
收稿日期: 2022-09-30
网络出版日期: 2023-06-21
基金资助
工信部制造业高质量发展专项资金资助项目(R-ZH-023-QT-001-20221009-001);广州市科技计划项目(2023B01J0016)
Traffic Sign Detection Based on Channel Attention and Feature Enhancement
Received date: 2022-09-30
Online published: 2023-06-21
Supported by
the Special Fund for High-Quality Development of MIIT Manufacturing Industry(R-ZH-023-QT-001-20221009-001)
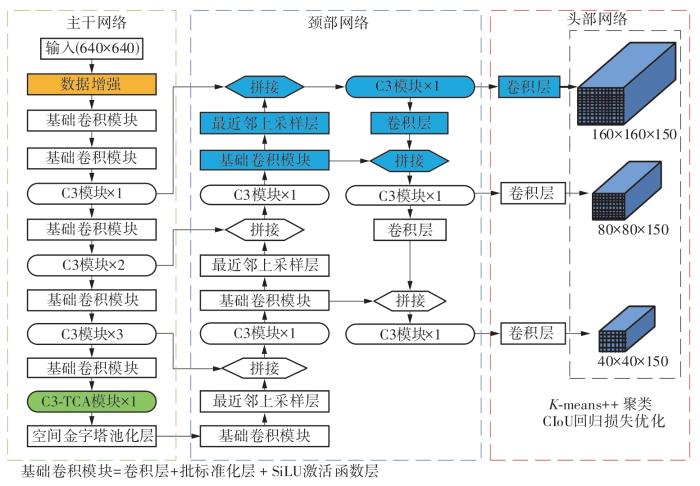
道路上的交通标志包含大量的交通规则语义信息,快速、准确地获取这些信息有助于实现更高级别的辅助驾驶功能,从而提高车辆的安全性能。针对交通标志易受外界因素影响、类别间相似度高和尺寸微小的难点,本研究基于YOLOv5s模型,在数据预处理、特征提取、特征增强方面分别进行了针对性的改进。在数据预处理部分,利用颜色空间变换、几何变换矩阵来模拟实际场景中交通标志可能发生的颜色变化和形状变化,通过Mosaic算法、Copy-paste算法来提高训练集中微小交通标志的数量和背景的丰富性。在特征提取部分,构建了基于通道注意力标定的C3-TCA模块来提高模型对相似特征的辨别能力。在特征增强部分,通过双路径增强结构融合浅层特征和深层特征,并优化了预测分支的数量和下采样倍率,从而增加了对微小交通标志的检测精度。此外,还利用K-means++算法聚类先验框模板,基于CIoU度量构建边界框回归损失函数,从而降低边界框的回归难度。在TT100K和CCTSDB数据集上进行测试,模型的mAP@0.5指标分别为88.8%和83.5%,模型的检测速度分别为120.5 f/s和114.7 f/s。相较于现有交通标志检测模型,所构建模型在检测精度和检测速度上均达到了先进水平。针对数据增强算法、预测分支、通道注意力模块位置的对比实验进一步证明了所提具体优化方法的有效性。
罗玉涛, 高强 . 基于通道注意力和特征增强的交通标志检测[J]. 华南理工大学学报(自然科学版), 2023 , 51(12) : 64 -72 . DOI: 10.12141/j.issn.1000-565X.220639
Traffic signs on the road contain a large amount of semantic information about traffic rules, and rapid and accurate access to this information helps to achieve higher levels of assisted driving functions, thus improving vehicle’s safety performance. In view of the traffic signs are susceptible to external factors and the problems of high similarity between categories and small size, this paper made targeted improvements in data augmentation, feature extraction and feature enhancement based on YOLOv5s model. In the data augmentation part, color space transformation and geometric transformation matrix were used to simulate the possible color changes and shape changes of traffic signs in actual scenes, and the Mosaic algorithm and Copy-paste algorithm were used to improve the number of tiny traffic signs in the training set and the richness of the background. In the feature extraction part, a feature extraction module based on channel attention calibration was constructed to improve the model’s ability to discriminate similar features. In the feature enhancement part, the number of prediction branches and downsampling multiplier were optimized by fusing shallow features and deep features with a dual-path enhancement structure, so as to increase the detection accuracy of tiny traffic signs. In addition, the K-means++ algorithm was used to cluster the prior bounding box templates and construct the loss function based on the CIoU metric, thus reducing the difficulty of the prior bounding box regression. Experiments on the TT100K and CCTSDB dataset test show that the mAP@0.5 of the proposed model is 88.8% and 83.5% respectively, and the speed of the model is 120.5 f/s and 114.7 f/s respectively. Compared with the existing traffic sign detection models, the proposed model reaches the advanced level in both accuracy and speed. Comparison experiments for data augmentation algorithms, prediction branches, and channel attention module positions further demonstrate the effectiveness of the proposed specific optimization methods.
