
收稿日期: 2022-07-08
网络出版日期: 2022-10-20
基金资助
国家自然科学基金资助项目(61672173);国家重点研发计划项目(2018YFB1802200)
Multi-View Lip Motion and Voice Consistency Judgment Based on Lip Reconstruction and Three-Dimensional Coupled CNN
Received date: 2022-07-08
Online published: 2022-10-20
Supported by
the National Natural Science Foundation of China(61672173);the National Key R&D Program of China(2018YFB1802200)
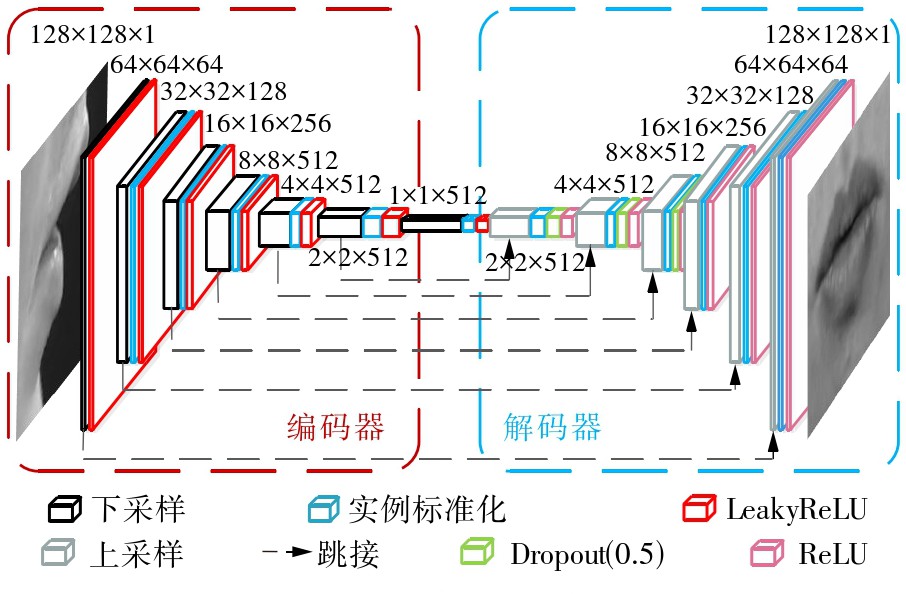
针对传统音唇一致性判别方法主要对正面唇动视频进行处理,未考虑视频采集角度变化对结果的影响,且容易忽略唇动过程中的时空特性等不足,文中以唇部角度变化对一致性判别的影响为研究重心,结合三维卷积神经网络在非线性表示和时空维度特征提取上的优势,提出了基于正面唇重构与三维耦合卷积神经网络的多视角音唇一致性判别方法。该方法先通过在生成器中引入自映射损失来提高正面重建效果,并采用基于自映射监督循环一致性生成对抗网络(SMS-CycleGAN)的唇重构方法对多视角唇图进行角度分类及正面重构;然后设计两个异构三维卷积神经网络,分别用来描述音频和视频信号,并提取包含长时时空关联信息的三维卷积特征;最后引入对比损失函数作为音视频信号匹配的相关度鉴别度量,将音视频网络输出耦合到同一表示空间,并进行一致性判别。实验结果表明,文中方法能重建出更高质量的正面唇图,一致性判别性能优于多种不同类型的比较方法。
朱铮宇, 罗超, 贺前华, 等 . 基于唇重构与三维耦合CNN的多视角音唇一致性判别[J]. 华南理工大学学报(自然科学版), 2023 , 51(5) : 70 -77 . DOI: 10.12141/j.issn.1000-565X.220435
The traditional consistency judgment methods of lip motion and voice mainly focus on processing the frontal lip motion video,without considering the impact of angle changes on the result during the video acquisition process. In addition, they are prone to ignoring the spatio-temporal characteristics of the lip movement process.Aiming at these problems, this paper focused on the influence of lip angle changes on consistency judgment,combined the advantages of three dimensional convolutional neural networks for non-linear representation and spatio-temporal dimensional feature extraction, and proposed a multi-view lip motion and voice consistency judgment method based on frontal lip reconstruction and three dimensional(3D) coupled convolutional neural network.Firstly,the self-mapping loss was introduced into the generator to improve the effect of frontal reconstruction, and then the lip reconstruction method based on self-mapping supervised cycle-consistent generative adversarial network (SMS-CycleGAN) was used for angle classification and frontal reconstruction of multi-view lip image.Secondly,two heterogeneous three dimensional convolution neural networks were designed to describe the audio and video signals respectively, and then the 3D convolution features containing long-term spatio-temporal correlation information were extracted.Finally, the contrastive loss function was introduced as the correlation discrimination measure of audio and video signal matching, and the output of the audio-video network was coupled into the same representation space for consistency judgment. The experimental results show that the method proposed in this paper can reconstruct frontal lip images of higher quality, and it is better than a variety of comparison methods on the performance of consistency judgment.
| 1 | DEBNATH S, RAMALAKSHMI K, SENBAGAVALLI M .Multimodal authentication system based on audio-visual data:a review[C]∥ Proceedings of 2022 International Conference for Advancement in Technology. Goa:IEEE,2022:1-5. |
| 2 | MIN X, ZHAI G, ZHOU J,et al .A multimodal saliency model for videos with high audio-visual correspondence [J].IEEE Transactions on Image Processing,2020,29:3805-3819. |
| 3 | MICHELSANTI D, TAN Z H, ZHANG S X,et al .An overview of deep-learning-based audio-visual speech enhancement and separation[J].IEEE/ACM Transactions on Audio,Speech,and Language Processing,2021,29:1368-1396. |
| 4 | SAINUI J, SUGIYAMA M .Minimum dependency key frames selection via quadratic mutual information [C]∥ Proceedings of 2015 the Tenth International Conference on Digital Information Managemen.Jeju:IEEE,2015:148-153. |
| 5 | 朱铮宇,贺前华,奉小慧,等 .基于时空相关度融合的语音唇动一致性检测算法[J].电子学报,2014,42(4):779-785. |
| ZHU Zheng-yu, HE Qian-hua, FENG Xiao-hui,et al .Lip motion and voice consistency algorithm based on fusing spatiotemporal correlation degree [J].Acta Electronica Sinica,2014,42(4):779-785. | |
| 6 | KUMAR K, NAVRATIL J, MARCHERET E,et al .Audio-visual speech synchronization detection using a bimodal linear prediction model[C]∥ Proceedings of 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops.Florida:IEEE,2009:53-59. |
| 7 | 贺前华,朱铮宇,奉小慧 .基于平移不变字典的语音唇动一致性判决方法[J].华中科技大学学报(自然科学版),2015,43(10):69-74. |
| HE Qianhua, ZHU Zhengyu, FENG Xiaohui .Lip motion and voice consistency analysis algorithm based on shift-invariant dictionary[J].Journal of Huazhong University of Science and Technology(Natural Science Edition),2015,43(10):69-74. | |
| 8 | CHUNG J S, ZISSERMAN A .Lip reading in profile [C]∥ Proceedings of 2017 British Machine Vision Conference.London:BMVA,2017:36-46. |
| 9 | KIKUCHI T, OZASA Y .Watch,listen once,and sync:audio-visual synchronization with multi-modal regression CNN[C]∥ Proceedings of 2018 IEEE International Conference on Acoustics,Speech and Signal Processing.Calgary:IEEE,2018:3036-3040. |
| 10 | CHENG S, MA P, TZIMIROPOULOS G,et al .Towards pose-invariant lip-reading [C]∥ Proceedings of 2020 IEEE International Conference on Acoustics,Speech and Signal Processing.Barcelona:IEEE,2020:4357-4361. |
| 11 | MAEDA T, TAMURA S .Multi-view convolution for lipreading[C]∥ Proceedings of 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference.Tokyo:IEEE,2021:1092-1096. |
| 12 | PETRIDIS S, WANG Y, LI Z,et al .End-to-end multi-view lipreading [C]∥ Proceedings of 2017 British Machine Vision Conference.London:BMVA,2017:1-14. |
| 13 | SARI L, SINGH K, ZHOU J,et al .A multi-view approach to audio-visual speaker verification[C]∥ Proceedings of 2021 IEEE International Conference on Acoustics,Speech and Signal Processing.Toronto:IEEE,2021:6194-6198. |
| 14 | KOUMPAROULIS A, POTAMIANOS G .Deep view2view mapping for view-invariant lipreading[C]∥ Proceedings of 2018 IEEE Spoken Language Technology Workshop.Athens:IEEE,2018:588-594. |
| 15 | EL-SALLAM A A, MIAN A S .Correlation based speech-video synchronization [J].Pattern Recognition Letters,2011,32(6):780-786. |
| 16 | ZHU J Y, PARK T, ISOLA P,et al .Unpaired image-to-image translation using cycle-consistent adversarial networks[C]∥ Proceedings of 2017 IEEE International Conference on Computer Vision.Venice:IEEE,2017:2223-2232. |
| 17 | TANG Z, PENG X, LI K,et al .Towards efficient U-Nets:a coupled and quantized approach [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2020,42(8):2018-2050. |
| 18 | 张瑞峰,白金桐,关欣,等 .结合SE与BiSRU的Unet的音乐源分离方法[J].华南理工大学学报(自然科学版),2021,49(11):106-115,134. |
| ZHANG Ruifeng, BAI Jintong, GUAN Xin,et al .Music source separation method based on Unet combining SE and BiSRU [J].Journal of South China University of Technology (Natural Science Edition),2021,49(11):106-115,134. | |
| 19 | ISOLA P, ZHU J Y, ZHOU T,et al .Image-to-image translation with conditional adversarial networks [C]∥ Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition.Honolulu:IEEE,2017:5967-5976. |
| 20 | HOURRI S, KHARROUBI J .A deep learning approach for speaker recognition [J].International Journal of Speech Technology,2020,23(1):123-131. |
| 21 | MEHROTRA U, GARG S, KRISHNA G,et al .Detecting multiple disfluencies from speech using pre-linguistic automatic syllabification with acoustic and prosody features[C]∥ Proceedings of 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference.Tokyo:IEEE,2021:761-768. |
| 22 | CHUNG J S, ZISSERMAN A .Out of time:automated lip sync in the wild [C]∥ Proceedings of ACCV 2016 International Workshops.Taipei:Springer,2016:251-263. |
/
| 〈 |
|
〉 |
地址:广州 五山 华南理工大学17号楼 邮政编码:510640
电话: 020-87111794 邮箱:journal@scut.edu.cn

