华南理工大学学报(自然科学版) ›› 2022, Vol. 50 ›› Issue (9): 126-137.doi: 10.12141/j.issn.1000-565X.210769
所属专题: 2022年机械工程
一种基于视角选择经验增强算法的机器人抓取策略
王高1,2 陈晓鸿1,2 柳宁2,3 李德平2,3
- 1.暨南大学 信息科学技术学院, 广东 广州 510632
2.暨南大学 机器人智能技术研究院, 广东 广州 510632
3.暨南大学 智能科学与工程学院, 广东 珠海 519070
A Robot Grasping Policy Based on Viewpoint Selection Experience Enhancement Algorithm
WANG Gao1,2 CHEN Xiaohong1,2 LIU Ning2,3 LI Deping2,3
- 1.College of Information Science and Technology,Jinan University,Guangzhou 510632,Guangdong,China
2.Robotics Intelligence Technology Research Institute,Jinan University,Guangzhou 510632,Guangdong,China
3.School of Intelligent Systems Science and Engineering,Jinan University,Zhuhai 519070,Guangdong,China
摘要:
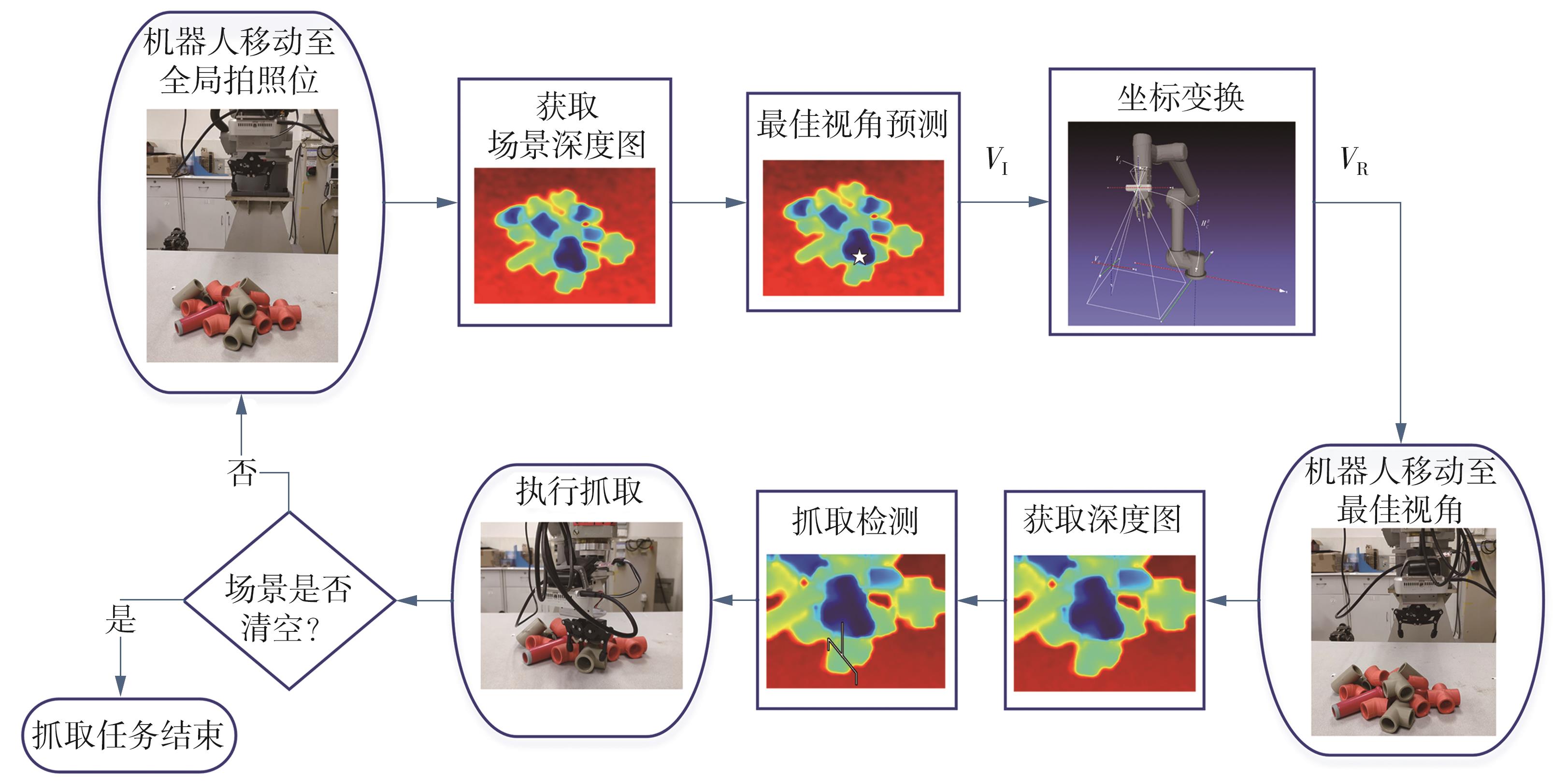
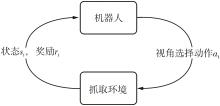
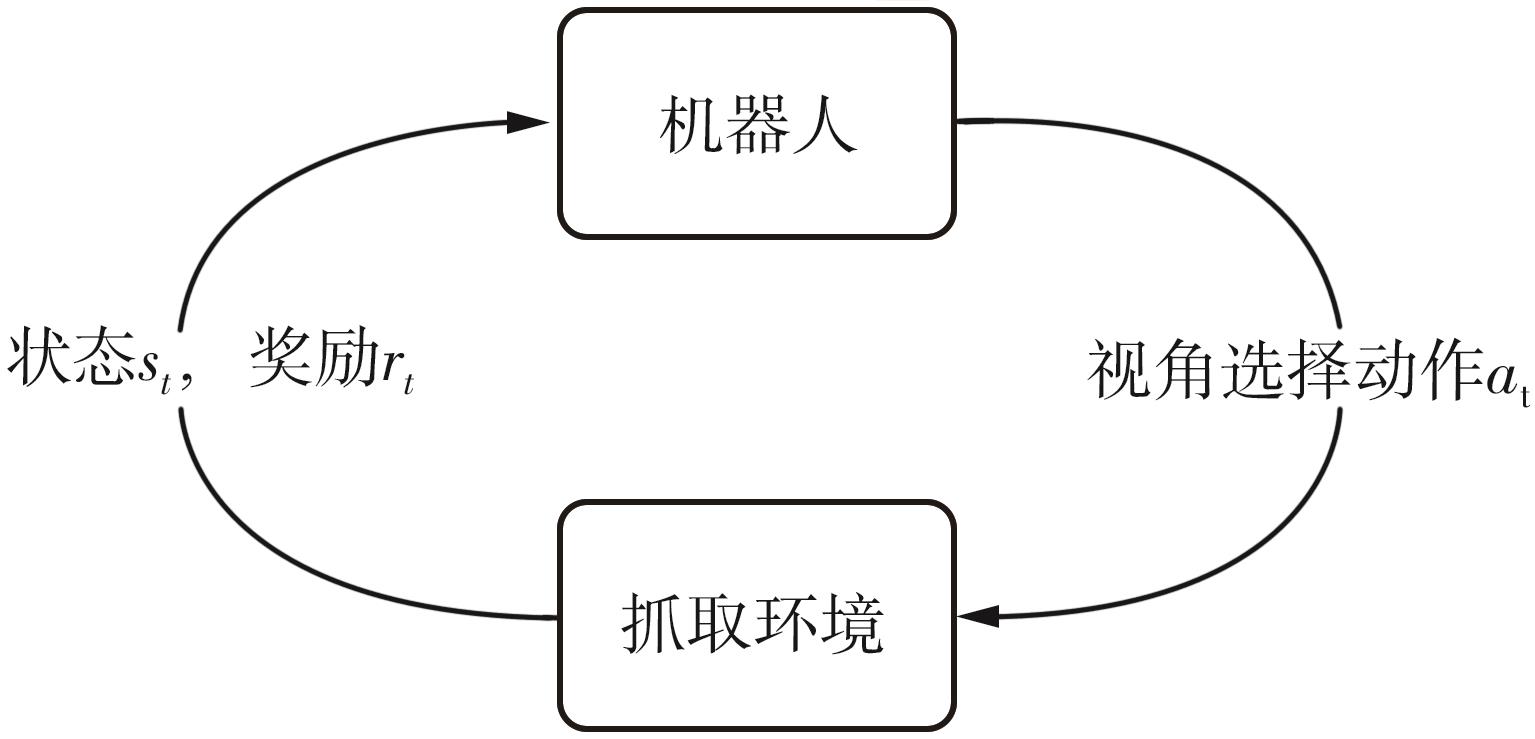
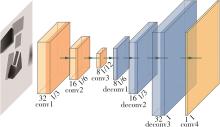
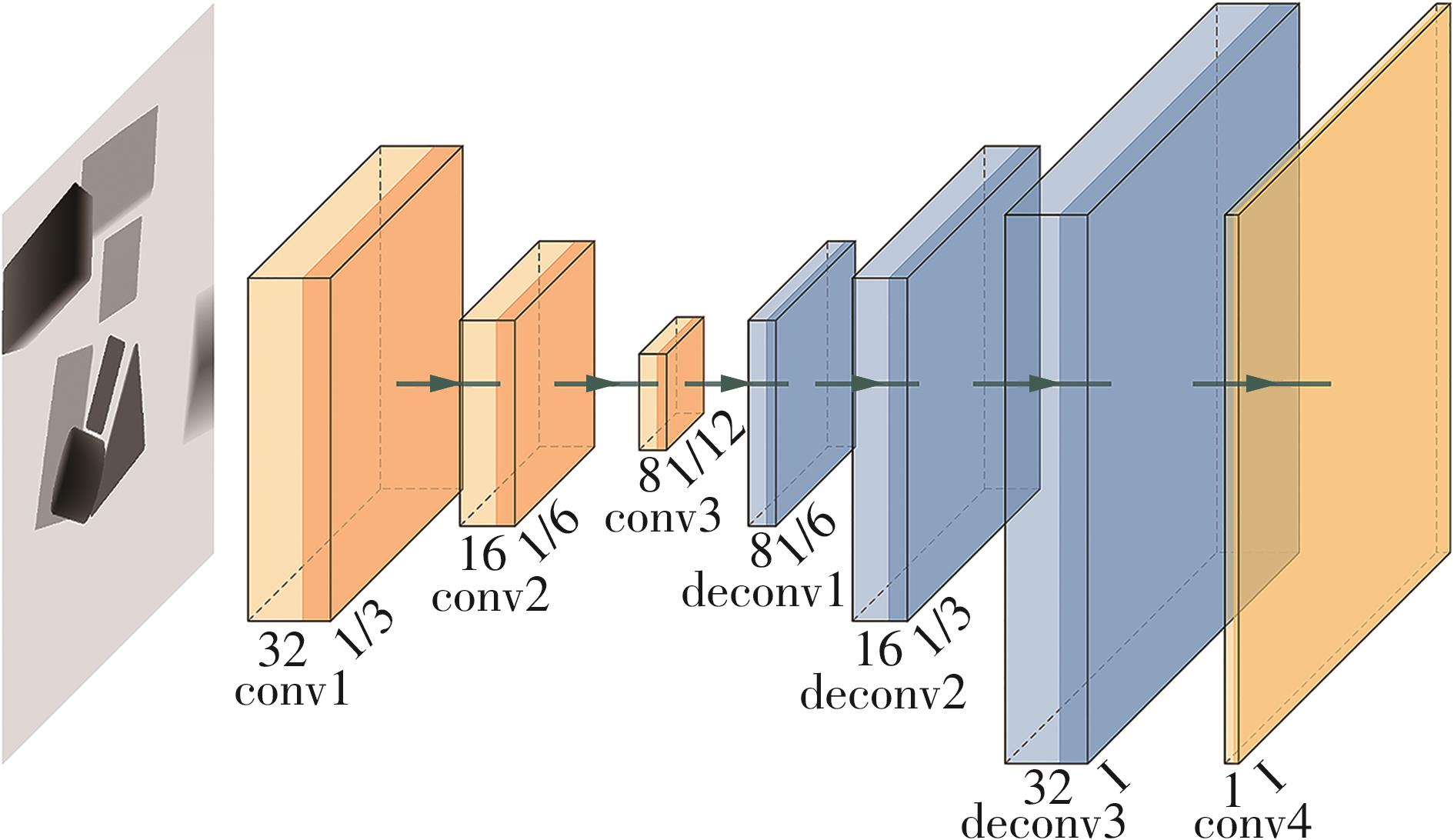
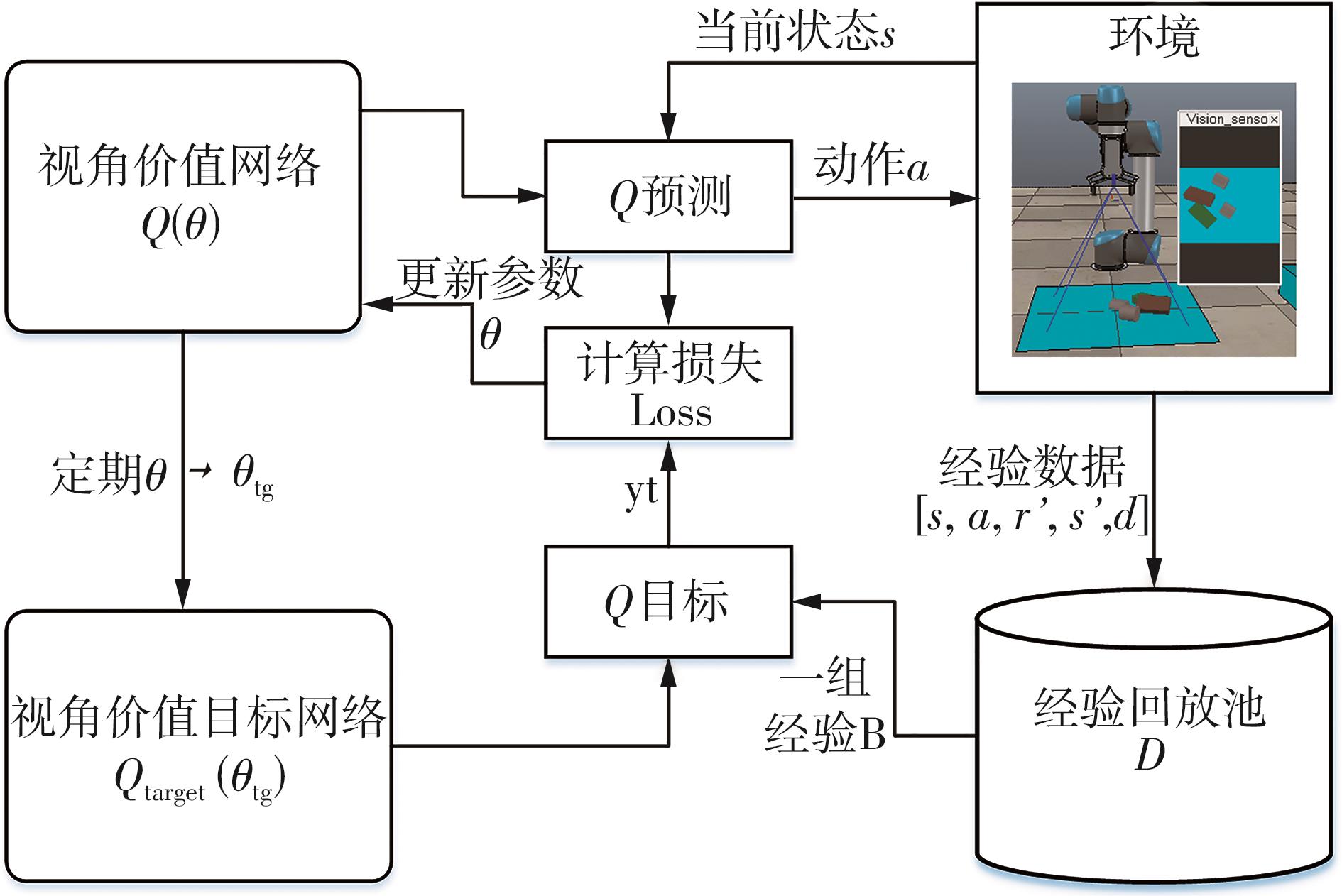
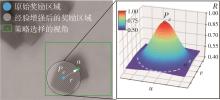
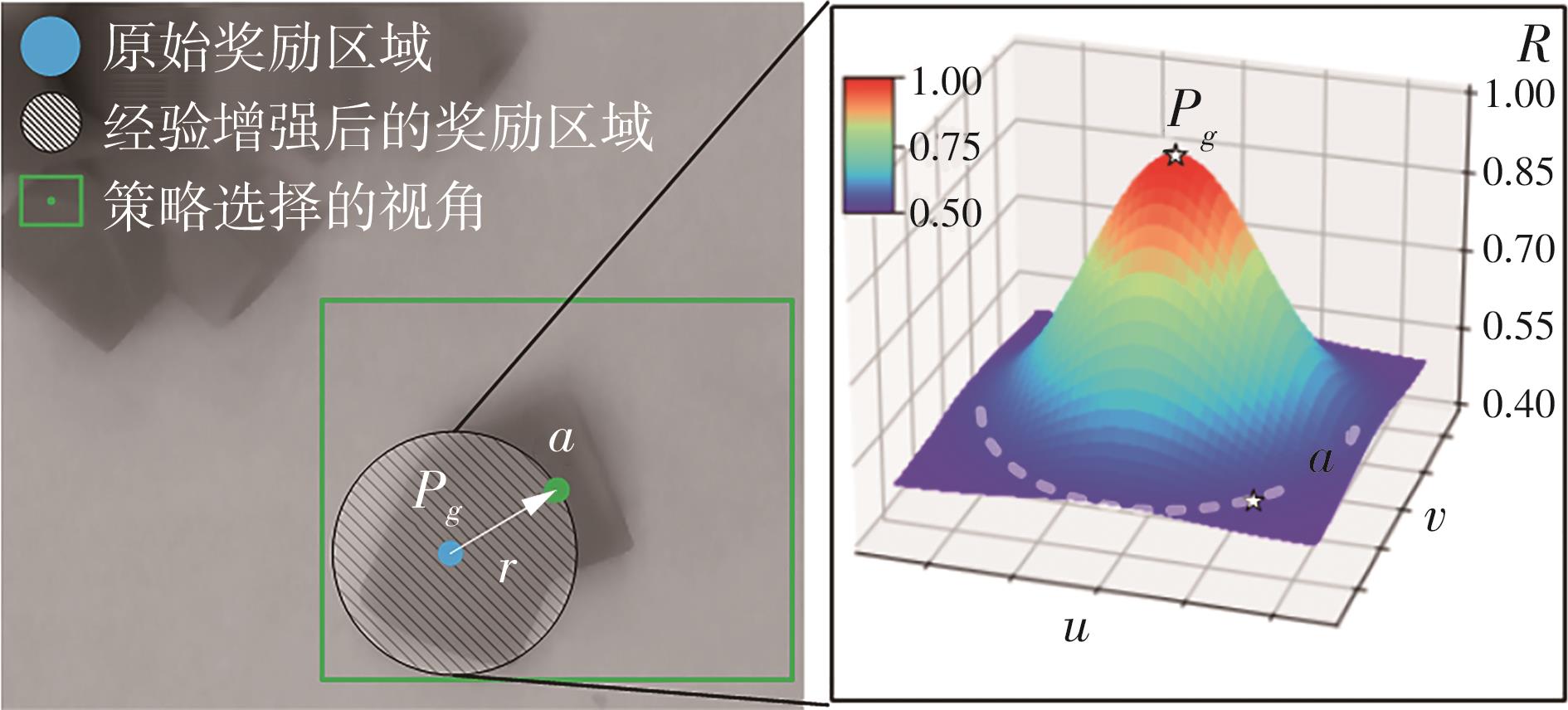
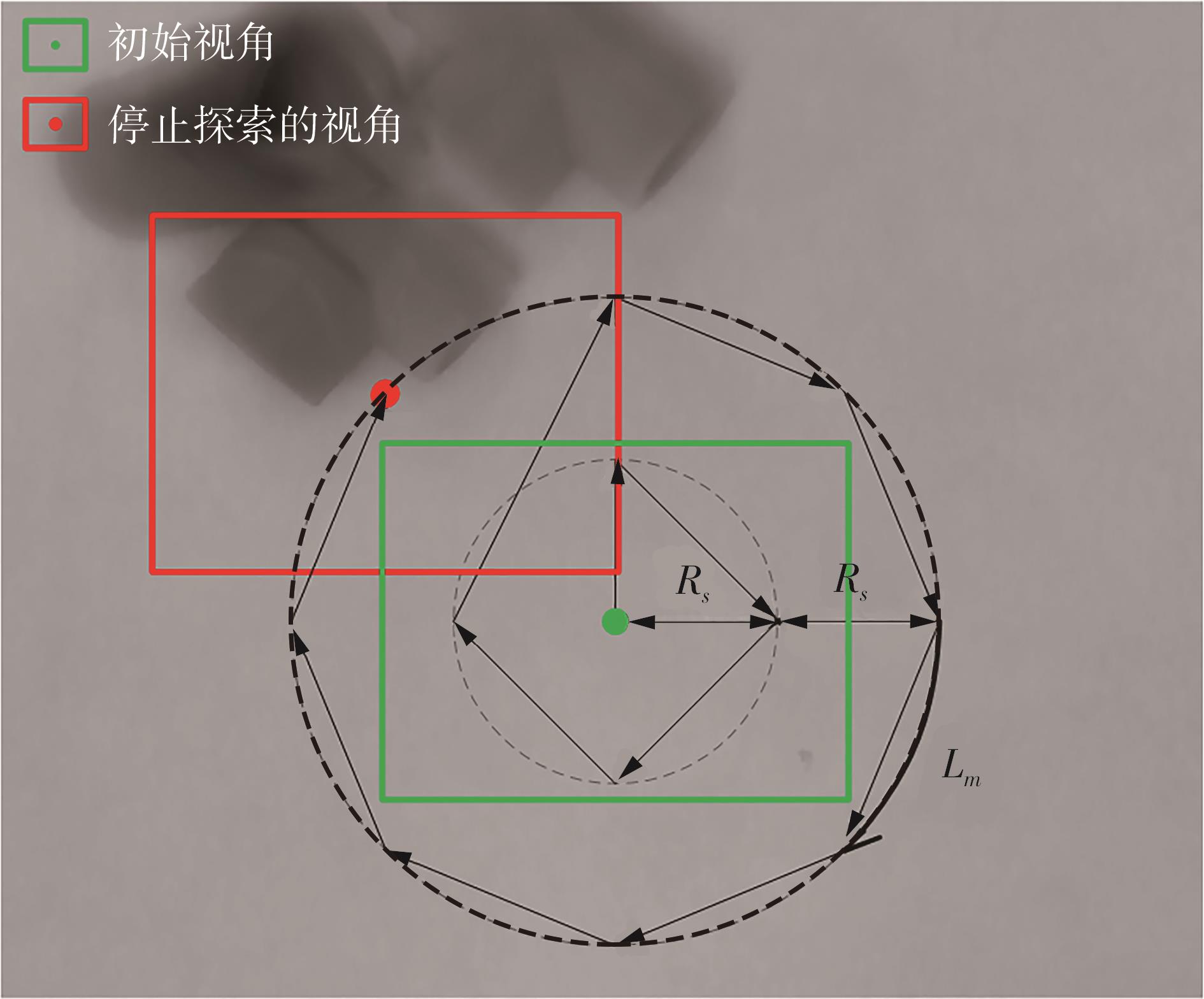
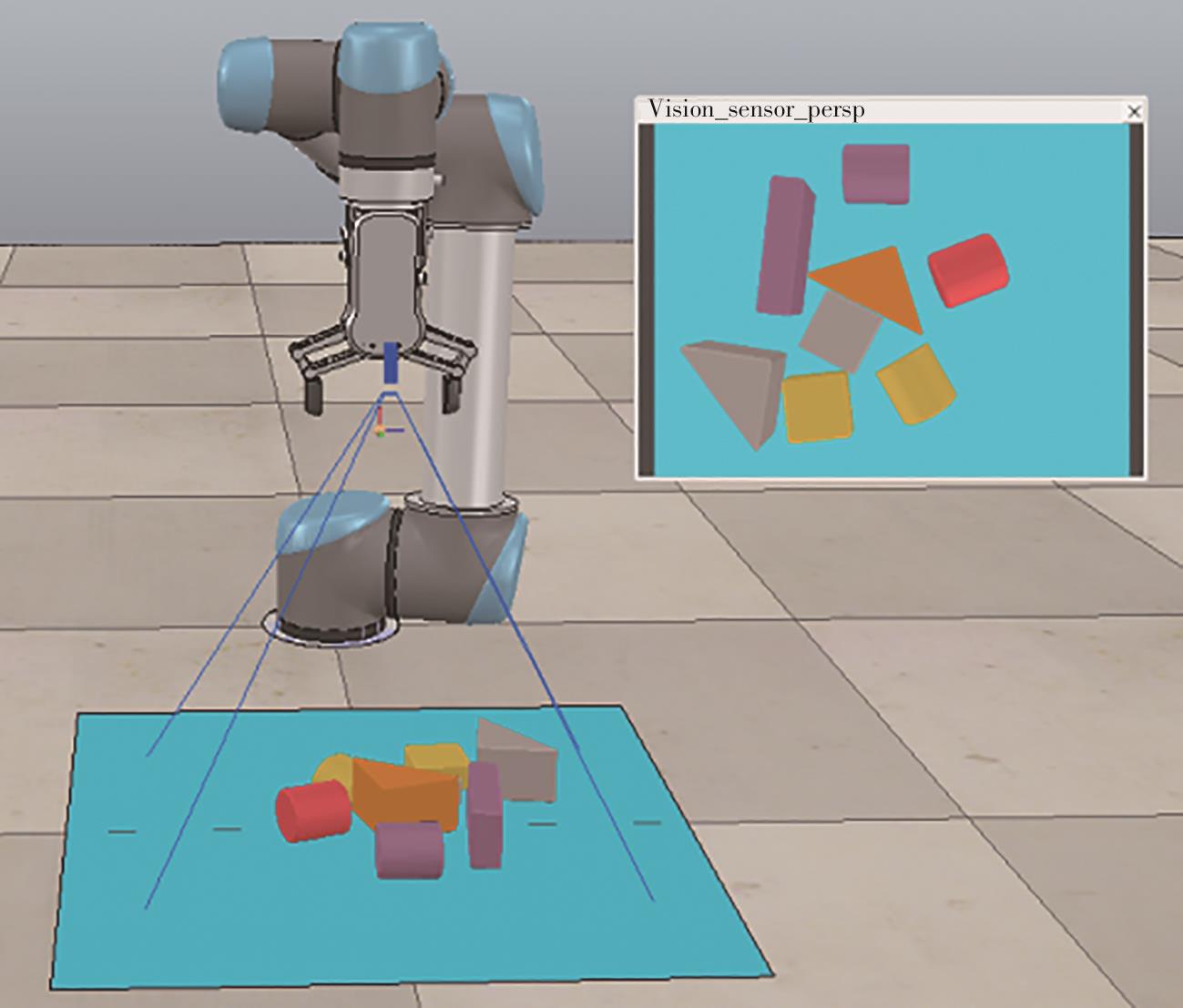
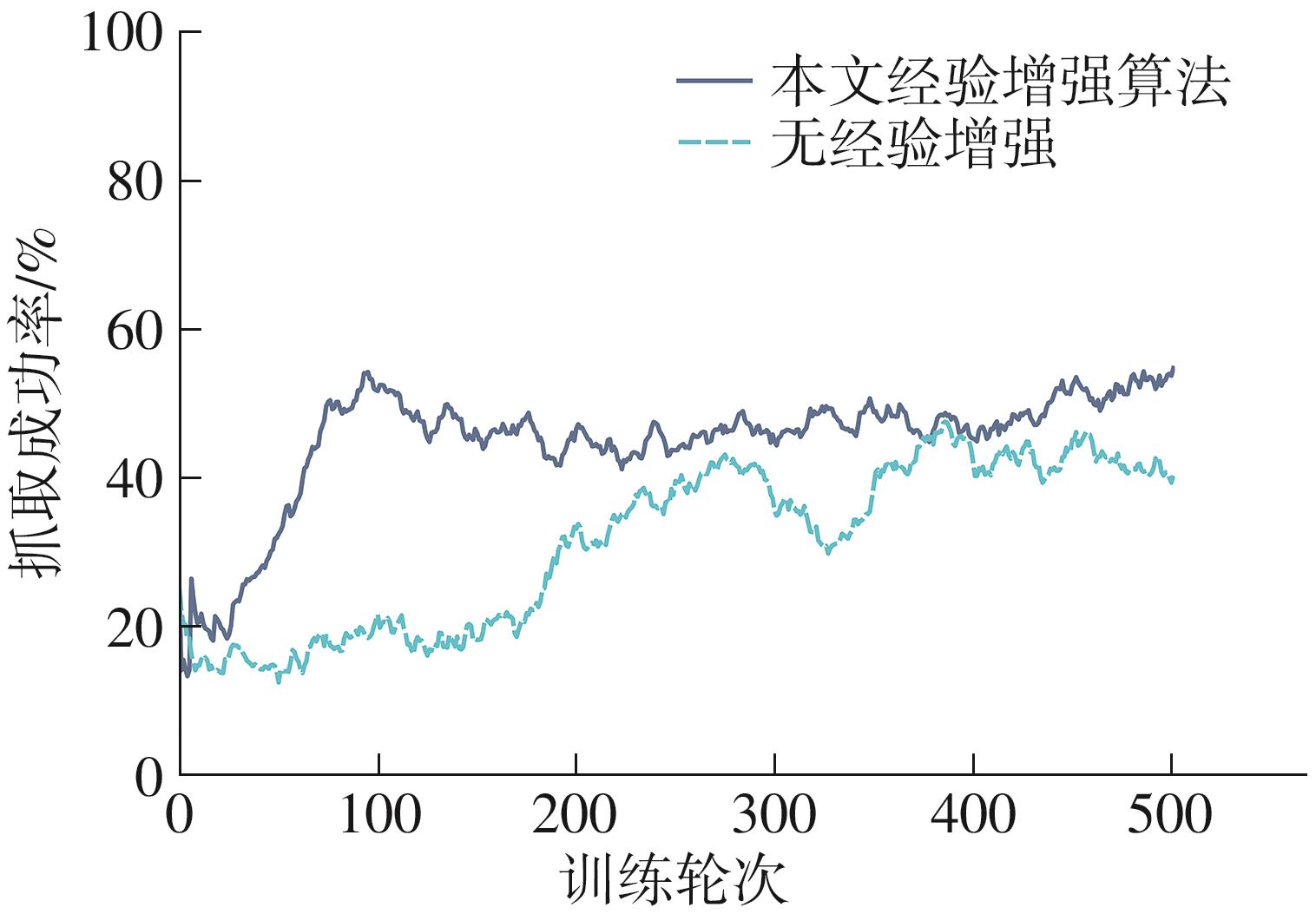
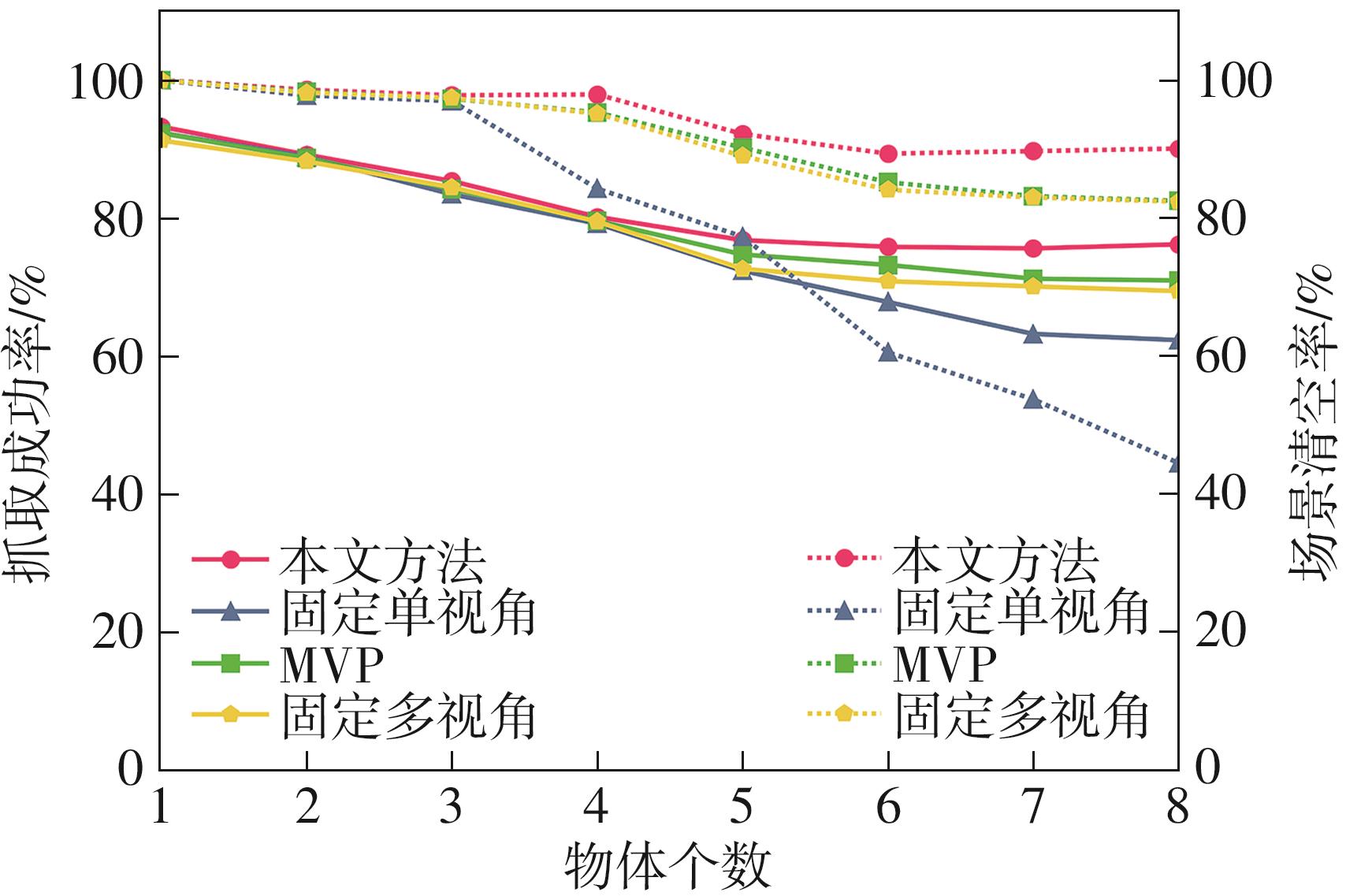
