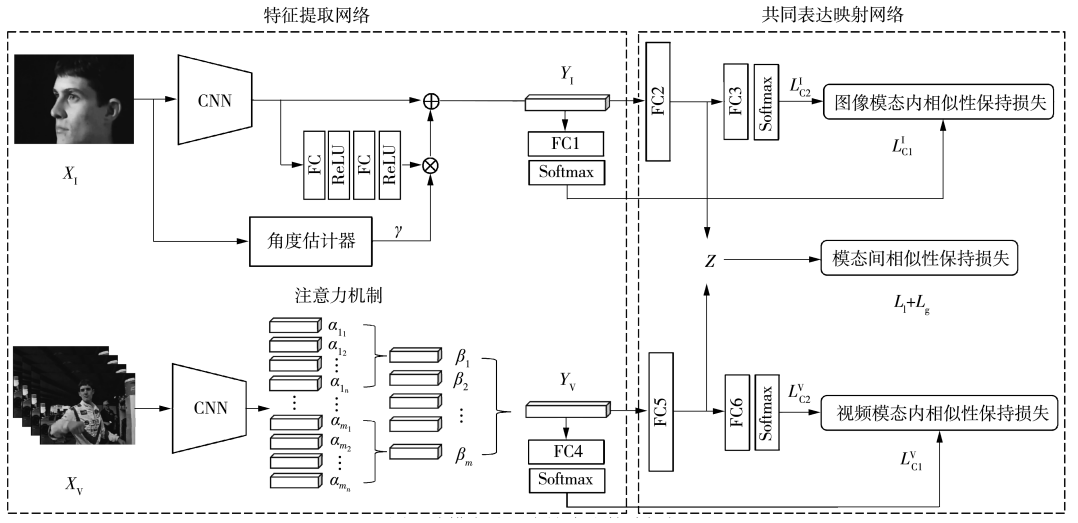
度量学习是一种减少模态差异的重要技术,已有的基于度量学习的跨模态检索方法用于跨模态人脸检索任务时缺乏对视角差异和域差异的关注,并且在度量学习的过程中存在两个问题:缺乏对全局信息的学习和存在大量冗余三元组。文中提出了一种基于度量学习的跨模态共同表达生成算法,采用偏航角等变模块补偿偏航角差异获取具有鲁棒性的图像特征,使用多层注意力机制获取具有可分性的视频特征;结合全局三元组和局部三元组共同训练跨模态共同表达生成网络提升度量学习的一致性和准确性,同时通过半困难三元组筛选加速了损失函数的收敛;提出结合域校准和迁移学习作为域适应方法提升共同表达的泛化性。最终,在PB、YTC和UMD Faces三个人脸视频数据集中的实验结果证明了本文算法有效提升了跨模态人脸检索的准确性,通过少数样本微调跨模态共同表达生成网络有效提升了目标域图像跨模态检索的准确性。
Metric learning is an important technique to reduce modal differences. Existing cross-modal retrieval methods based on metric learning for cross-modal face retrieval tasks lack attention to pose differences and domain differences, and there are two problems in the process of metric learning: lack of learning of global information and the existence of a large number of redundant triplets. In this paper, a cross-modal common representation generation algorithm based on metric learning is proposed. Our study uses the yaw angle equivariant module to compensate for yaw angle differences so that we can obtain the image features with robustness, uses the multi-layer attention mechanism to obtain video features with differentiability; combines global triplets and local triplets to jointly train the cross-modal common representation generation network, then accelerates the convergence of the loss function through the screening of semi-hard triplets; combines domain calibration and transfer learning to improve the generalization of common representations. Finally, the results of comparison experiments on three face video datasets: PB, YTC and UMD Faces, demonstrate that our algorithm can improve the accuracy of cross-modal face retrieval, and the results of fine-tuning the cross-modal common representation generation network using different numbers of samples demonstrate that our algorithm can improve the accuracy of cross-modal retrieval of target domain images.