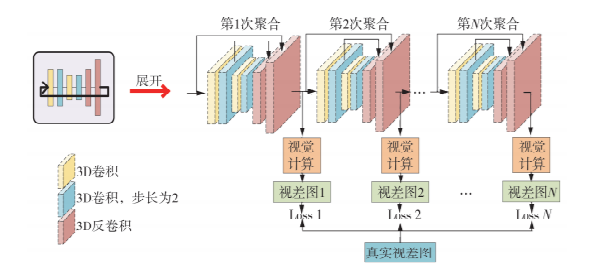
针对基于深度学习的立体匹配网络中病态区域匹配效果欠佳、模型参数量过大的问题,提出了一种基于多阶特征融合与循环代价聚合的端对端立体匹配网络—MFRANet。首先,为兼顾图像低层细节信息与高层语义信息,提出了多阶特征融合模块,采用分阶段、逐步式的特征融合策略对多层次、多尺度特征进行有效融合;其次,在代价聚合阶段提出循环聚合机制,以循环方式对匹配代价卷进行聚合优化,在改善聚合效果的同时不引入过多的参数量;最后,利用基于Soft Argmin算法的视差计算模块计算图像视差。并通过KITTI 2012/2015和SceneFlow两个公开数据集对网络进行训练和测试,与其他端对端立体匹配网络进行了对比研究。结果表明,在SceneFlow和KITTI 2015两个公开数据集上,相较于其他端对端立体匹配网络,MFRANet具有更为精准的匹配结果;对于SceneFlow数据集,终点误差降低至0.92Pixels;对于KITTI 2015数据集,误匹配率降低至2.21%。
Aiming at the poor matching effect of ill-conditioned regions and excessive model parameters in the stereo matching network based on deep learning, an end-to-end stereo matching network based on multi-level feature fusion and recurrent cost aggregation(MFRANet)was proposed. Firstly, in order to take into account both the low-level detail information and high-level semantic information of the image, a multi-stage feature fusion module, which uses a phased and step-by-step feature fusion strategy to effectively fuse multi-level and multi-scale features, was proposed. Secondly, a recurrent mechanism was proposed in the cost aggregation stage to optimize the aggregation of the matching cost volume in a recurrent manner, and it can improve the aggregation effect while avoid introducing too many parameters. Finally, the disparity calculation module based on the Soft Argmin algorithm was used to calculate the image disparity. And through the two public datasets of KITTI 2012/2015 and SceneFlow, the network was trained and tested, and a comparative study with other end-to-end stereo matching networks was caaried out. Experimental results show that, for the two public datasets of SceneFlow and KITTI 2015, MFRANet has more accurate matching results than other end-to-end stereo matching networks; for the SceneFlow dataset, the end-point error is reduced to 0.92 pixels; for the KITTI 2015 dataset, the mismatching rate is reduced to 2.21%.