华南理工大学学报(自然科学版) ›› 2025, Vol. 53 ›› Issue (11): 18-26.doi: 10.12141/j.issn.1000-565X.240598
基于邻居信息聚合的无配对跨模态检索重排序
沃焱, 梁展扬
- 华南理工大学 计算机科学与工程学院,广东 广州 510006
Unpaired Cross-Modal Retrieval Re-Ranking Based on Neighbor Information Aggregation
WO Yan, LIANG Zhanyang
- School of Computer Science and Engineering,South China University of Technology,Guangzhou 510006,Guangdong,China
摘要:
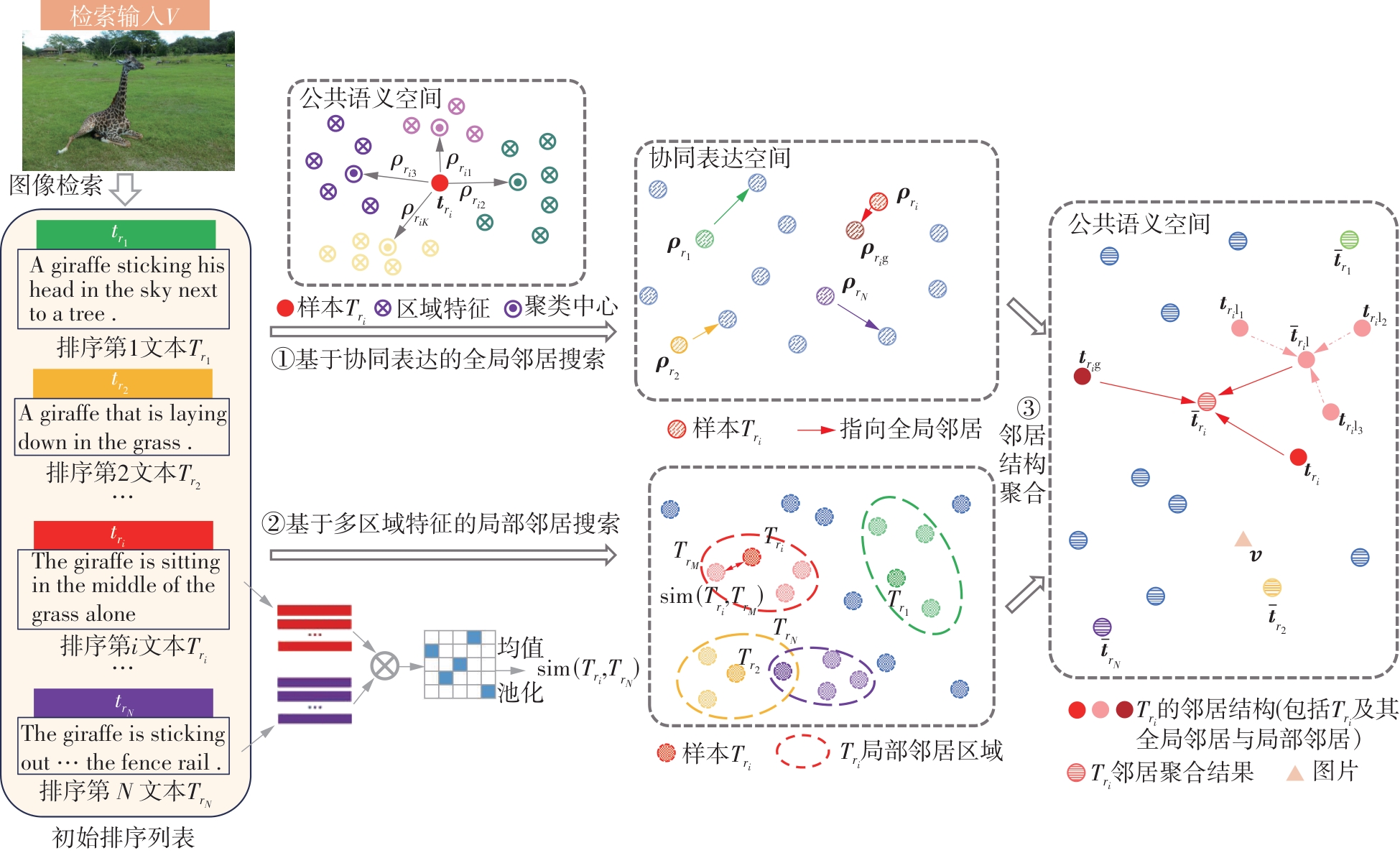
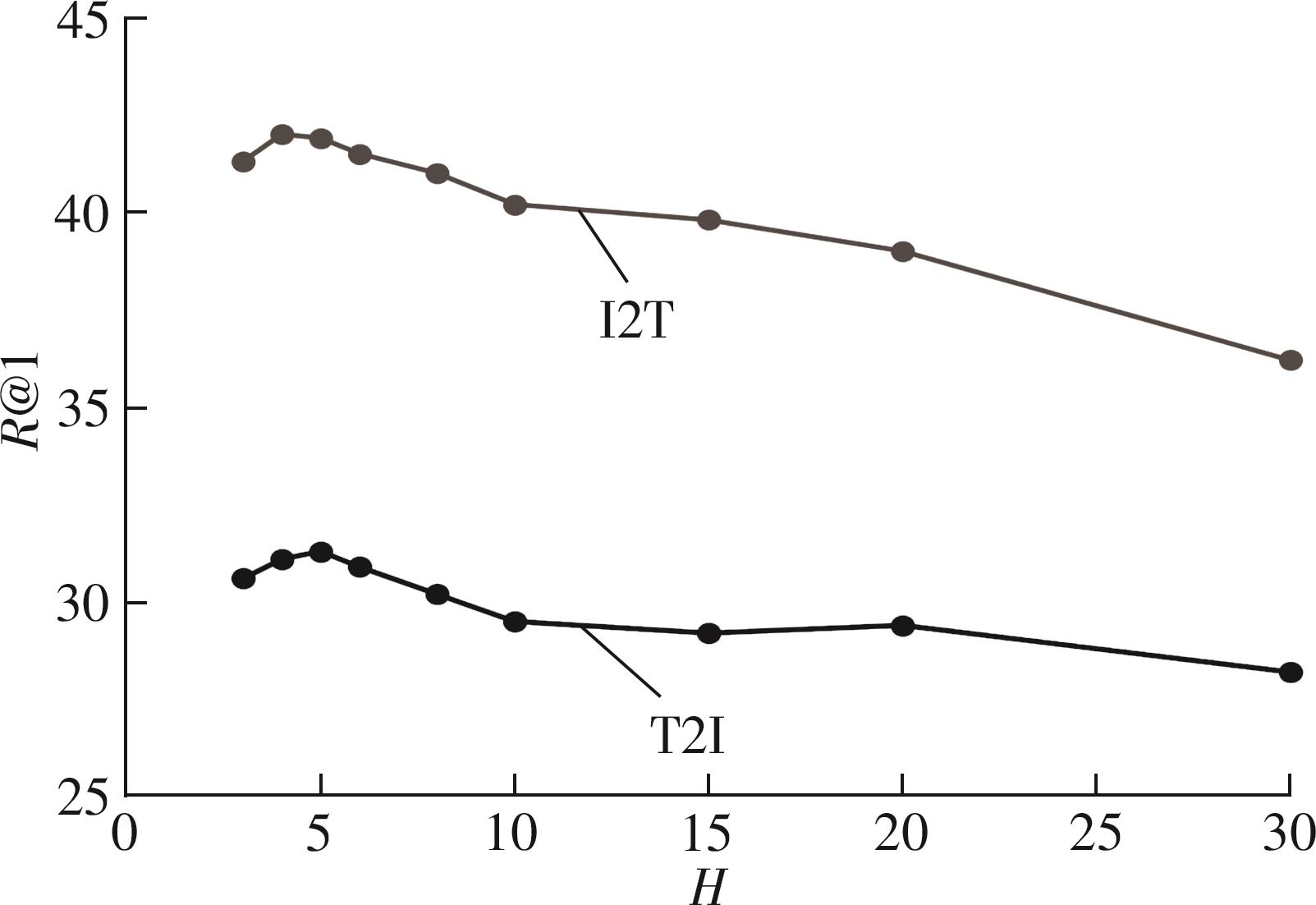
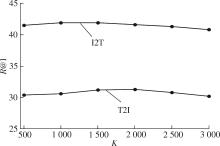
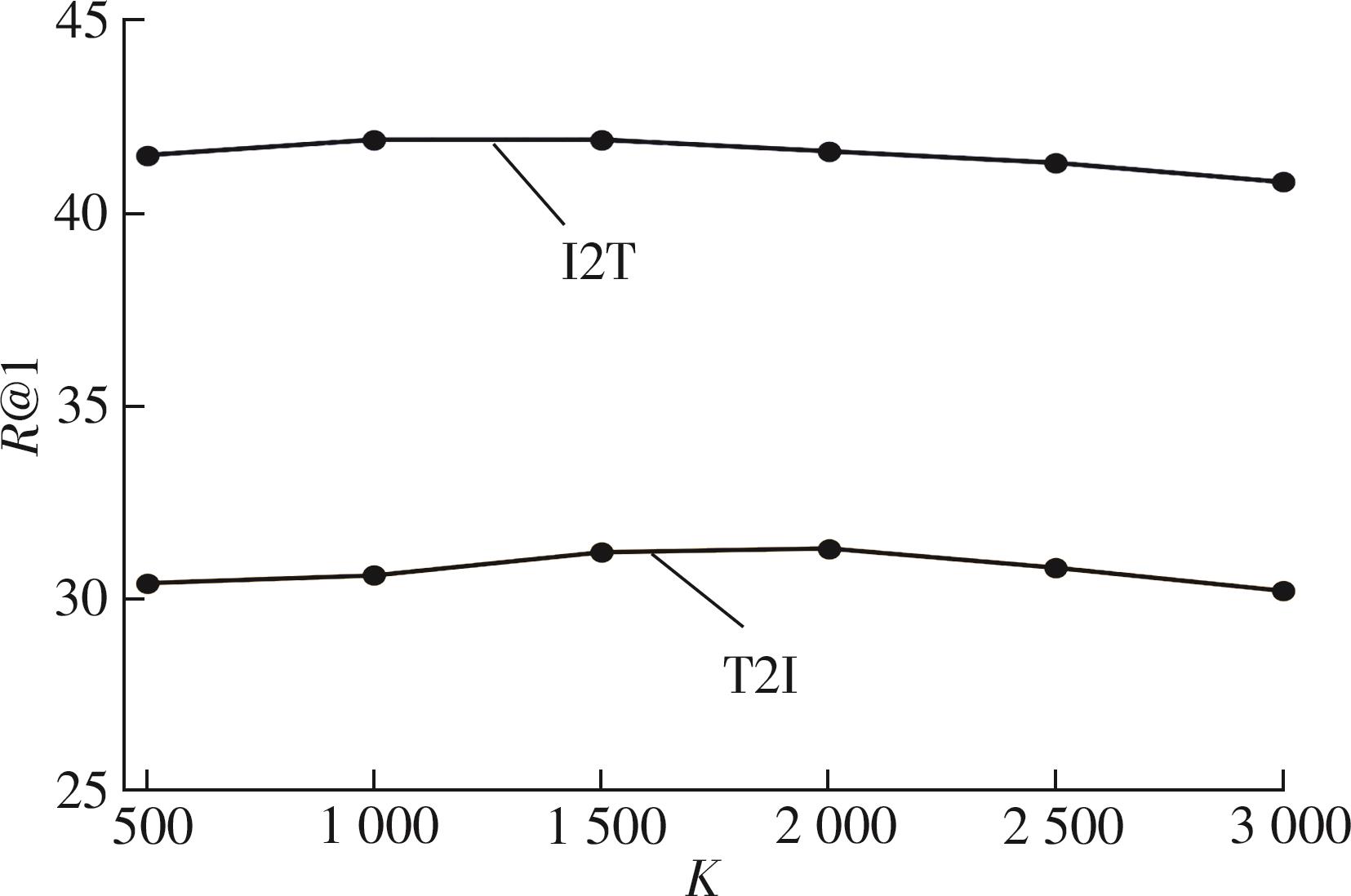
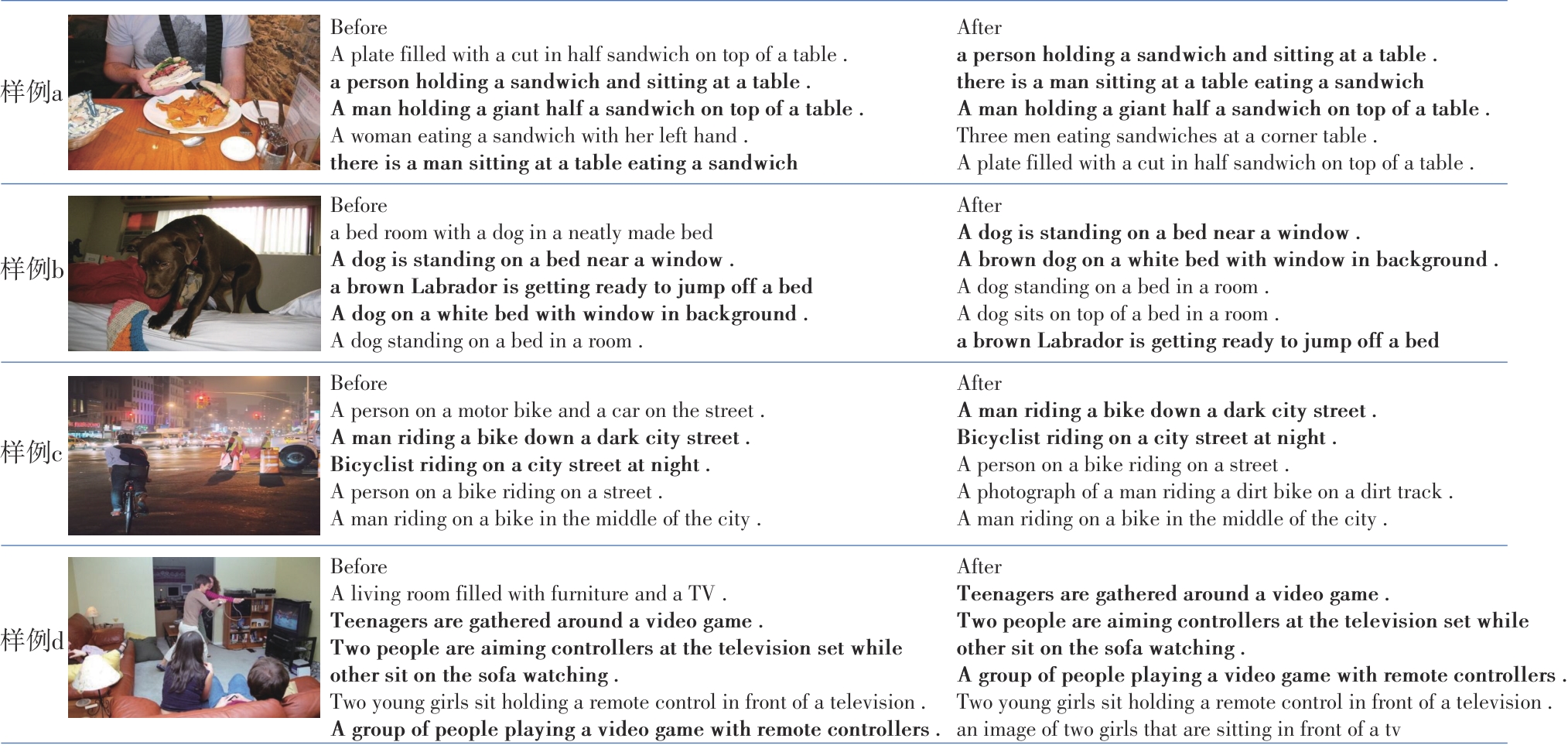
重排序方法作为一种后处理技术,在跨模态检索任务中展现出了显著的效果,它通过挖掘、处理初始排序列表之间的信息,有效提高了检索的准确性。当前主流的跨模态检索重排序方法是在数据集有配对的情况下对初始列表进行重排序,灵活性差,使用时需对原来的框架进行修改并重新训练,无法灵活地迁移到其他框架上;此外,它们无法应用于无配对情景。依赖于大规模配对数据集,跨模态检索目前取得了显著的进展,但忽视了实际场景中标注大规模数据集需耗费大量资源的问题。鉴于此,该文提出了一种基于邻居信息聚合的无配对跨模态检索重排序方法。该方法通过挖掘并利用样本的邻居信息,使错误的答案远离查询输入;通过搜索欧氏邻域中的局部邻居,并基于协同表达搜索全局邻居表达样本的邻居信息,将这两种邻居信息加以融合生成新特征,再重新计算与检索输入的语义相似性,完成重排序。将该方法置于多种跨模态检索框架作为后处理方法,并在MSCOCO数据集上进行实验,结果证明了该方法的有效性以及相对于其他重排序方法的优越性。
中图分类号: