |
| [34] | SUN D, ZHANG P .Interacting two-hand instance segmentation and pose estimation based on attention-induced separation[J].doi:10.36227/techrxiv.171341028.82821498/v1 . |
| [35] | YAO H, DING C, XU X,et al .Decoupling heterogeneous features for robust interacting hand poses estimation[C]∥Proceedings of the 32nd ACM International Conference on Multimedia.Melbourne:Association for Computing Machinery,2024:5338-5346. |
/
| 〈 |
|
〉 |
地址:广州 五山 华南理工大学17号楼 邮政编码:510640
电话: 020-87111794 邮箱:journal@scut.edu.cn

