
收稿日期: 2024-10-09
网络出版日期: 2025-04-21
基金资助
广东省自然科学基金项目(2024A1515010204);南方电网科学研究院项目(1500002024030103XA00063)
Design and Optimization of Small-Batch Matrix Multiplication Based on Matrix Core
Received date: 2024-10-09
Online published: 2025-04-21
Supported by
the Natural Science Foundation of Guangdong Province(2024A1515010204)
通用矩阵乘法(GEMM)是线性代数中最重要的运算,来自不同科学领域的许多应用程序都将其关键部分转换为使用GEMM的形式。GEMM广泛应用于大模型、机器学习、科学计算和信号处理等领域。特别是半精度的批处理GEMM(即FP16)一直是许多深度学习框架的核心操作。目前AMD GPU上半精度批处理GEMM的访存和计算利用率不足,急需优化。为此,该文提出了一种半精度批处理GEMM(HGEMM)的图形处理器(GPU)优化方案。分块策略方面,根据输入矩阵块大小为线程分配相同的访存量和计算量,同时线程计算多个矩阵乘法,以提高计算单元的利用率。访存优化方面,以多读数据为代价,为每个线程分配相同访存量以便于编译器优化,保证访存和计算时间相互掩盖。对于矩阵尺寸小于16的极小尺寸批处理HGEMM,该文利用4 × 4 × 4的Matrix Core及其对应的分块方案,在提升访存性能的同时减少Matrix Core计算资源的浪费,并提供是否使用共享内存的选项来达到最高性能。在AMD GPU MI210平台上,将该方案与rocBLAS的2个算子进行性能对比,结果表明:该方案在AMD GPU MI210上的平均性能为rocBLASHGEMMBatched的4.14倍,rocBLASGEMMExBatched的4.96倍;对于极小尺寸批处理HGEMM,平均性能为rocBLASHGEMMBatched的18.60倍,rocBLASGEMMExBatched的14.02倍。
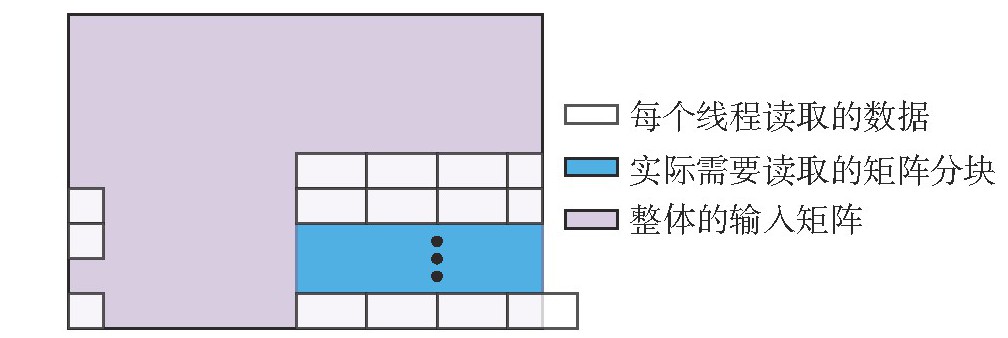
关键词: 图形处理器; Matrix Core; 矩阵乘法; 访存优化
陆璐 , 赵容 , 梁志宏 , 索思亮 . 基于Matrix Core的小尺寸批量矩阵乘法设计与优化[J]. 华南理工大学学报(自然科学版), 2025 , 53(9) : 48 -58 . DOI: 10.12141/j.issn.1000-565X.240498
General Matrix Multiplication (GEMM) is one of the most important operations in linear algebra, serving as the backbone for numerous applications in machine learning, scientific computing, and signal processing. In particular, FP16 batch GEMM has become a core operation in deep learning frameworks due to its efficiency in training and inference. However, current implementations on AMD GPUs (e.g., CDNA/MI200 architectures with Matrix Cores) suffer from suboptimal memory access and low compute utilization, limiting performance in high-throughput scenarios. Therefore, this paper proposed a GPU optimization scheme for half-precision batch GEMM (HGEMM). In terms of blocking strategy, it allocates equal memory access and computational loads to threads based on input matrix sizes, while enabling each thread to compute multiple matrix multiplications to improve arithmetic unit utilization. For memory access optimization, it trades redundant data reads for uniform memory access patterns per thread to facilitate compiler optimization, ensuring overlapping of memory and computation time. For extremely small-batch HGEMM with matrix dimensions smaller than 16, the proposed method employs a 4 × 4 × 4 Matrix Core and its corresponding tiling scheme to enhance memory performance while reducing computational resource wastage, and provides the option of whether to use shared memory to achieve the highest performance. This paper compares the performance of this scheme with two operators of rocBLAS on the AMD GPU MI210 platform. The results show that the ave-rage performance of this scheme on AMD GPU MI210 is 4.14 times that of rocBLASHGEMMBatched and 4.96 times that of rocBLASGEMMExBatched. For extremely small-batch HGEMM, the average performance is 18.60 times that of rocBLASHGEMMBatched and 14.02 times that of rocBLASGEMMExBatched.
| [1] | FAINGNAERT T, BESARD T, DE SUTTER B .Flexi-ble performant GEMM Kernels on GPUs[J].IEEE Transactions on Parallel and Distributed Systems,2021,33(9):2230-2248. |
| [2] | LIU X, LIU Y, YANG H,et al .Toward accelerated stencil computation by adapting tensor core unit on GPU[C]∥ Proceedings of the 36th ACM International Con-ference on Supercomputing.New York:ACM,2022:28/1-12. |
| [3] | KIM H, SONG W J .LAS:locality-aware scheduling for GEMM-accelerated convolutions in GPUs[J].IEEE Transactions on Parallel and Distributed Systems,2023,34(5):1479-1494. |
| [4] | GREGERSEN T, PATEL P, CHOUKSE E .Input-dependent power usage in GPUs[EB/OL]. (2024-09-26)[2024-10-14].. |
| [5] | MARTíNEZ H, CATALáN S, CASTELLó A,et al .Parallel GEMM-based convolutions for deep learning on multicore ARM and RISC-V architectures[J].Journal of Systems Architecture,2024,153:103186/1-19. |
| [6] | ZHOU Y, YANG M, GUO C,et al .Characterizing and demystifying the implicit convolution algorithm on commercial matrix-multiplication accelerators[C]∥ Proceedings of 2021 IEEE International Symposium on Workload Characterization.Storrs:IEEE,2021:214-225. |
| [7] | MILOJICIC D .Accelerators for artificial intelligence and high-performance computing[J].Computer,2020,53(2):14-22. |
| [8] | NVIDIA Corporation .NVIDIA Tesla V100 GPU architecture[EB/OL]. (2017-08-01)[2024-10-14].. |
| [9] | Advanced Micro Devices,Inc .Introducing AMD CDNATM 2 architecture[EB/OL]. (2021-09-21)[2024-10-14].. |
| [10] | NVIDIA Corporation .cuBLAS library documentation[EB/OL].(2022-07-23)[2024-10-14].. |
| [11] | Corporation AMD .ROCm BLAS library documentation[EB/OL]. (2022-09-11)[2024-10-14].. |
| [12] | Innovative Computing Laboratory .MAGMA library documentation[EB/OL]. (2022-03-22)[2024-10-14].. |
| [13] | SADASIVAN H, OSAMA M, PODKORYTOV M,et al .Stream-K++:adaptive GPU GEMM kernel scheduling and selection using Bloom filters[EB/OL]. (2024-08-21)[2024-10-14].. |
| [14] | DOROZHINSKII R, GADESCHI G B, BADER M.Fused GEMMs towards an efficient GPU implementation of the ADER-DG method in SeisSol[J].Concurrency and Computation:Practice and Experience,2024,36(12):e8037/1-19. |
| [15] | ABDELFATTAH A, HAIDAR A, TOMOV S,et al.Performance,design,and autotuning of batched GEMM for GPUs[C]∥ Proceedings of the 31st International Conference on High Performance Computing.Frankfurt:Springer,2016:21-38. |
| [16] | TANG H, KOMATSU K, SATO M,et al .Efficient mixed-precision tall-and-skinny matrix-matrix multiplication for GPUs[J].International Journal of Networ-king and Computing,2021,11(2):267-282. |
| [17] | RIVERA C, CHEN J, XIONG N,et al .ISM2:optimizing irregular-shaped matrix-matrix multiplication on GPUs[EB/OL].(2021-02-18)[2024-10-14].. |
| [18] | BROWN C, ABDELFATTAH A, TOMOV S,et al .Design,optimization,and benchmarking of dense li-near algebra algorithms on AMD GPUs[C]∥ Procee-dings of 2020 IEEE High Performance Extreme Compu-ting Conference.Waltham:IEEE,2020:1-7. |
| [19] | BACH M, KRETZ M, LINDENSTRUTH V,et al .Optimized HPL for AMD GPU and multi-core CPU usage[J].Computer Science:Research and Development,2011,26:153-164. |
| [20] | WILKINSON F, COCKREAN A, LIN W C,et al .Assessing the GPU offload threshold of GEMM and GEMV kernels on modern heterogeneous HPC systems[C]∥SC24-W:Workshops of the International Conference for High Performance Computing,Networking,Storage and Analysis.Atlanta:IEEE,2024:1481-1495. |
| [21] | AMD.HIP documentation[EB/OL].(2024-04-17)[2024-10-14].. |
| [22] | SCHIEFFER G, DE MEDEIROS D A,FAJ J,et al .On the rise of AMD Matrix Cores:performance,power efficiency,and programmability[C]∥ Proceedings of 2024 IEEE International Symposium on Performance Analysis of Systems and Software.Indianapolis:IEEE,2024:132-143. |
| [23] | Advanced Micro Devices,Inc .Introducing AMD CDNA2 architecture[EB/OL]. (2021-09-21)[2024-10-14].. |
| [24] | Advanced Micro Devices,Inc .rocWMMA documentation[EB/OL].(2023-08-11)[2024-10-14].. |
| [25] | 陆璐,祝松祥,田卿燕,等 .基于Matrix Core的高性能多维FFT设计与优化[J].华南理工大学学报(自然科学版),2025,53(3):20-30. |
| LU Lu, ZHU Songxiang, TIAN Qingyan,et al .Design and optimization of high-performance multi-dimensional FFT based on Matrix Core[J].Journal of South China University of Technology (Natural Science Edition),2025,53(3):20-30. |
/
| 〈 |
|
〉 |
地址:广州 五山 华南理工大学17号楼 邮政编码:510640
电话: 020-87111794 邮箱:journal@scut.edu.cn