| 1 | GIRSHICK R, DONAHUE J, DARRELL T,et al .Rich feature hierarchies for accurate object detection and semantic segmentation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Columbus:IEEE,2014:580-587. |
| 2 | REN S Q, HE K M, GIRSHICK R,et al .Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactionson on Patern Analysis and Machine Inteligence,2017,39(6):1137-1149. |
| 3 | GIRSHICK R. Fast R-CNN[C]∥Proceedings of the IEEE International Conference on Computer Vision. Santiago:IEEE,2015:1440-1448. |
| 4 | REDMON J, DIVVALA S, GIRSHICK R,et al .You only look once:unified,real-time object detection[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE, 2016:779-788. |
| 5 | REDMON J, FARHADI A. Yolov3:an incremental improvement[J].arXiv Preprint arXiv:,2018. |
| 6 | REDMON J, FARHADI A .YOLO9000:better,faster,stronger[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu:IEEE,2017:7263-7271. |
| 7 | BOCHKOVSKIY A, WANG C Y, LIAO H Y M .Yolov4:optimal speed and accuracy of object detection[J].arXiv Preprint arXiv:,2020. |
| 8 | GE Z, LIU S, WANG F,et al .Yolox:exceeding yolo series in 2021[J].arXiv Preprint arXiv:,2021. |
| 9 | LIU W, ANGUELOV D, ERHAN D,et al .SSD:single shot multibox detector[C]∥Proceedings of the 14th European Conference on Computer Vision. Amsterdam:Springer,2016:21-37. |
| 10 | 王卜,何扬 .基于改进YOLOv3的交通标志检测[J].四川大学学报(自然科学版),2022,59(1):57-67. |
| WANG Bu, HE Yang .Traffic sign detection based on improved YOLOv3[J].Journal of Sichuan University(Natural Science Edition),2022,59(1):57-67. | |
| 11 | 陈梦涛,余粟 .基于改进YOLOV4模型的交通标志识别研究[J].微电子学与计算机,2022,39(1):17-25. |
| CHEN Mengtao, YU Su .Research on traffic sign recognition based on improved YOLOV4 model[J].Microelectronics & Computer,2022,39(1):17-25. | |
| 12 | HOU Q B, ZHOU D Q, FENG J S .Coordinate attention for efficient mobile network design[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.[S.l.]:IEEE,2021:13713-13722. |
| 13 | LIU S T, HUANG D, WANG Y H .Learning spatial fusion for single-shot object detection[J].arXiv Preprint arXiv:,2019. |
| 14 | LIU X, JIANG X K, HU H C,et al .Traffic sign recognition algorithm based on improved YOLOv5s[C]∥Proceedings of the International Conference on Control,Automation and Information Sciences.Xi’an:IEEE,2021:980-985. |
| 15 | KINGMA D P, BA J .Adam:a method for stochastic optimization[J].arXiv Preprint arXiv:,2014. |
| 16 | SANDLER M, HOWARD A, ZHU M,et al .Mobilenetv2:inverted residuals and linear bottlenecks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:4510-4520. |
| 17 | WANG C Y, LIAO H Y M, WU Y H,et al .CSPNet:a new backbone that can enhance learning capability of CNN[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.[S.l.]:IEEE,2020:390-391. |
| 18 | 冯润泽,江昆,于伟光,等 .基于两阶段分类算法的中国交通标志牌识别[J].汽车工程,2022,44(3):434-441,448. |
| FENG Runze, JIANG Kun, YU Weiguang,et al .Chinese traffic sign recognition based on two-stage classification algorithm[J].Automotive Engineering,2022,44(3):434- 441,448. | |
| 19 | HE K M, ZHANG X Y, REN S Q,et al .Deep residual learning for image recognition[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE,2016:770-778. |
| 20 | LIU S, QI L, QIN H F,et al .Path aggregation network for instance segmentation[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:8759-8768. |
| 21 | GHIASI G, CUI Y, SRINIVAS A,et al .Simple copy-paste is a strong data augmentation method for instance segmentation[C]∥Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.[S.l.]:IEEE,2021:2918-2928. |
| 22 | KRISHNA K, MURTY M N .Genetic K-means algorithm[J].IEEE Transactions on Systems,Man,and Cybernetics,Part B (Cybernetics),1999,29(3):433-439. |
| 23 | ZHENG Z H, WANG P, LIU W,et al .Distance-IoU loss:faster and better learning for bounding box regression[C]∥Proceedings of the AAAI Conference on Artificial Intelligence.New York:AAAI,2020,34(7):12993-13000. |
| 24 | IOFFE S, SZEGEDY C .Batch normalization:accelerating deep network training by reducing internal covariate shift[C]∥Proceedings of International Conference on Machine Learning.Lille:ACM,2015:448-456. |
| 25 | HU J, SHEN L, SUN G .Squeeze-and-excitation networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:7132-7141. |
| 26 | LIN T Y, DOLLáR P, GIRSHICK R,et al .Feature pyramid networks for object detection[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Honolulu:IEEE,2017:2117-2125. |
| 27 | ZHANG H, CISSE M, DAUPHIN Y N,et al .Mixup:beyond empirical risk minimization[J].arXiv Preprint arXiv:,2017. |
| 28 | YUN S, HAN D, OH S J,et al .Cutmix:regularization strategy to train strong classifiers with localizable features[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision.Seoul:IEEE,2019:6023-6032. |
/
| 〈 |
|
〉 |
地址:广州 五山 华南理工大学17号楼 邮政编码:510640
电话: 020-87111794 邮箱:journal@scut.edu.cn