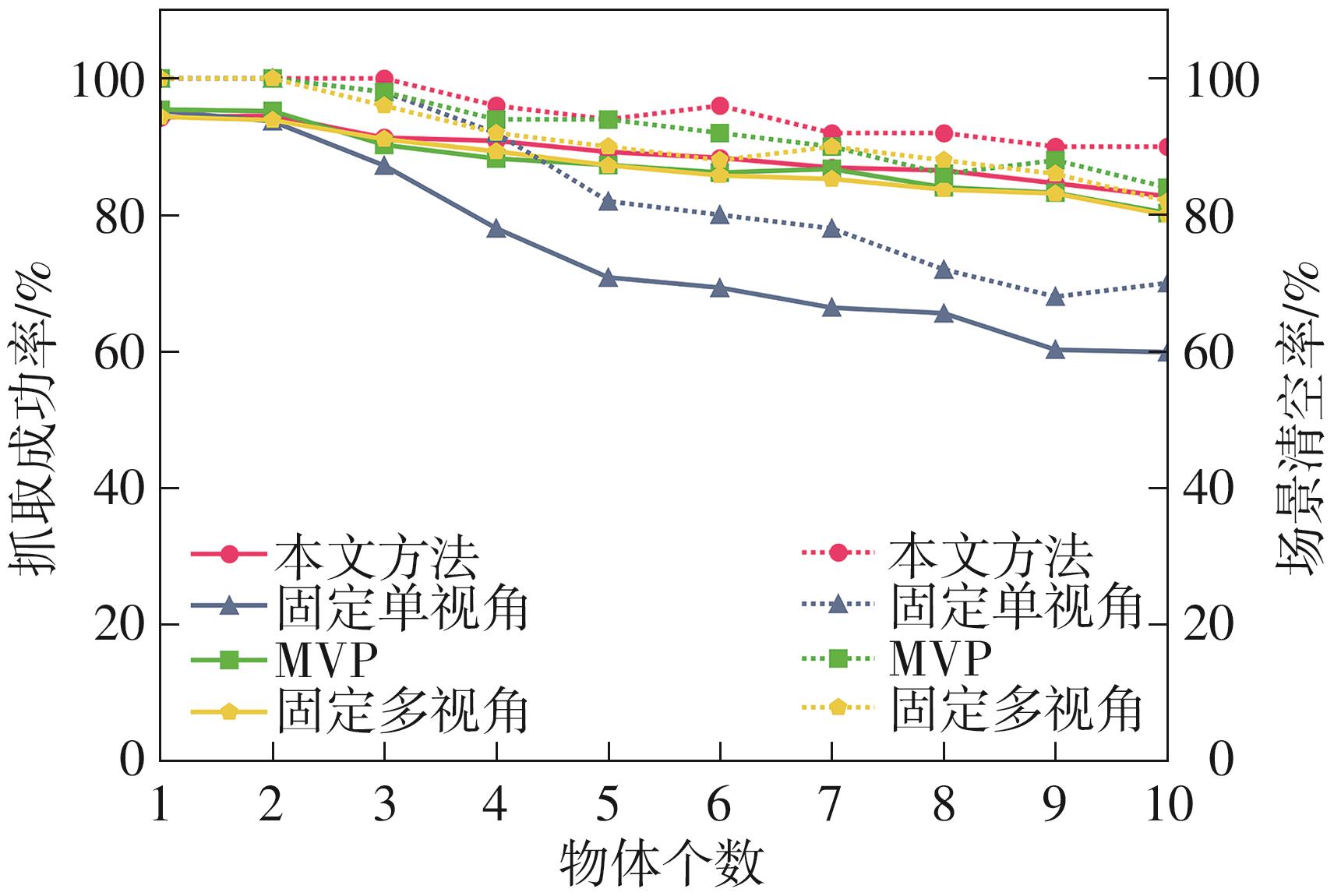
针对混杂物体散乱堆叠下的机器人抓取场景,使用固定视角相机的视觉抓取存在成功率低的问题,提出一种基于深度强化学习框架的眼-手随动相机视角选择策略,令机器人能够自主地学习如何选择合适的末端相机位姿,以提高机器人视觉抓取的准确率和速度。首先,面向机器人主动视觉抓取任务建立马尔科夫决策过程模型,将视角选择问题转化为对视角价值函数的求解问题。使用编码解码器结构的反卷积网络近似视角动作价值函数,并基于深度Q网络框架进行强化学习训练。然后,针对训练过程中存在的稀疏奖励问题,提出一种新的视角经验增强算法,分别对抓取成功和抓取失败的过程设计不同的增强方式,将奖励区域从单一点拓展到圆形区域,提高了视角动作价值函数近似网络的收敛速度。先期实验部署在仿真平台中,通过搭建机器人模型及仿真抓取环境实施离线强化学习训练。过程中,使用提出的视角经验增强算法可以有效提高样本利用率,加快训练的收敛速度。基于所提出的视角经验增强算法,视角动作价值函数近似网络在2 h以内可达到收敛。为验证所提视角选择策略的实际应用效果,将视角经验增强算法实施在真实场景下的机器人主动视觉抓取实验中。实验结果表明,采用该策略进行的视角优化有效提高了机器人的抓取准确率和抓取速度。相较其他方法,所提出的视角选择策略在实际机器人抓取中只需进行一次视角选择即可获得抓取成功率高的区域,进一步提高了最佳视角选择的处理效率。相对于单视角方法,混杂场景的抓取成功率提升22.8%,每小时平均抓取个数达到294个,具备了进入工业应用的可行性。
中图分类号: